Clear Sky Science · sv
En noggrann realtidssegmentering av undervattensobjekt med förbättrad tvådomäns YOLOv11-UOS med fysikstyrd adaptiv förstärkning och uppmärksamhetsförstärkning
Dyk djupare med skarpare digitala ögon
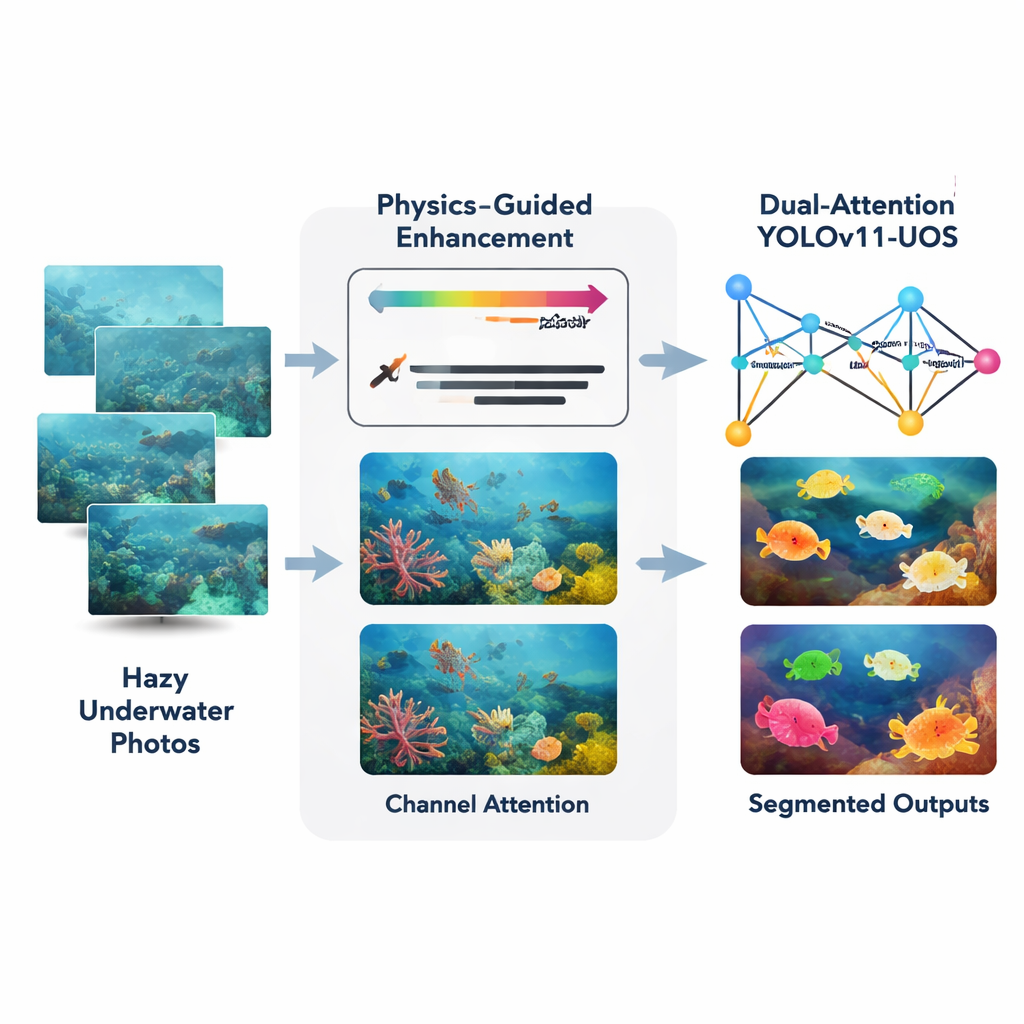
Våra hav utforskas i allt större utsträckning inte bara av dykare och ubåtar, utan av intelligenta kameror monterade på undervattensrobotar. Dessa kameror hjälper till att leta efter skeppsvrak, inspektera havsledningar och övervaka korallrev och fiskbestånd. Ändå är undervattensbilder ofta grumliga, blågröna och fulla av visuell störning, vilket gör det svårt även för människor — än mindre för datorer — att urskilja objekt. Denna artikel introducerar ett nytt datorseendesystem som först rensar upp undervattensbilder och sedan snabbt identifierar och avgränsar objekt i dem, tillräckligt snabbt för att vägleda realtidrobotiska uppdrag.
Varför det är så svårt att se under vatten
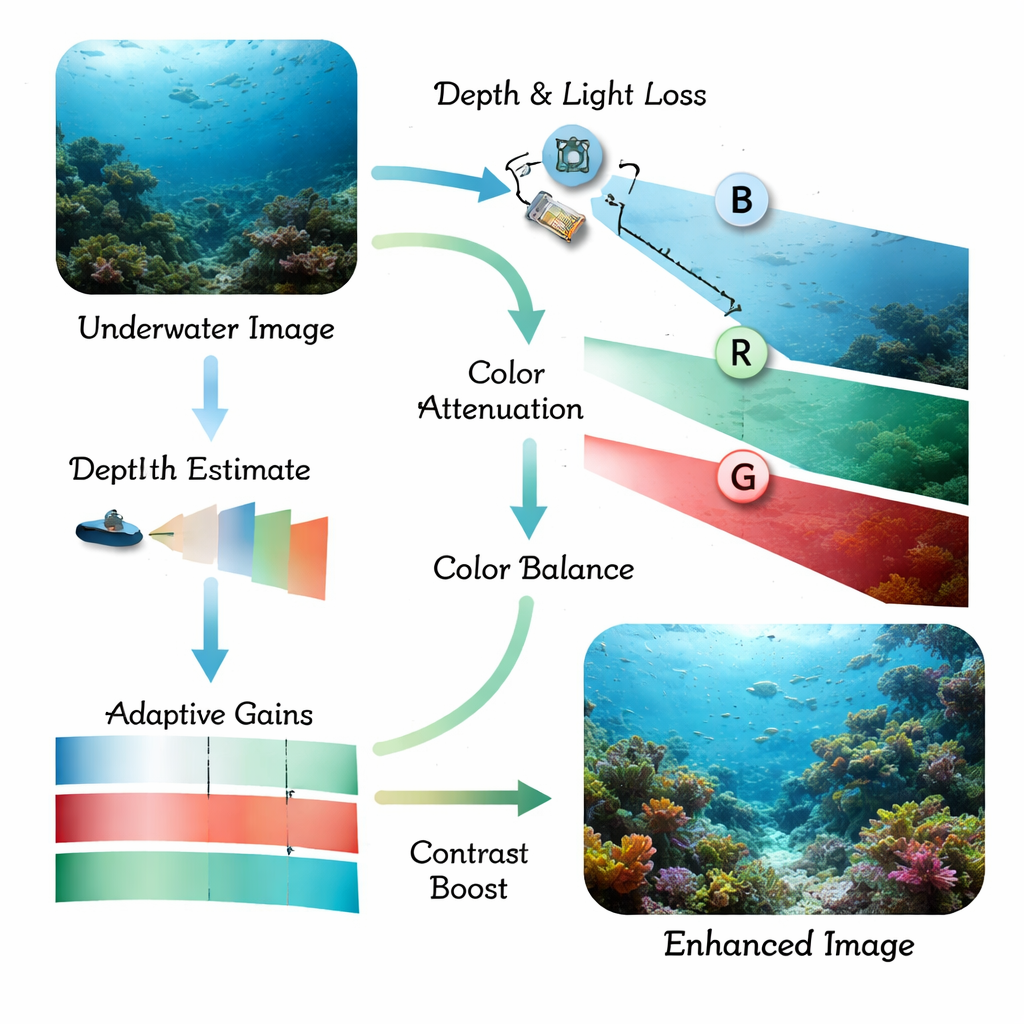
Ljus beter sig mycket annorlunda i vatten än i luft. När solljus färdas nedåt försvinner röda toner först, sedan grönt, vilket ger en blåaktig ton och dova, lågkontrastscener. Små partiklar i vattnet sprider ljuset och skapar dis som suddar ut kanter och döljer små detaljer. Traditionella objektigenkänningsprogram, och även moderna djupinlärningsmodeller, har svårt med dessa förvrängda bilder: fiskar smälter samman med koraller, människoskapade strukturer försvinner i bakgrunden och låglysscener blir närapå oläsliga. Tidigare forskning har oftast tagit itu med antingen bildrensning eller objektigenkänning separat, vilket ofta lämnade det slutgiltiga systemet för långsamt, för bräckligt eller fortfarande blint i särskilt grumligt vatten.
En tvåstegsstrategi: rengör först, fokusera sedan
Författarna föreslår en kombinerad metod byggd kring en modern realtidsdetektor kallad YOLOv11, anpassad här för undervattensscener och instanssegmentering (att rita en exakt kontur runt varje objekt). Först tar ett front-end-modul kallat Adaptive Physics-Guided Enhancement emot råa undervattensfoton och korrigerar dem med en förenklad fysisk modell för hur ljus absorberas och sprids i vatten. Den uppskattar hur långt varje del av scenen ligger från kameran och kompenserar sedan för den starkare förlusten av rött ljus jämfört med grönt och blått. Detta återställer mer naturliga färger och ökar lokal kontrast, samtidigt som ett noggrant histogram-baserat steg skärper kanter utan att förstärka brus, även i mörka eller grumliga regioner.
Lära nätverket var det ska titta
När bilden har rengjorts skickas den till en uppgraderad YOLOv11-backbone som utrustats med uppmärksamhetsmekanismer. Dessa tillagda moduler fungerar lite som en strålkastare och ett färgfilter. Spatial uppmärksamhet anger för nätverket att lägga mer vikt vid viktiga regioner — såsom konturen av en fisk eller kanten på ett nedsänkt artefakt — och att ignorera störande bakgrund som sand eller svajande växter. Kanaluppmärksamhet justerar hur kraftigt systemet väger olika färg- och texturmönster, så att användbara visuella ledtrådar framhävs medan irrelevanta dämpas. Tillsammans hjälper dessa dubbla uppmärksamhetssteg nätverket att bygga skarpare interna representationer innan det bestämmer var objekten finns och vad de är.
Testning i verkliga hav och tuffa förhållanden
För att se hur väl systemet fungerar i praktiken tränade och testade forskarna det på flera publika undervattensbildsamlingar plus ett nytt, specialgjort dataset med över 7 000 noggrant märkta foton från kustområden med varierande djup och grumlighet. De mätte standardpoäng för detektion och segmentering och jämförde sin metod mot välanvända modeller som U-Net, DeepLab, transformer-baserade segmenterare och ett baslinje-YOLOv11-system utan de nya modulerna. Den kombinerade designen med förbättring plus uppmärksamhet ökade den genomsnittliga detektionsnoggrannheten med cirka 6,5 procentenheter över baslinjen YOLOv11, med märkbart renare objektkonturer och färre missade eller felaktigt detekterade objekt. Viktigt är att systemet fortfarande körs i ungefär 38 bilder per sekund på en modern grafikprocessor, tillräckligt snabbt för nära realtidsanvändning på robotplattformar.
Vad detta betyder för oceanrobotar och forskning
Enkelt uttryckt visar studien att smart förbearbetning och fokuserad uppmärksamhet låter datorer "se" mycket bättre under vatten. Genom att först återställa några av de fysikaliska effekter som förstör undervattensfoton och sedan styra detektionsnätverket att koncentrera sig på de mest informativa regionerna och färgerna levererar metoden skarpare, mer pålitliga konturer av fiskar, koraller och människoskapade strukturer. Detta kan hjälpa autonoma undervattensfarkoster att navigera säkrare, övervaka känsliga marina ekosystem och inspektera kritisk undervattensinfrastruktur utan mänsklig övervakning. Utmaningar kvarstår i extremt grumligt vatten eller mycket djupa scener som saknar rött ljus, men ramen erbjuder ett praktiskt steg mot robust, realtidsbaserat undervattensseende som kan stödja framtida 3D-kartläggning och multisensorisk utforskning av oceanen.
Citering: Deluxni, N., Sudhakaran, P., Alroobaea, R. et al. An accurate realtime underwater object segmentation using improved dual-domain YOLOv11-UOS with physics guided adaptive enhancement and attention-boosting. Sci Rep 16, 4804 (2026). https://doi.org/10.1038/s41598-026-35001-x
Nyckelord: undervattensseende, marinrobotik, bildförbättring, objektsegmentering, datorseende