Clear Sky Science · sv
Kompakta djupinlärningsmodeller för kolonhistopatologi med fokus på prestanda och generaliseringsutmaningar
Varför denna forskning är viktig för patienter och läkare
Koloncancer är en av världens dödligaste cancerformer, men diagnos bygger fortfarande på att specialister noggrant granskar mikroskopbilder av vävnad — ett arbete som är tidskrävande och ofta föremål för oenighet. I den här studien undersöks om mycket små, effektiva artificiella intelligens (AI)-modeller kan hjälpa till att markera cancerös kolonsvävnad tillräckligt noggrant för att vara användbara i vardagliga kliniker, även där beräkningsresurserna är begränsade. Studien avslöjar också en dold svaghet: modeller som ser nästan perfekta ut under utveckling kan ändå falla kraftigt på ny, verklig data.
Lära datorer att läsa mikroskopbilder
När en koloni biopsi tas, undersöker patologer tunna, färgade snitt av vävnad i mikroskop. Cancerös vävnad visar förvrängda körtlar, oregelbundna cellformer och invasion i omkringliggande strukturer, medan frisk vävnad uppvisar ordnade, regelbundna mönster. Författarna använde en offentlig samling om 24 000 digitala bilder av sådana snitt, jämnt fördelade mellan cancer (kolonadenokarcinom) och benign vävnad. De ändrade storlek på alla bilder till ett standardiserat litet format och applicerade realistiska variationer — små rotationer, speglingar, zoomar och milda färgförskjutningar — för att efterlikna naturliga skillnader i hur preparat skärs, färgas och skannas. Denna omsorgsfulla förberedelse hjälper AI-modeller att fokusera på meningsfulla vävnadsmönster istället för ytliga detaljer som exakt orientering eller ljusstyrka.
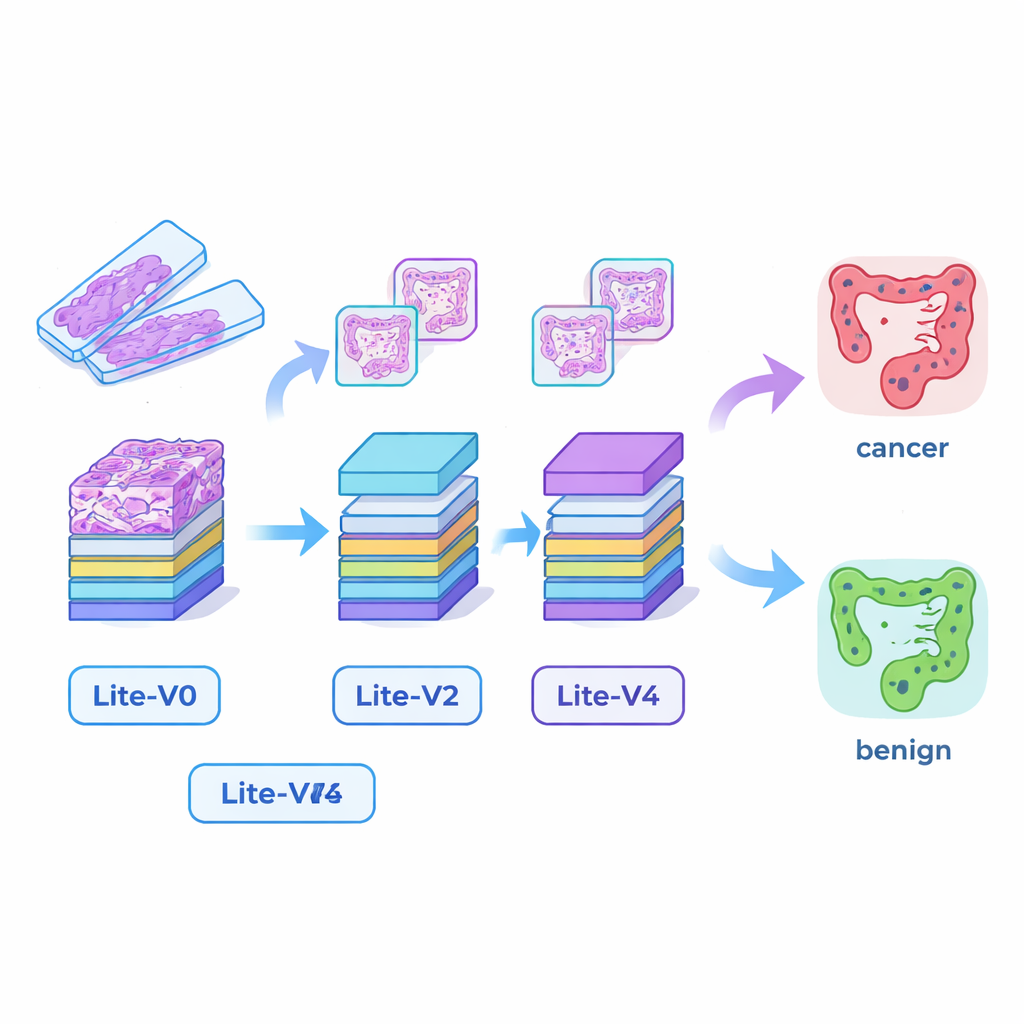
Bygga små men kapabla AI‑”ögon”
Många framgångsrika medicinska AI‑system bygger på mycket stora djupinlärningsmodeller som kräver kraftfulla grafikkort och mycket minne, vilket gör dem svåra att driftsätta i mindre sjukhus eller vid sängkanten. För att överbrygga detta gap designade forskarna fyra kompakta konvolutionella neurala nätverk — Lite‑V0, Lite‑V1, Lite‑V2 och Lite‑V4. Var och en analyserar samma inmatade bildpatchar, men de skiljer sig åt i hur många lager och filter de använder för att upptäcka visuella kännetecken såsom kanter, texturer och körtelmönster. Alla fyra delar en enkel, transparent design: upprepade block av standardkonvolution, normalisering och pooling, följt av ett litet "besluts‑huvud" som ger sannolikheten för cancer eller benign vävnad. Målet var att se hur mycket noggrannhet som går att pressa ut ur modeller som är tillräckligt små för att bekvämt rymmas på enkel klinisk hårdvara.
Imponerande resultat i laboratoriet
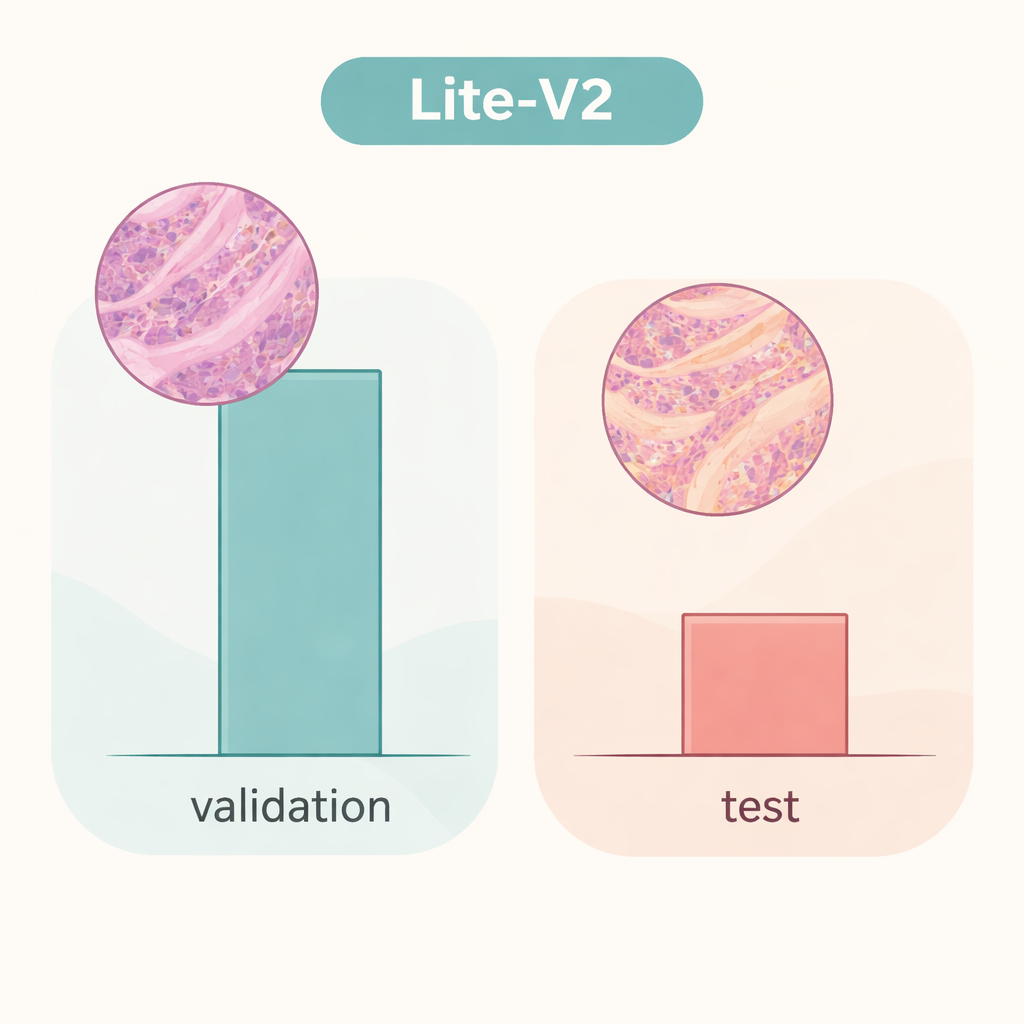
Teamet tränade och jämförde alla fyra modeller på en fast uppdelning av datasetet, med välkända mått: noggrannhet, en balanserad F1‑poäng som väger fel i båda klasser lika, förväxlingsmatriser och diagnostiska diagram som ROC‑ och precision–recall‑kurvor. En medelstor modell, Lite‑V2, framträdde som stjärnan. Trots att den bara var cirka 1,5 megabyte i storlek och hade ungefär 128 000 träningsbara parametrar, uppnådde den nästan felfri prestanda på den interna valideringsuppsättningen, med en makro F1‑poäng runt 0,999 och nästan perfekt sensitivitet och specificitet. Med andra ord, inom denna noggrant förberedda miljö kunde Lite‑V2 nästan alltid skilja cancerös från benign kolonsvävnad, samtidigt som den var tillräckligt snabb och lätt för användning på modest hårdvara.
När verklig variation bryter förtrollningen
Berättelsen förändras dock dramatiskt när samma Lite‑V2‑modell testas på en oberoende uppsättning bilder som skiljer sig subtilt på sätt som efterliknar preparat från ett annat laboratorium — det forskare kallar ett "domänskift". På denna otestade testuppsättning föll den totala noggrannheten till omkring 50 procent och den balanserade F1‑poängen sjönk till ungefär 0,33. Modellen fortsatte att känna igen många cancerprover men hade stora svårigheter med benign vävnad och felklassade en stor andel som malign. Detta visar att nätverket hade lärt sig detaljer som var starkt knutna till den ursprungliga datakällan — såsom färgningsstil eller skanneregenskaper — snarare än robusta, överförbara sjukdomssignaturer. Arbetet betonar att lysande resultat vid intern validering kan ge en falsk trygghet om modeller inte utmanas med verkligt skild data.
Vad detta innebär för framtida AI‑diagnostikverktyg
För en allmän läsare är slutsatsen tvådelad. För det första kan kompakta AI‑system verkligen nå expertliknande prestanda på bilder av kolonvävnad samtidigt som de förblir små och effektiva nog för bred användning, vilket öppnar dörren för snabbare screening och stöd till överbelastade patologer. För det andra — och lika viktigt — kan en modell som ser "perfekt" ut på sitt hemmadata set svikta kraftigt när den möter bilder från ett nytt sjukhus. Författarna menar att framtida arbete måste fokusera på att göra dessa lättviktsmodeller robusta mot förändringar i färgning, skannrar och patientpopulationer — med strategier som färgrobust träning, domänanpassning och bredare multicenter‑dataset. Fram till dess bör AI ses som en lovande assistent snarare än en fristående beslutsfattare i cancerdiagnostik.
Citering: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
Nyckelord: koloncancer, histopatologi, djupinlärning, lättvikts‑CNN, domänskift