Clear Sky Science · sv
Domänanpassad Faster R-CNN för identifiering av icke‑PPE på byggarbetsplatser från kroppsburna och allmänna bilder
Varför saknad skyddsutrustning ändå slinker igenom
Hjälmar, västar, masker, handskar och stadiga skor ska vara icke‑förhandlingsbara på byggarbetsplatser, men brister uppstår ändå—och de kan vara dödliga. Många projekt förlitar sig nu på kameror och artificiell intelligens för att flagga arbetare som saknar påkrävd utrustning, men dessa system har svårt eftersom verkliga överträdelser är sällsynta och svåra att fånga på film. Denna studie undersöker ett sätt att träna smartare detektionssystem genom att låna exempel från vanliga gatubilder, vilket gör automatiska säkerhetskontroller mer pålitliga utan att behöva vänta på olyckor—eller att överträdelser samlas på hög.
Att göra vardagsbilder till säkerhetslektioner
Huvudidén är enkel: människor på allmänna platser eller kontor bär sällan byggutrustning, så bilder från dessa miljöer är fulla av exempel på "vad man inte ska ha på sig" på en byggarbetsplats. Utmaningen är att dessa scener ser väldigt annorlunda ut än verkligt byggarbete—bakgrunder, ljusförhållanden och kameravinklar ändrar hur personer framstår. Författaren behandlar dessa två världar som olika "domäner": en source-domän med rikligt med icke‑PPE‑exempel från allmänna bilder, och en target-domän med färre men mer realistiska byggplatsbilder, många filmade från kameror monterade på arbetarnas hjälmar. Artikeln visar att genom att noggrant anpassa vad datorn lär sig från båda domänerna kan systemet upptäcka saknad utrustning på verkliga arbetsplatser betydligt mer precist än om det bara tränats på byggdata.
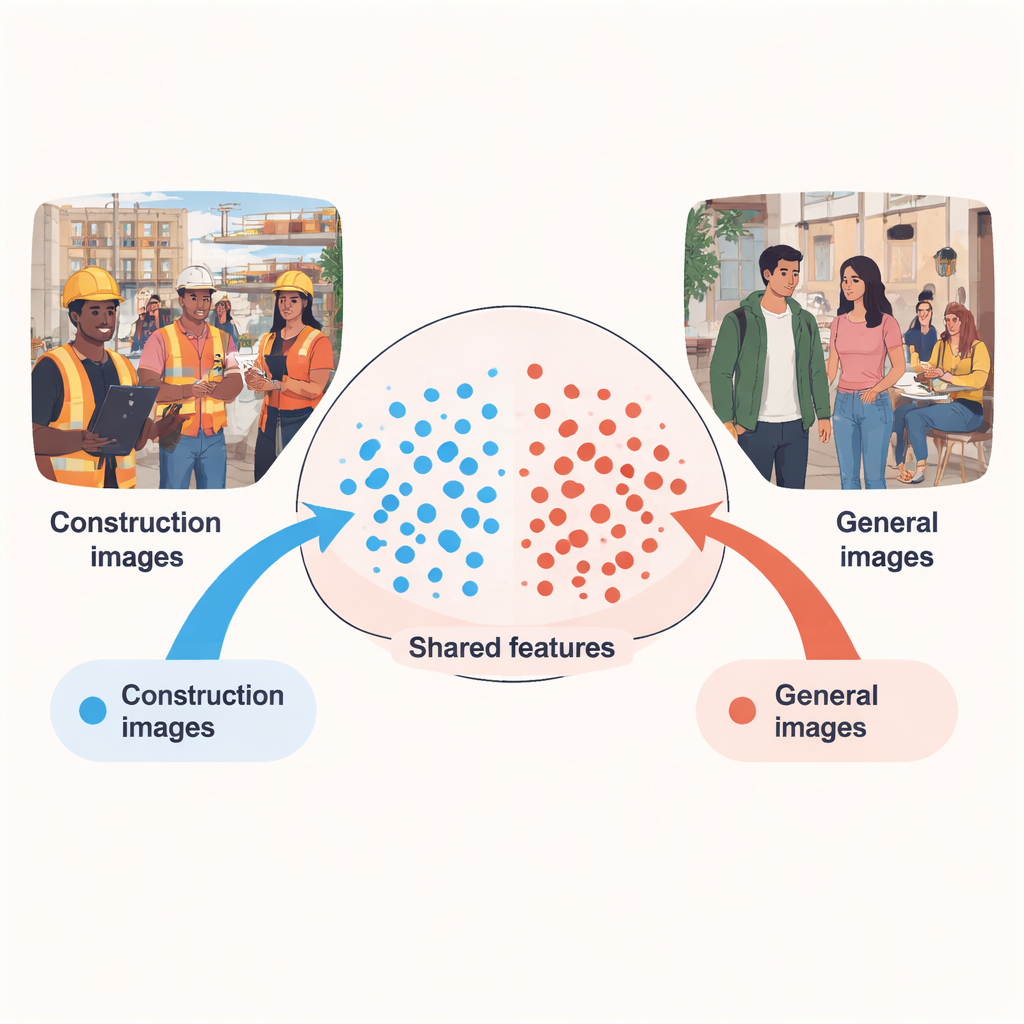
Hur den nya säkerhetskontrollen ser en scen
Forskningen bygger på ett populärt objektidentifieringssystem kallat Faster R‑CNN, som skannar en bild, föreslår regioner som sannolikt innehåller personer eller kroppsdelar, och sedan klassificerar vad den ser i varje ruta. Här tränas detektorn att känna igen fem typer av saknad utrustning: ingen hjälm, ingen mask, inga handskar, ingen väst och inga skyddsskor. Innan bilder matas in i modellen förstärks de kraftigt—ljusare eller mörkare, roterade, suddiga och förvrängda—för att efterlikna skakiga kameror, hårt solsken och konstiga vinklar som är vanliga på livliga arbetsplatser. Denna syntetiska variation hjälper modellen att vara stabil när verkligt material är mindre än perfekt, som det ofta är vid inspelning från kroppsburna kameror.
Att lära systemet att ignorera bakgrunden
Att bara blanda gatubilder med byggbilder räcker inte; modellen kan lära sig att associera saknad utrustning med stadsgator istället för med personer. För att förhindra det introducerar studien "domänanpassnings"-moduler som mjukt pressar systemet att fokusera på personer och kläder snarare än miljön runt dem. En modul ser på bilden som helhet och knuffar nätverket så att bygg‑ och icke‑byggbilder ger liknande övergripande mönster trots olika ljus eller utrustning. En annan arbetar på nivån för varje detekterad person och ser till att den visuella signaturen för exempelvis ett o- skyddat huvud ser liknande ut oavsett om det dyker upp på ett byggställning eller i en shoppinggata. Dessa moduler tränas på ett adversariellt sätt: en liten klassificerare försöker avgöra vilken domän en bild kommer ifrån, medan huvuddelen av nätverket lär sig dölja den informationen och hålla fokus på skyddsutrustningen istället.
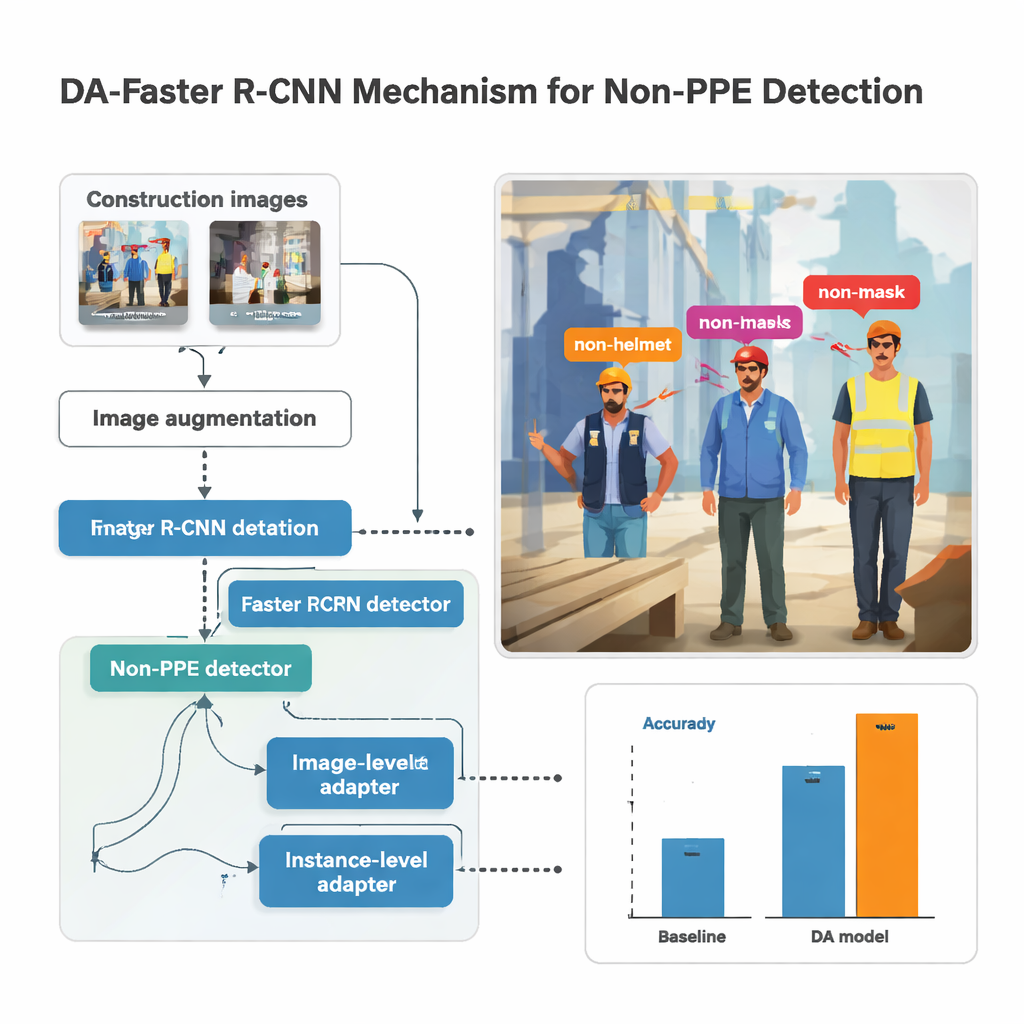
Sätta metoden på prov
Författaren samlade en omfattande dataset genom att kombinera kroppsburen kamerafilm från fem byggarbetsplatser i Sydkorea med flera publika bildsamlingar. Efter manuell märkning av varje instans av saknade hjälmar, masker, handskar, västar och skyddsskor tränade studien hundratals modeller med olika neurala nätverksbackbones och parameterinställningar. Bäst presterade en djup nätverksarkitektur kallad ResNet‑152 tillsammans med kraftig bildaugmentering och domänanpassningsmodulerna. På tidigare osedda byggbilder nådde denna uppsättning ett medelvärde för Average Precision—en övergripande poäng för detektionskvalitet—på cirka 86,8 procent, samtidigt som den fortfarande körde ungefär 33 bildrutor per sekund, tillräckligt snabbt för nära realtidsövervakning. Jämfört med mer konventionella övervakade system förbättrade den anpassade modellen noggrannheten med upp till 14 procentenheter, och med så mycket som 39 punkter över en enklare baseline.
Vad detta innebär för säkrare arbetsplatser
För icke‑specialister är slutsatsen att smartare träning, inte bara större dataset, kan göra automatiserad säkerhetsövervakning mycket mer pålitlig. Genom att lära sig från både vardagsbilder och verkliga arbetsplatser, och genom att lära systemet att ignorera oviktiga bakgrundsdetaljer, hittar den föreslagna metoden saknade hjälmar, västar, handskar, masker och skyddsskor med hög tillförlitlighet, även när verkliga överträdelser är sällsynta. Medan det aktuella arbetet fokuserar på fem typer av utrustning och ett huvuddataset för byggplatser, erbjuder det en praktisk ritning för framtida system som skulle kunna övervaka selar, rep och annan säkerhetsutrustning över många platser, hjälpa tillsynspersoner att fånga problem tidigt och hålla arbetare säkrare utan att stirra på video hela dagen.
Citering: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
Nyckelord: arbetsplatsens säkerhet, personlig skyddsutrustning, datorseende, domänanpassning, objektidentifiering