Clear Sky Science · sv
En multimodal inlärnings- och simuleringsmetod för perception i självkörande system
Smartare självkörande bilar
Självkörande bilar lovar säkrare vägar och mindre trafik, men bara om de verkligen kan förstå världen runt dem. Denna artikel undersöker ett nytt sätt att hjälpa autonoma fordon att ”se”, ”känna” och ”förutse” sin omgivning mer som en aktsam mänsklig förare — genom att blanda olika sensorer, testa säkert i en virtuell kopia av verkliga miljöer och göra bilens beslut mer transparenta för människor.
Se vägen med många ”sinnen”
De flesta förarassistanssystem i dag förlitar sig starkt på kameror, som fungerar väl i bra ljus men har problem i dimma, regn eller på natten. Denna studie kombinerar tre olika sensortyper — kameror, laserskannrar (LiDAR) och radar — så att bilen inte är beroende av en enskild, skör informationskälla. Kameror fångar rik färg och detalj, LiDAR bygger upp en preciserad 3D-bild av scenen och radar förblir tillförlitligt i dåligt väder. Författarna fusionerar alla tre strömmarna till en enhetlig bild av trafiken, vilket ger fordonet en fylligare och mer robust uppfattning om vägar, fotgängare och andra bilar.
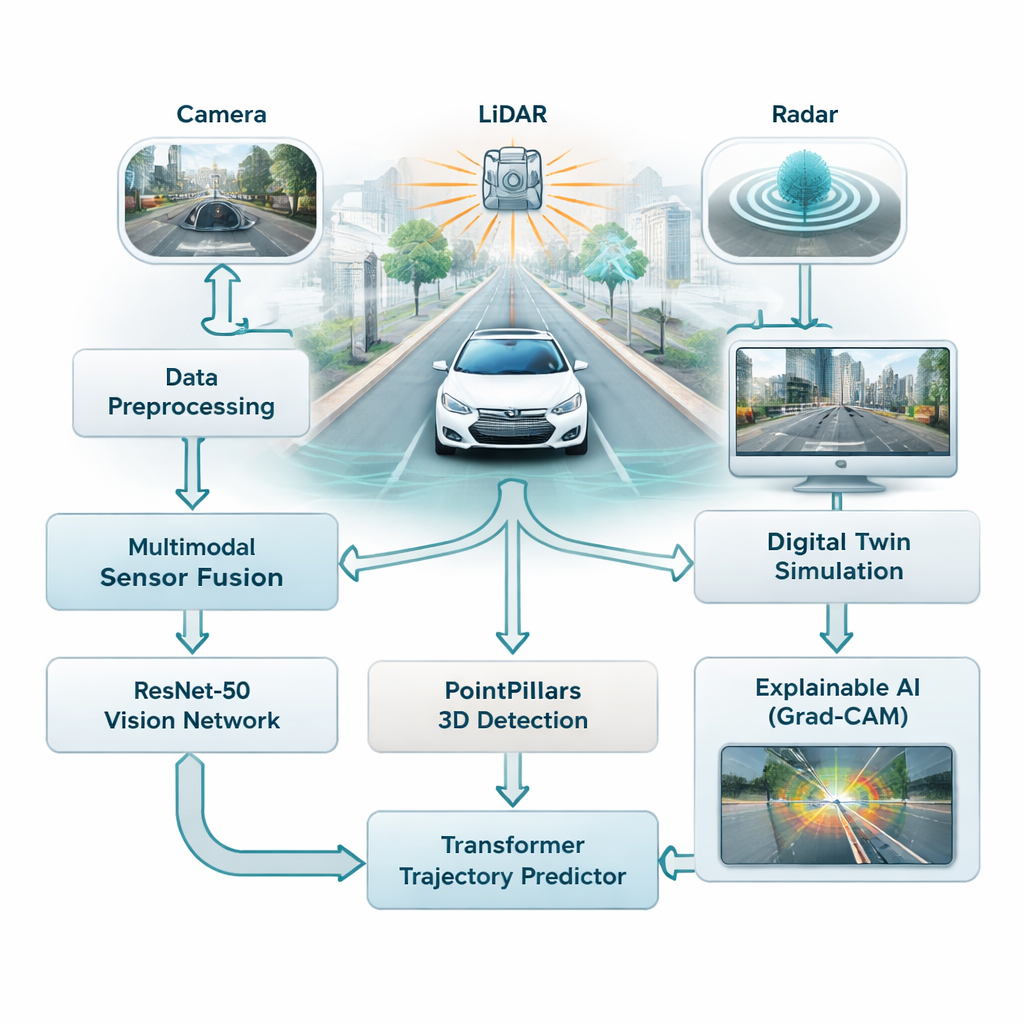
Lära bilen att känna igen och förutse
För att göra denna datamängd begriplig använder ramverket två familjer av moderna AI-modeller. Först skannar ett djupt bildnätverk kallat ResNet-50 kamerabilder för att fånga den övergripande situationen — hur trångt det är på vägen, var körfälten är synliga och hur scenen är upplagd. Samtidigt läser en 3D-modell kallad PointPillars LiDAR-punktmoln för att lokalisera fordon och andra objekt i tre dimensioner. Dessa signaler matas sedan in i en Transformer, en typ av AI ursprungligen utvecklad för språk, som är skicklig på att förstå hur saker förändras över tid. Här lär den sig att förutsäga hur närliggande bilar och andra rörliga objekt sannolikt kommer att röra sig under de kommande sekunderna, med hänsyn till både deras tidigare rörelser och vägstrukturen.
Bygga en säker virtuell testbana
I stället för att testa riskfyllda situationer direkt på allmänna vägar kopplar forskarna sitt system till en digital tvilling — en virtuell replika av verkliga stadsgator baserad på en stor offentlig datamängd från Boston och Singapore. I denna simulerade värld spelas bilens sensorer, rörelser och omgivning upp och kan ändras efter behov, medan AI försöker spåra objekt och prognostisera deras framtida banor. Systemet kan köra dessa ”tänk om?”-scenarier i realtid, med svarstider under 50 millisekunder, vilket tillåter ingenjörer att utforska kantfall som plötslig inbromsning, skarpa svängar eller trånga korsningar utan att utsätta någon för fara.
En titt inuti AI:s ”svarta låda”
En vanlig kritik mot djupinlärning är att det kan vara svårt att förstå varför modellen fattade ett visst beslut. För att åtgärda detta använder författarna en metod kallad Grad-CAM, som framhäver de delar av en bild som mest påverkade modellens utdata. Dessa värmekartor visar till exempel om nätverket fokuserar på en annan bil, en fotgängare eller en körfältsmarkering när det uppskattar trajektorier. Även om denna förklaringssteg körs offline och inte i bilens realtidsloop, hjälper det ingenjörer och säkerhetsgranskare att verifiera att systemet uppmärksammar rätt ledtrådar, vilket är avgörande för att bygga allmänhetens förtroende.
Hur mycket bättre kör den?
När det testades på hundratals stadskörningsscener upptäcker det föreslagna ramverket 3D-objekt noggrant och förutsäger rörelser mer precist än enkla fysikregler som antar konstant hastighet eller jämn acceleration. Dess prognosfel — hur långt de förutsagda positionerna avviker från verkligheten — är avsevärt mindre än sådana baslinjer och nära en stark rekurrent AI-modell, samtidigt som det fortfarande körs tillräckligt snabbt för realtidsbruk. Noga experiment som jämför olika nätverksdesigner visar att en djupare bildmodell och en medeldjup 3D-detektor uppnår den bästa balansen mellan noggrannhet och hastighet, och att systemet kan distribueras på mindre omborddatorer efter modellkomprimering.
Vad detta betyder för vardagliga förare
För icke-specialister är budskapet att säkrare, mer pålitliga självkörande bilar sannolikt kommer från en metod som kombinerar flera sensorer, förutsäger hur scenen kommer att utvecklas och testas grundligt i realistiska virtuella världar. Genom att förena perception, prediktion, simulering och mänskligt begripliga förklaringar i en och samma design förflyttar detta arbete autonoma fordon närmare att bete sig som försiktiga, transparenta partners i trafiken snarare än mystiska maskiner.
Citering: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
Nyckelord: självkörning, sensorfusion, trajektorieprediktion, 3D-objektdetektion, digital tvillingsimulering