Clear Sky Science · sv
Vikten av funktionsteknik över arkitektonisk komplexitet för prognoser av intermittent efterfrågan
Varför det är viktigt att förutsäga sällsynta försäljningar
Bakom varje bilverkstad eller reservdelslager ligger en tyst gåta: hur många långsamt rullande reservdelar bör stå på hyllan? Dessa artiklar säljer sällan och oförutsägbart, men måste finnas tillgängliga när ett fordon går sönder. Överbeställ och kapital binds i dammiga lager; underbeställ och kunder får vänta medan delar hastas fram. Den här artikeln tar sig an det vardagliga men kostsamma problemet genom att ställa en enkel fråga: är det bättre att använda allt mer komplicerade prediktionsmodeller, eller att mata befintliga modeller med smartare, omsorgsfullt utformade signaler från datan?
Från långa perioder av ingenting till plötsliga toppar
I många leveranskedjor, särskilt för fordonsreservdelar, är efterfrågan inte jämn som mjölk eller bröd. Istället förekommer långa perioder på flera månader med nollförsäljning, avbrutna av plötsliga beställningar på några enheter. Författarna analyserar mer än 56 000 kombinationer av återförsäljare och artiklar, omfattande cirka 1,4 miljoner månatliga observationer, och finner att de flesta serier är extremt glesa: i genomsnitt är det många nollmånader för varje månad med försäljning, och orderstorlekarna varierar kraftigt. Traditionella statistiska metoder som Crostons metod och dess förfiningar byggdes för denna typ av "på/av"-efterfrågan och ger stabila, tolkbara prognoser, men de behandlar varje artikel isolerat och kan inte lätt använda extra information som pris eller produktattribut. Moderna maskininlärningssystem kan i princip utnyttja all sådan information, men de har ofta svårt när datan till största delen består av nollor och endast ibland är informativ.
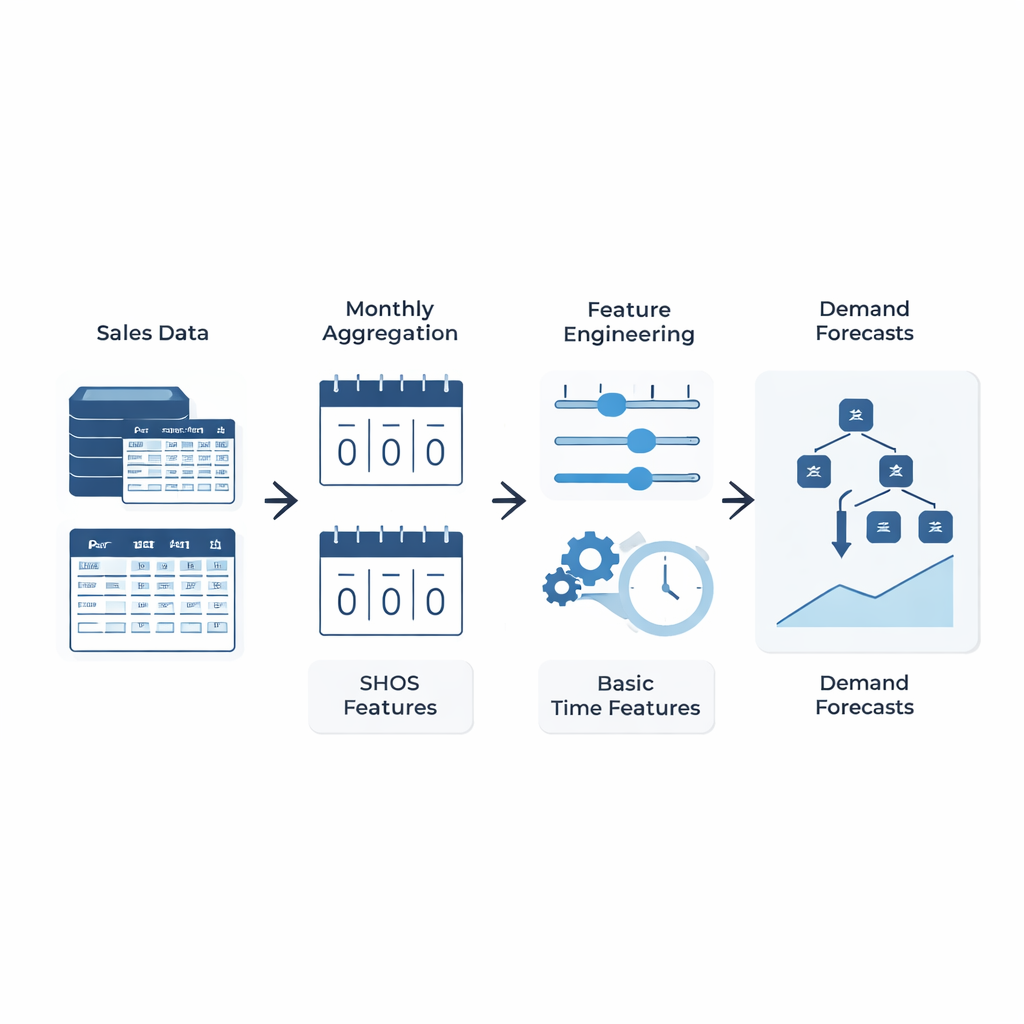
En enkel idé: lär modellen vad som verkligen betyder något
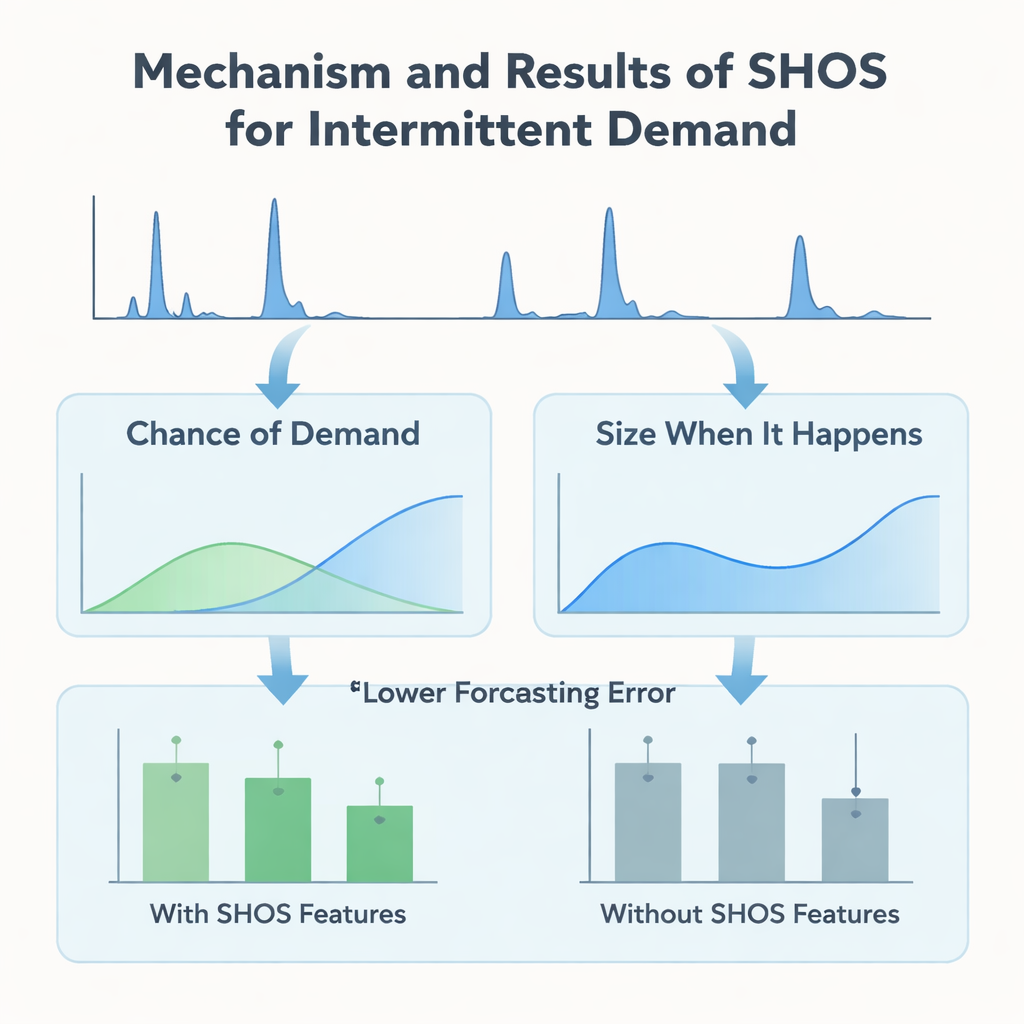
I stället för att utforma allt mer intrikata maskininlärningsarkitekturer fokuserar författarna på vad som matas in i modellen. De introducerar Smoothed Hybrid Occurrence–Size (SHOS)-ramverket, en lättviktsstatistisk rutin som körs över varje efterfrågehistoria. Vid varje månad producerar SHOS två tal: den uppskattade sannolikheten att någon efterfrågan kommer att uppstå nästa månad, och den typiska storleken på den efterfrågan om den gör det. Det görs genom att varsamt utjämna tidigare nollor och icke-nollor, anpassa sitt beteende för mycket glesa serier och reagera snabbare när efterfrågan plötsligt återkommer efter en lång torka. Avgörande är att SHOS inte är den slutliga prognosmodellen. Dess utdata blir extra indatafunktioner för standardiserade maskininlärningsalgoritmer, tillsammans med enkla element som senaste försäljning, glidande medelvärden och statiska produktdetaljer.
Att prioritera funktionernas kvalitet framför modellkomplexitet
För att testa om denna statistiska "förbehandling" verkligen hjälper bygger forskarna ett kontrollerat experiment. De jämför ett antal populära modeller—gradientboostade träd, random forests och linjära metoder—med och utan SHOS-funktioner, alla tränade på samma nollutfyllda månatliga panel och utvärderade med ett rigoröst rullande fönster-schema som efterliknar verklig driftsättning. De testar också mer invecklade tvåstegs "hurdle"-modeller som separat förutser om efterfrågan kommer att uppstå och hur stor den blir. Över 11 valideringsfönster halverar tillägget av SHOS-funktioner i genomsnitt prognosfelet för starkt intermittenta artiklar och sänker en viktig affärsmetrik, viktad medelabsolut procentuell felmarginal, med över 40 %. Överraskande nog presterar inte de tvåstegade arkitekturerna, trots att de är mer komplexa och skräddarsydda för denna typ av data, bättre än en enda, enkel regressormodell som helt enkelt tar in SHOS-signalerna.
Att se hur modellen fattar sina val
Teamet går bortom rubrikprecision och undersöker hur modellerna faktiskt använder den information de får. Med hjälp av SHAP, ett standardverktyg för tolkning av maskininlärningsprediktioner, visar de att SHOS-baserade funktioner—"sannolikhet för efterfrågan" och "storlek när den inträffar"—konsekvent rankas bland de mest inflytelserika indata. Under långa perioder med noll efterfrågan trycker en låg SHOS-sannolikhet prognoserna mot noll och förhindrar oönskad lageruppbyggnad. När ett efterfrågeutbrott uppstår efter en torrperiod höjer en aktualitetsjustering i SHOS snabbt sannolikhets- och storleksuppskattningarna, vilket gör att modellen kan reagera utan att överreagera på en enstaka topp. Dessa beteenden ses både i den enkla enkelstegsmodellen och i de mer komplexa hurdle-varianterna, vilket understryker att den största vinsten kommer från kvaliteten på signalerna, inte arkitektoniska trick.
Vad detta betyder för vardagliga lagerbeslut
För praktiker som försöker hålla rätt delar på hyllan är budskapet både praktiskt och lugnande. Studien visar att omsorgsfullt utformade, statistiskt grundade funktioner kan ge stora förbättringar i att prognostisera sällsynta, oregelbundna försäljningar utan att behöva förlita sig på sköra, svårunderhållna modelluppsättningar. Ett modest, väljusterat gradientboostat träd utrustat med SHOS-funktioner slår eller matchar mer invecklade pipeliner samtidigt som det är enklare att driftsätta och övervaka över tiotusentals artiklar. Enkelt uttryckt kan det vara viktigare att mata ditt prognossystem med bättre sammanfattningar av hur ofta och hur mycket kunder sannolikt beställer än att uppgradera till den senaste, mest komplexa algoritmen. Denna betoning på enkla, tolkbara byggstenar gör tillvägagångssättet attraktivt för storskaliga, verkliga leveranskedjor och antyder att liknande funktionscentrerade strategier kan löna sig i andra branscher som står inför intermittent efterfrågan.
Citering: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Nyckelord: intermittent efterfrågan, prognoser för reservdelar, funktionsteknik, analys av leveranskedjan, maskininlärning