Clear Sky Science · sv
En ny metod för dynamisk uppgiftsschemaläggning för IoT i fog‑molnmiljö
Varför dina smarta enheter behöver smartare hjälp
Från pulsmätare och hemmakameror till självkörande bilar och fabrikrobotar — moderna prylar strömmar konstant data som måste bearbetas inom bråkdelar av en sekund. Att skicka allt till avlägsna molndatacenter är ofta för långsamt och slösaktigt. Denna artikel presenterar ett nytt sätt att avgöra, i varje ögonblick, var alla dessa små digitala jobb bör köras så att systemen förblir snabba, energieffektiva och prisvärda — även när tusentals enheter konkurrerar om uppmärksamhet.
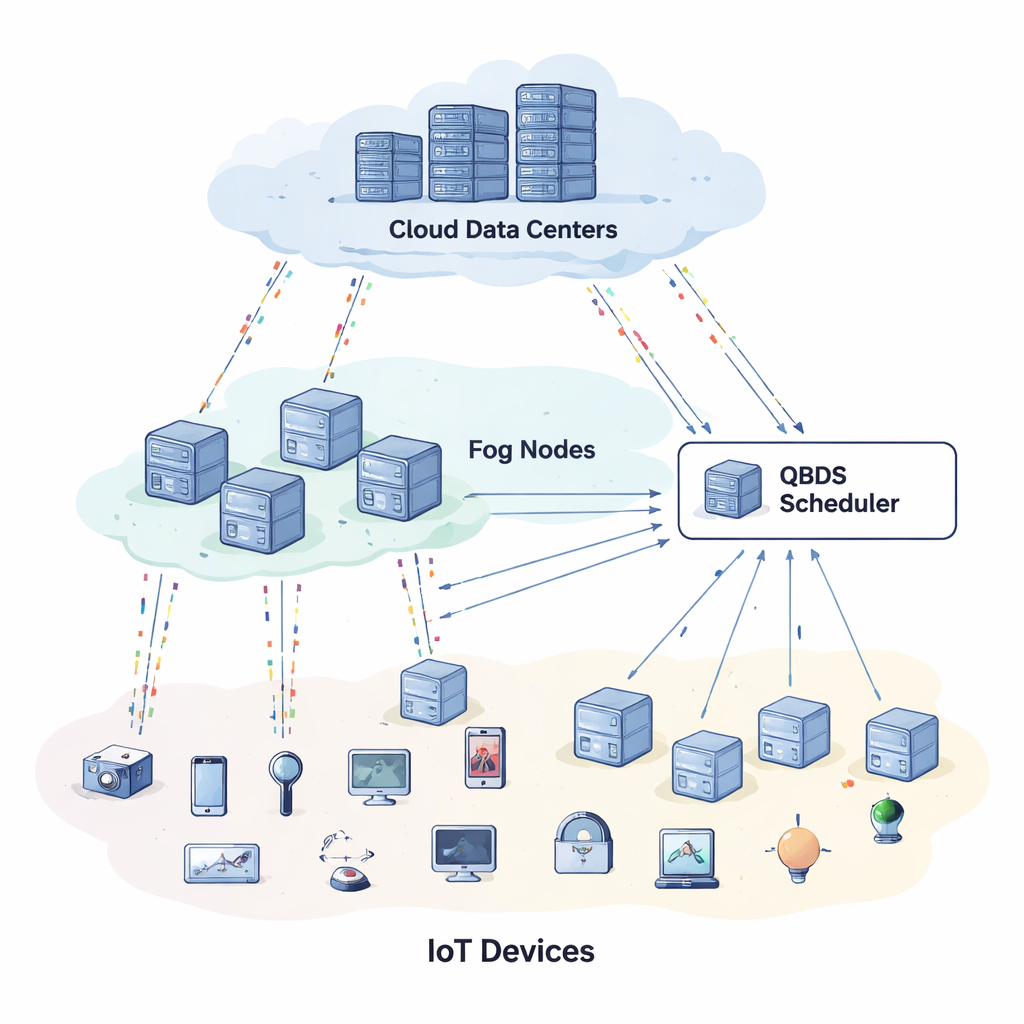
Från molnet till närliggande fog
Traditionell molnberäkning fungerar bra för att lagra foton eller köra storskaliga dataanalyser, men den har svårt med livsavgörande eller splitternssekundära scenarier, som fjärrkirurgi, smarta trafikljus eller autonoma drönare. Fördröjningen som uppstår när data skickas över internet och väntar i köer kan vara oacceptabel. För att lösa detta införde ingenjörer ett extra mellanskikt kallat "fog"‑beräkning: små servrar och gateway‑enheter placerade närmare där datan genereras. I en trelagersuppsättning — enheter, fog och moln — bör lätta, brådskande uppgifter stanna nära kanten, medan tyngre, mindre tidskritiska jobb kan flyttas till molnet. Problemet är att dessa lager innehåller en blandning av maskiner med olika hastigheter, minnesstorlekar, nätlänkar, energiförbrukning och priser, som alla förändras över tiden. Att effektivt avgöra vem som gör vad och när blir ett svårt pussel.
En trafikledare för digitala jobb
Författarna föreslår en ny trafikledare för detta pussel, kallad Quantum‑inspirerad Biased Dynamic Scheduler (QBDS). Tänk på varje meddelande från en sensor eller app som en uppgift som måste tilldelas någon fog‑ eller molnknut. QBDS rangordnar först alla väntande uppgifter utifrån hur brådskande och krävande de är — med hänsyn till deras deadlines, hur länge de kommer att köras, hur mycket minne de behöver och hur mycket data som måste flyttas. Detta förhindrar att små men akuta uppgifter begravs av stora men mindre kritiska. För varje möjlig matchning mellan en uppgift och en maskin uppskattar QBDS sedan hur lång tid uppgiften skulle ta, hur mycket energi maskinen skulle förbruka och hur mycket operatören skulle behöva betala i användningsavgifter eller böter för missade deadlines. Alla dessa ingredienser kombineras till en flexibel poäng som systemoperatörer kan justera beroende på om de bryr sig mest om hastighet, kostnad eller energibesparing.
Lånar en idé från vågor, inte kvantmaskinvara
Det som får QBDS att sticka ut är en subtil "kvant‑inspirerad" twist. Istället för att använda riktiga kvantdatorer lånar metoden idén om vågliknande beteende för att förbättra sökningen efter bra uppgifts‑maskin‑par. För varje par bygger schemaläggaren flera enkla mått: hur väl uppgiftens storlek matchar en maskins processor och minne, hur lämplig nätlänken är, hur billig maskinen är och hur kort dess kommunikationsfördröjning blir. Dessa mått transformeras med hjälp av mjuka sinusvågor och blandas sedan med slumpmässiga vikter. Den resulterande biasen böjer något den övergripande kostnadspoängen så att schemaläggaren pushas bort från överbelastade maskiner och mot kapabla men underanvända sådana. Avgörande är att denna modulering är noggrant begränsad så att den aldrig överväldigar de grundläggande målen att slutföra uppgifter i tid och inom budget. Tillvägagångssättet förblir helt klassiskt — det omformar bara "kostnadslandskapet" på ett kontrollerat, våg‑liknande sätt för att undvika att fastna i mediokra val.
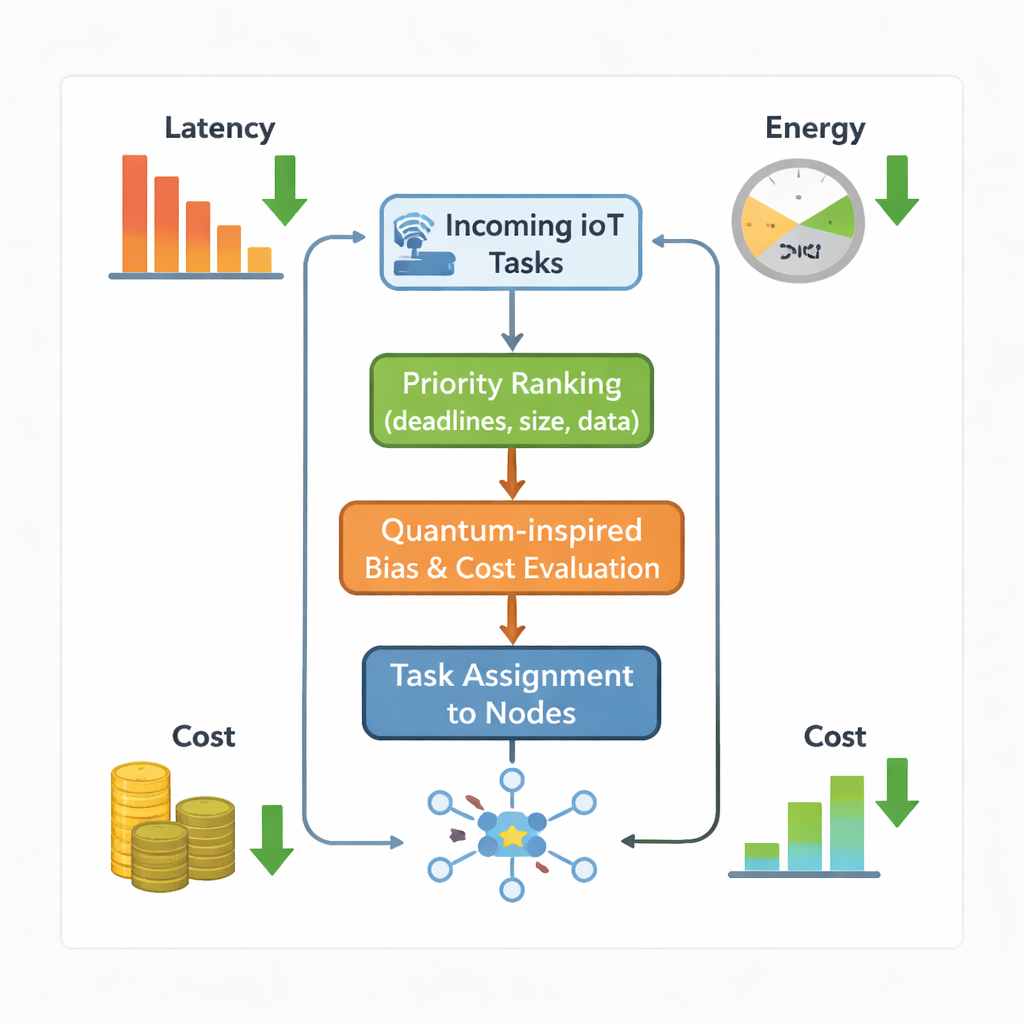
Test av den nya schemaläggaren
För att se om idén fungerar i praktiken körde forskarna omfattande datorexperiment som simulerar från tusentals till tiotusentals uppgifter som anländer till blandade fog‑molnsystem. De jämförde först QBDS med en version av sig själv som saknar den kvant‑inspirerade biasen. Med bias aktiverad slutförde systemet alla uppgifter ungefär en fjärdedel snabbare, använde nästan en femtedel mindre energi, spenderade mindre pengar totalt och fördelade arbetet mycket jämnare över maskiner. Därefter ställde de QBDS mot en rad avancerade optimeringsscheman, inklusive moderna metaheuristiker, maskininlärningsbaserade schemaläggare och klassiska regler som "först till kvarn" eller "kortaste jobb först." I både små och stora miljöer gav QBDS konsekvent kortare slutförandetider, bättre genomströmning, färre missade deadlines och bättre lastbalansering — ofta samtidigt som den körde mycket snabbare än populationsbaserade sökmetoder som kräver många iterationer.
Vad detta innebär för vardagsteknik
För en icke‑specialist är huvudbudskapet att smartare, mer flexibel schemaläggning kan göra uppkopplade system både rappare och grönare. Genom att rangordna uppgifter intelligent och tillföra en försiktig, våginspirerad skjuts mot underanvända maskiner håller QBDS data närmare där de behövs, minskar slöseri med energi och minskar risken för farliga förseningar. Även om arbetet hittills har demonstrerats i simuleringar snarare än på verklig hårdvara, pekar det mot framtida fog‑molnplattformar som kan jonglera tusentals realtidsjobb — från medicinsk övervakning till smarta städer — utan att kräva exotiska kvantdatorer eller massiv extra datorkraft.
Citering: Mindil, A., Hamed, A.Y., Hassan, M.R. et al. A novel approach for dynamic task scheduling for IOT in fog-cloud environment. Sci Rep 16, 5501 (2026). https://doi.org/10.1038/s41598-026-35156-7
Nyckelord: fog‑beräkning, IoT‑uppgiftsschemaläggning, kant och moln, energieffektiv beräkning, realtidssystem