Clear Sky Science · sv
Främja censurerad geokemisk Au-prediktion med Bayesianiska spatiala modeller och Random Forest med fraktalbaserad bakgrundsseparation
Varför pyttesmå spår av guld spelar roll
När geologer letar efter nya fyndigheter arbetar de ofta med jordprover som innehåller endast några få delar per miljard av ädelmetallen. Dessa ultralåga värden ligger så nära laboratorieinstrumentens detektionsgränser att många mätningar helt enkelt returneras som "under detektion". Om dessa nästan osynliga spår hanteras slarvigt kan lovande mineralzoner missas eller kartläggas felaktigt. Denna studie introducerar ett smartare sätt att återvinna information från sådana censurerade värden, vilket hjälper prospektörer att se tydligare mönster i underjorden trots begränsade och brusiga data.
Dolda signaler i ofullkomliga mätningar
Jord- och bergkemi är ett viktigt verktyg för mineralprospektering eftersom små kemiska förändringar kan signalera begravda malmkroppar. Men instrument kan inte mäta oändligt små mängder. För guld i denna studie behandlades varje prov under några få delar per miljard som censurerat: laboratoriet kunde endast ange att det verkliga värdet ligger under den gränsen. Vanliga snabba lösningar ersätter helt enkelt alla sådana resultat med ett konstant värde, till exempel hälften av detektionsgränsen. Trots att det är praktiskt jämnar denna praxis ut naturliga variationer, suddar ut subtila anomalier och förvränger hur guldet förhåller sig till andra grundämnen som koppar. Författarna hävdar att för att verkligen läsa jordens kemiska fingeravtryck måste vi behålla osäkerheten i dessa låga värden i stället för att skriva över dem.
Från geologisk karta till renare bakgrund
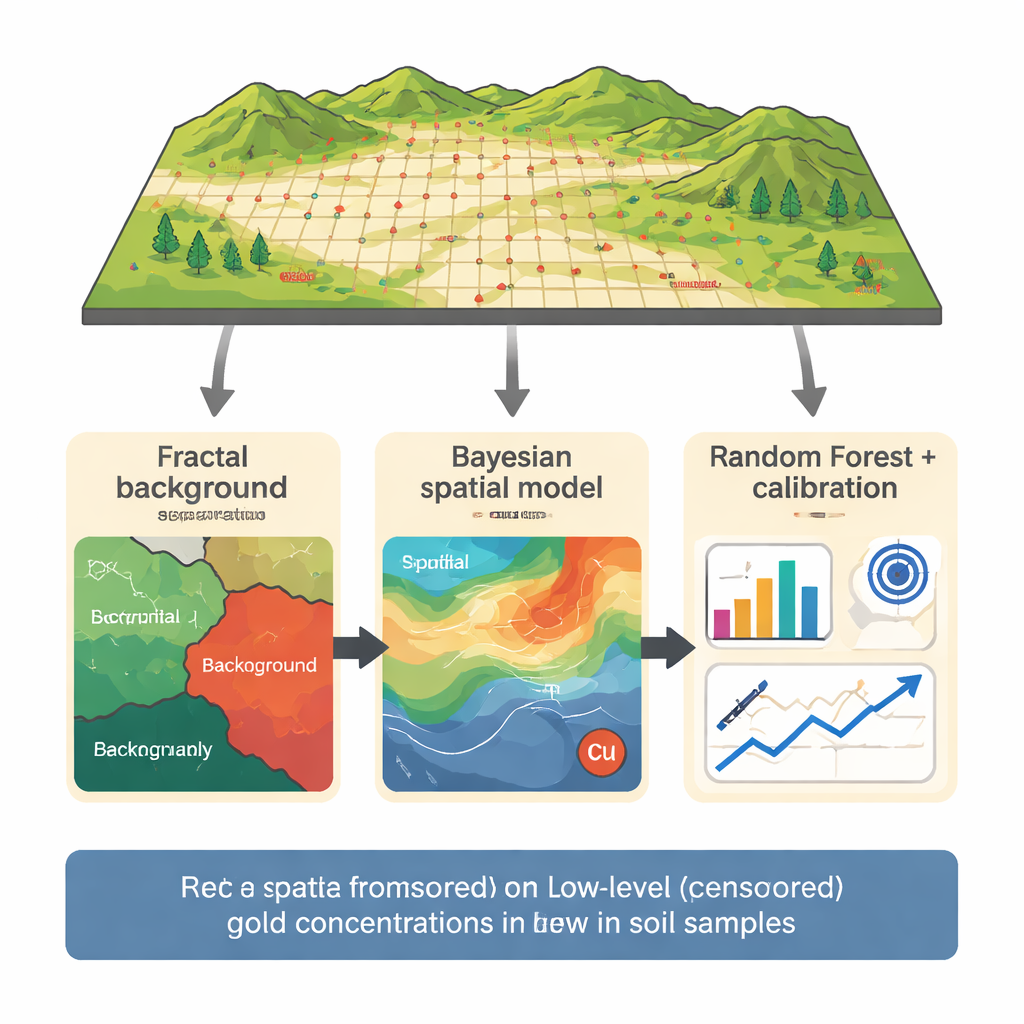
Forskningen fokuserar på ett koppar–guldprospekt i Northern Dalli-området i centrala Iran, där 165 jordprover samlades in på ett tätt rutnät över ett känt porfyrsystem. Guld mättes tillsammans med 29 andra grundämnen, och 14 prover föll under en antagen detektionsgräns på 5 delar per miljard. I stället för att mata in alla data direkt i en modell använde teamet först en "fraktal" koncentrations–antal-metod för att separera bakgrundsvärden från starkare anomalier. Genom att analysera hur antalet prover förändras med ökande guldkoncentration i ett log–log-diagram identifierade de trösklar som delar upp bakgrund, svaga anomalier och starka anomalier. Endast bakgrundspopulationen—inklusive de censurerade värdena—användes för att bygga prediktionsmodellerna, vilket minskar risken att några få höggradiga prover dominerar inlärningen.
En probabilistisk karta styrd av koppar
För att uppskatta det sanna guldinnehållet i de censurerade proverna tillämpade författarna därefter en Bayesiansk Gaussisk Random Field-modell, ett probabilistiskt spatialt tillvägagångssätt. Denna modell behandlar guldkoncentrationen som ett jämnt varierande fält över kartan, påverkat både av läge och av kopparinnehåll, vilket är starkt kopplat till guld i detta porfyriska sammanhang. I stället för att gissa ett enda tal för varje censurerad punkt genererar modellen en full sannolikhetsfördelning som respekterar att det verkliga värdet måste ligga under detektionsgränsen. Resultatet är en uppsättning bästa skattningar och osäkerhetsintervall för de 14 censurerade proverna som är förenliga med närliggande mätningar och med det guld–koppar-samband som observerats i bergarterna.
Maskininlärning, justerad där det spelar störst roll
Dessa probabilistiska skattningar matades sedan in i en Random Forest-modell, en maskininlärningsmetod som kombinerar många beslutsträd. Modellen använder guld, koppar, järn, nickel, titan och bor från bakgrundspopulationen för att lära sig mönster, med noggrann korsvalidering så att varje prov testas endast mot modeller som inte har sett det tidigare. Initiala prediktioner tenderade fortfarande att vara något för höga nära detektionsgränsen, ett vanligt problem när få mycket låga värden finns tillgängliga. För att rätta detta utförde författarna en riktad kalibrering som fokuserade specifikt på intervallet 5–8 delar per miljard och tillämpade sedan ett enkelt skalningssteg för att säkerställa att justerade prediktioner höll sig inom fysikaliskt meningsfulla gränser. Denna trestegsprocess—fraktalseparation, Bayesiansk spatial skattning och kalibrerad Random Forest—gav prediktioner som överensstämde med de faktiska låga guldvärdena mycket bättre än standardmetoder.
Slår de gamla genvägarna
Studien jämförde det nya ramverket med både en grundläggande Random Forest och två klassiska substitutionsregler som ersätter censurerade resultat med fasta fraktioner av detektionsgränsen. Över flera felmått var den kalibrerade och skalade hybrida modellen mest exakt och minst förskjuten, särskilt för prover nära detektionsgränsen där små fel spelar störst roll. Den bevarade också realistisk variation och upprätthöll rimliga samband mellan guld och koppar, medan substitution med en enda konstant för alla censurerade värden förstörde den strukturen. I vissa högre censurerade prover var den nya metodens relativa fel hundratals gånger mindre än traditionella substitutioners.
Tydligare kemiska bilder för prospektering
För icke-specialister är slutsatsen att hur vi behandlar "under detektion"-värden i geokemiska data kan avgöra framgången i sökandet efter nya malmfyndigheter. I stället för att sudda ut osäkerhet med grova ersättningar visar detta arbete att en kombination av probabilistisk spatial modellering, maskininlärning och enkel kalibrering kan återvinna mycket av den dolda informationen i lågnivåmätningar. Resultatet blir renare kartor över subtila guldmönster, mer pålitlig anomalidetektion och i slutändan större chans att hitta malmkroppar med färre borrhål och ärligare data.
Citering: Mahdiyanfar, H. Advancing censored geochemical Au prediction through Bayesian spatial models and Random Forest with fractal-based background separation. Sci Rep 16, 4763 (2026). https://doi.org/10.1038/s41598-026-34999-4
Nyckelord: geokemisk prospektering, censurerade data, guldanomalier, Bayesiansk spatial modellering, maskininlärning i geologi