Clear Sky Science · sv
Prediktion av rotassocierade proteiner med en stor protein-språkmodell och hypergrafkonvolutionella nätverk
Varför rötter och deras dolda medhjälpare spelar roll
När vi tänker på att hålla grödor friska föreställer vi oss oftast blad och frukter. Men mycket av en växts framgång sker utom synhåll, i marken. Där hjälper speciella rotassocierade proteiner växter att ta upp vatten och näringsämnen och att klara stressfaktorer som torka eller näringsfattig jord. Att hitta dessa avgörande proteiner med laborationer ensam är långsamt och kostsamt. Denna studie presenterar en kraftfull datorbaserad modell, kallad Hypergraph-Root, som snabbt kan skanna proteinsekvenser och förutsäga vilka som sannolikt är rotassocierade, och därmed erbjuda en snabbare väg till tåligare grödor och bättre skördar.
Dolda arbetsbin i jorden
Växtrötter gör mer än att förankra planten. De känner ständigt av sin omgivning, tar upp mineraler och kommunicerar med markens mikrober. Rotassocierade proteiner är centrala för allt detta; de påverkar hur rötter växer, hur de reagerar på värme, torka eller näringsbrist och hur de samverkar med hjälpsamma mikrober. Eftersom dessa proteiner starkt påverkar avkastning och motståndskraft bryr sig odlare och växtförädlare om dem även om de aldrig ser dem direkt. Ändå återstår många sådana proteiner att upptäcka, i huvudsak därför att traditionella metoder—som proteomik och genuttrycksstudier—kräver kostsam utrustning, komplexa analyser och mödosamma experiment.
Gör om proteinsekvenser till ledtrådar
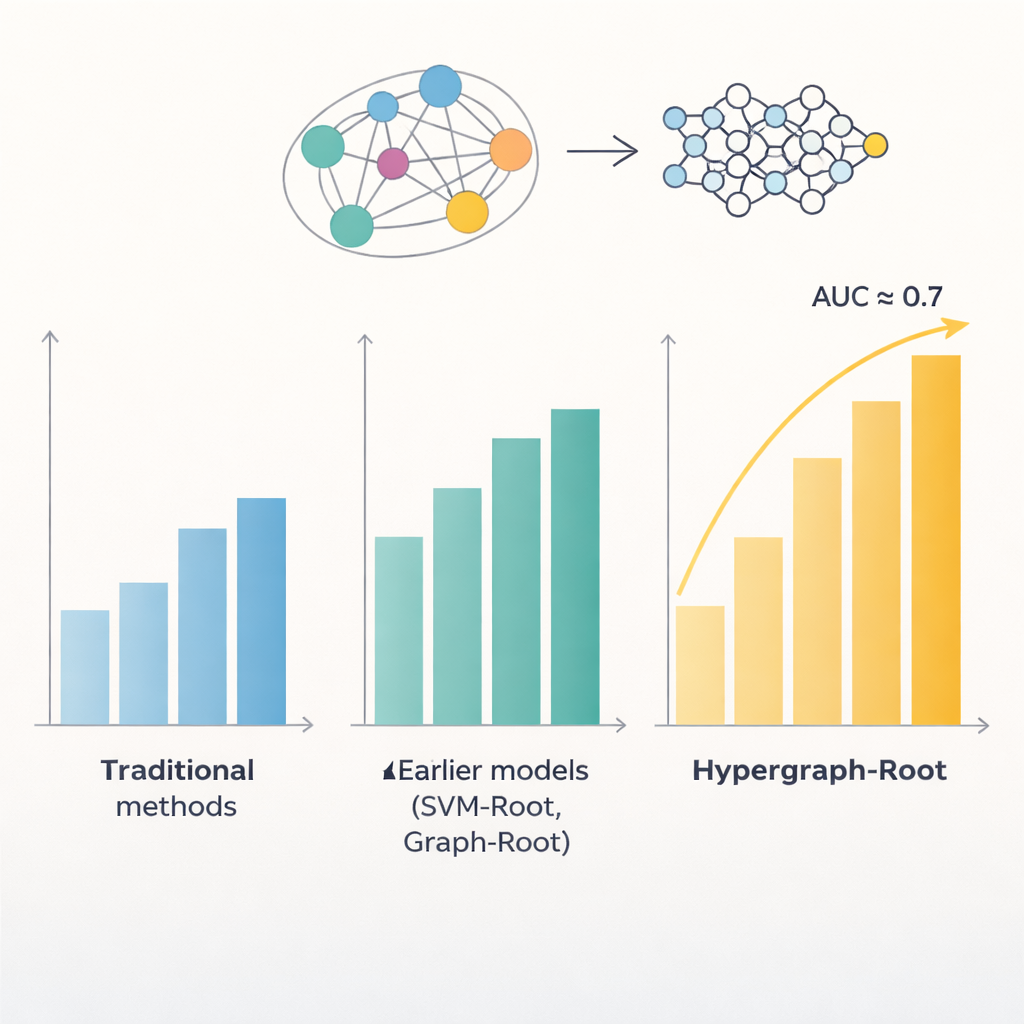
Proteiner byggs av kedjor av aminosyror, och mönster i dessa kedjor avslöjar ofta var ett protein verkar i växten och vad det gör. Tidigare datorbaserade modeller försökte utnyttja dessa mönster för att upptäcka rotassocierade proteiner, men nådde sällan över 80 procents noggrannhet. Ett problem var att de behandlade relationer mellan aminosyror på ett relativt enkelt sätt, vanligtvis som par. Ett annat var att de förlitade sig på begränsade typer av egenskaper som extraherats från sekvenserna. Författarna antog att rikare representationer av varje protein, tillsammans med smartare sätt att modellera aminosyrarelationer, skulle kunna avslöja mer subtila mönster kopplade till rotfunktioner.
Att låna trick från språk och nätverk
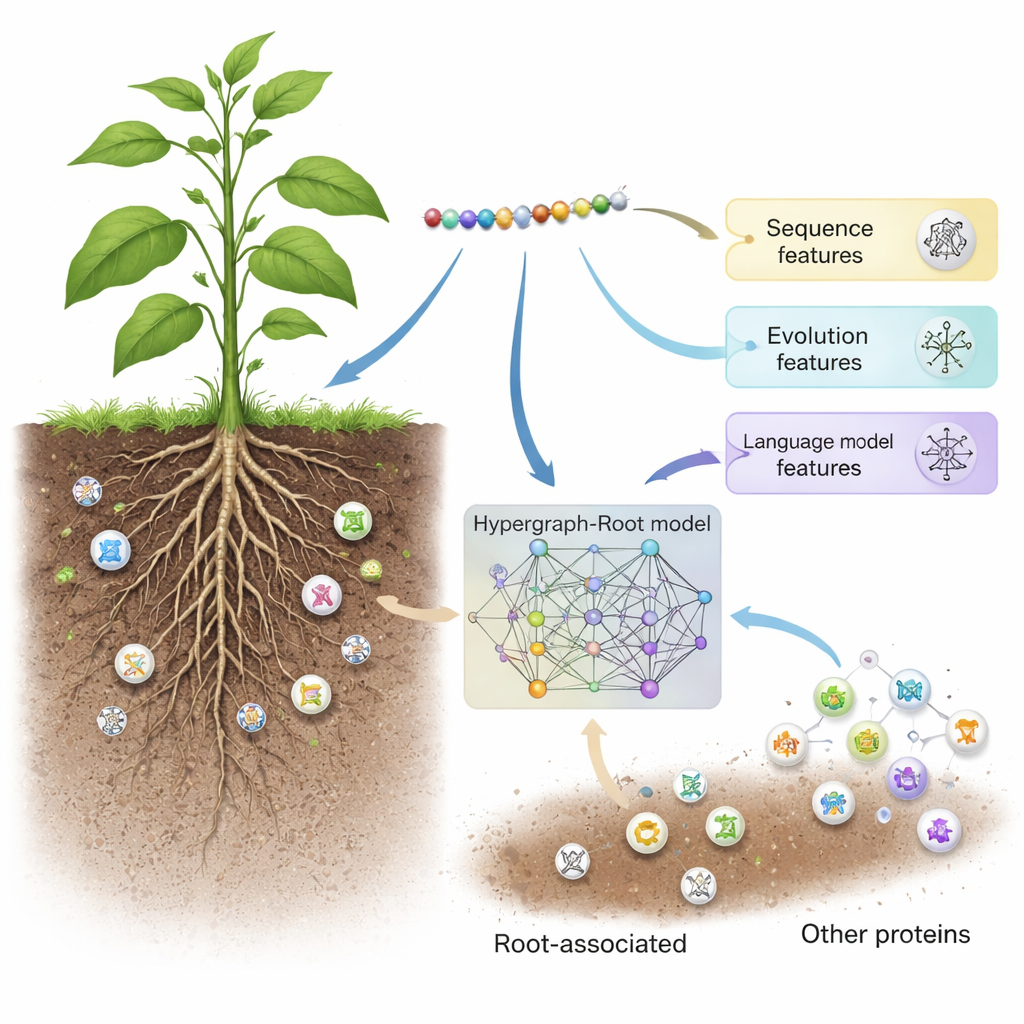
Hypergraph-Root börjar med att beskriva varje protein på tre kompletterande sätt. Den använder traditionella sekvenspoängningsscheman (BLOSUM62 och positionsspecifika poängmatriser) som fångar hur aminosyror tenderar att ersätta varandra genom evolutionen. Den lägger sedan till en tredje, mer modern beskrivning från en protein-språkmodell kallad ProtT5—mjukvara tränad på miljontals proteinsekvenser, ungefär som en textprediktionsmotor tränas på mänskligt språk. ProtT5 ger en rik numerisk ”embedding” för varje aminosyra som kodar strukturella och funktionella ledtrådar. Tillsammans ger dessa tre vyer ett detaljerat fingeravtryck av varje protein i studien.
Kartlägga komplexa kopplingar inuti proteiner
För att gå bortom enkla parvisa jämförelser förutsade forskarna hur nära aminosyror ligger i ett proteins tredimensionella struktur och använde denna information för att bygga en hypergraf—ett nätverk där en enda koppling kan binda mer än två aminosyror samtidigt. Ett specialiserat neuralt nätverk, det hypergrafkonvolutionella nätverket, bearbetar detta strukturmedvetna nätverk och förädlar proteinens fingeravtryck till högre nivåegenskaper. En multi-head attention-modul lär sig därefter vilka delar av proteinet som bär de mest användbara signalerna för att avgöra om det är rotassocierat. Slutligen omvandlar en standardklassificerare dessa destillerade egenskaper till en sannolikhetspoäng: rotassocierad eller inte. Över många träningsomgångar och både balanserade och obalanserade testset nådde Hypergraph-Root noggrannheter över 83 procent och ett area under ROC-kurvan (AUC) kring 0,9, vilket klart överträffade tidigare modeller.
Vad modellen avslöjar och varför det spelar roll
Bortom ren noggrannhet gav modellen insikt i vilken information som betyder mest. Egenskaper från ProtT5-språkmodellen bidrog mer än traditionella sekvens- och evolutionära kännetecken, vilket tyder på att stora förtränade modeller kan fånga subtila biologiska signaler som äldre metoder missar. Hypergrafkomponenten visade sig också vara viktig: att ta bort den eller ersätta den med en enklare grafmodell försämrade prestandan. När forskarna tillämpade Hypergraph-Root på proteiner som tidigare inte märkts som rotassocierade, lyfte modellen fram ett antal proteiner vars kända funktioner—såsom membrantransport och proteinmärkning i rötter—starkt antyder att de verkligen spelar roller i rotbiologi. Dessa kandidater ger nu experimentella biologer tydliga korta listor att testa i laboratoriet.
Från smarta prediktioner till starkare grödor
I vardagliga termer är Hypergraph-Root som en expertbibliotekarie för växtbiologi: givet enbart proteinkedjans ”bokstäver” uppskattar den om proteinet sannolikt verkar i rötterna. Genom att kombinera språkmodellinsikter, evolutionär historia och komplexa strukturella relationer förbättrar den kraftigt tidigare prediktionsverktyg. Den ersätter inte experiment, men kan begränsa tusentals möjligheter till ett hanterbart fåtal, vilket sparar tid och pengar. På längre sikt kan sådana modeller snabba upp upptäckten av rotassocierade proteiner som hjälper grödor att överleva värme, torka eller dåliga jordar—ett viktigt steg mot mer motståndskraftigt jordbruk i ett föränderligt klimat.
Citering: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Nyckelord: rotassocierade proteiner, växtbioinformatik, djuplärande, protein-språkmodeller, gröddors motståndskraft