Clear Sky Science · sv
Övergripande canceröverlevnadsprognoser med maskininlärningsmodeller
Varför nya sätt att förutsäga canceröverlevnad spelar roll
Cancerpatienter och deras familjer ställer ofta en enkel men plågsam fråga: ”Hur lång tid har jag kvar?” Läkare försöker svara med hjälp av sin erfarenhet och tidigare data, men för många ovanligare cancerformer finns helt enkelt inte tillräckligt många liknande fall för att ge precisa prognoser. Denna studie undersöker om moderna datorprogram säkert kan ”låna erfarenhet” från vanliga cancerformer för att hjälpa till att förutsäga överlevnad för mindre vanliga, vilket potentiellt kan ge fler patienter tydligare förväntningar och bättre anpassad vård. 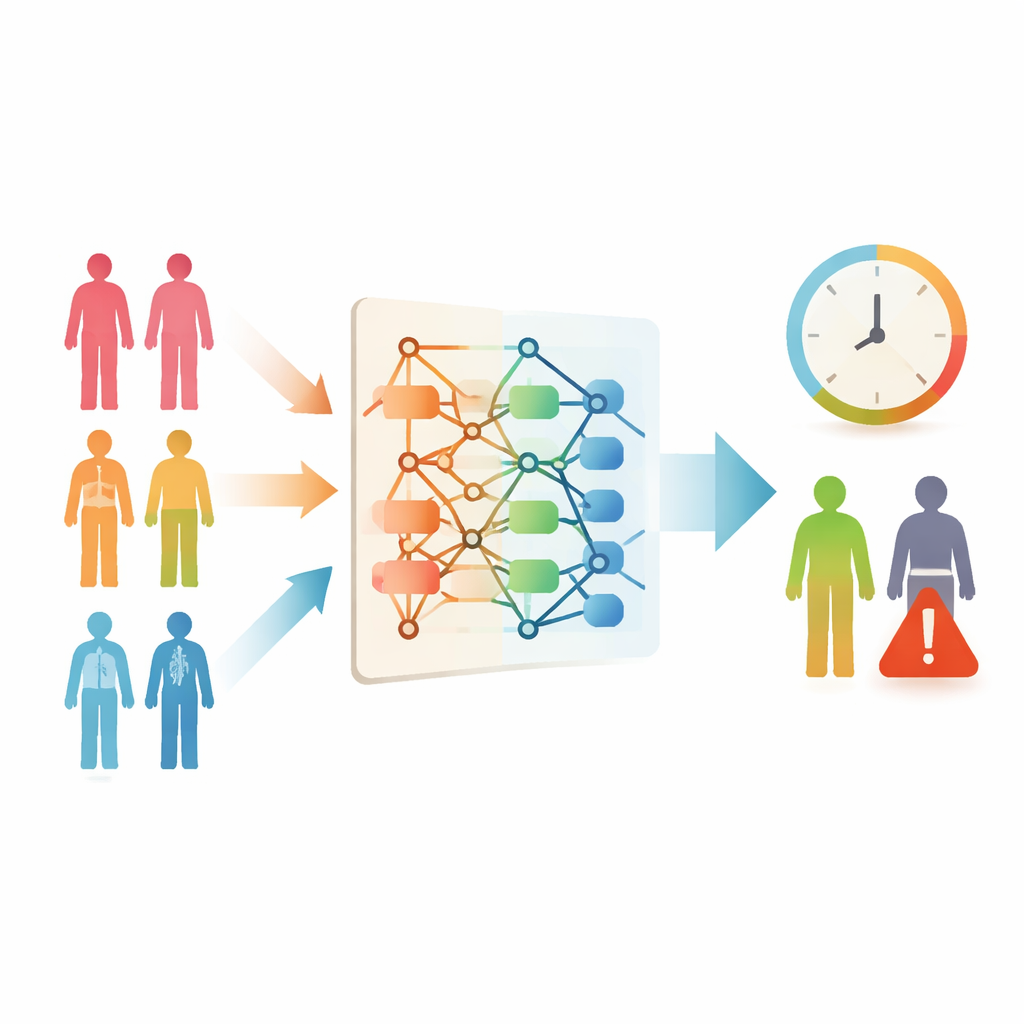
Att använda tidigare patienter för att vägleda framtida vård
Forskarna arbetade med en stor mängd verklighetsdata från sjukhusens cancerregister i São Paulo, Brasilien. Dessa register omfattar mer än en miljon patienter som behandlats mellan 2000 och 2019 och innehåller uppgifter som ålder, tumörstadium, erhållen behandling och om personen fortfarande levde tre år efter diagnos. Genom att fokusera på just treårsgränsen kunde teamet jämföra cancerformer med mycket olika typiska överlevnadstider samtidigt som man undvek extremt snedfördelade data där nästan alla antingen överlever eller avlider.
Att lära datorer att upptäcka mönster för överlevnad
För att omvandla registret till ett prognosverktyg använde författarna två populära maskininlärningsmetoder, XGBoost och LightGBM. Dessa metoder försöker inte förstå biologin direkt; i stället granskar de tusentals patienthistorier för att hitta mönster som kopplar kännetecken som sjukdomsstadium och behandlingstidpunkt till senare överlevnad. Först byggde teamet ”specialist”-modeller, var och en tränad endast på en cancersort, såsom bröst-, lunga- eller magsäckscancer. Därefter testade de hur väl dessa modeller kunde förutsäga treårsöverlevnad för nya patienter med samma cancer, med standardmått som väger korrekt identifiering av överlevare och icke-överlevare.
Kan en cancer hjälpa till att förutsäga en annan?
Studien ställer en djärv fråga i centrum: kan en modell tränad på en cancersort framgångsrikt förutsäga överlevnad vid en annan? För att testa detta grupperade forskarna cancerformer på två sätt: de vanligaste cancerformerna (hud, bröst, prostata, kolorektal, lunga och livmoderhals) och cancer i matsmältningssystemet (munhåla, orofarynx, matstrupe, magsäck, tunntarm, kolorektal och anus). I en första fas tränade de separata modeller för varje cancer och provade dem på de andra, och valde endast par där både överlevnad och icke-överlevnad förutsågs med rimlig balans. I senare faser slog de samman data från utvalda cancerformer till delade träningsuppsättningar och skapade mer generella modeller som drog nytta av mönster över närbesläktade tumörer. 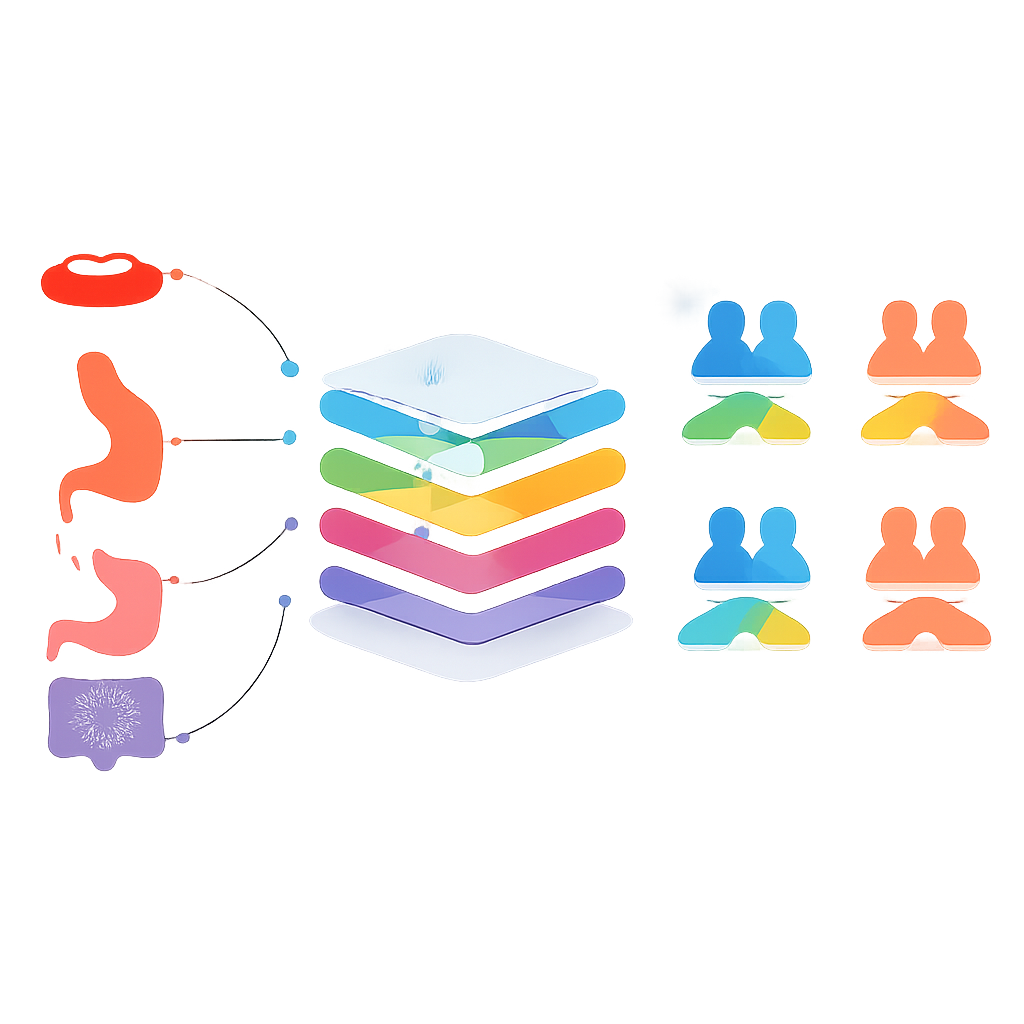
Var kors-cancerinlärning hjälper — och var den inte gör det
För de vanliga cancerformerna överträffade inte kombinerade data de bästa specialistmodellerna. En enda modell tränad på alla sex vanliga cancerformer förutspådde till exempel mindre exakt än modeller anpassade för varje enskild cancer. Berättelsen blev annorlunda för vissa cancerformer i matsmältningssystemet. När data från munhåla-, matstrupe- och magsäckscancer poolades förutspådde den resulterande modellen treårsöverlevnad för magsäckscancer något bättre än modellen som bara använde magsäckscancer, med balanserad noggrannhet strax över 80 procent. Statistiska tester visade dock att denna förbättring inte var tydligt skild från slumpen, vilket innebär att den delade modellen och specialistmodellen i praktiken stod jämsides. Liknande ”nästan men inte riktigt bättre”-resultat dök upp för munhåla-, tunntarms- och kolorektalcancer, ofta med avvägningar mellan att korrekt identifiera överlevare respektive icke-överlevare.
Vad detta betyder för patienter med sällsynta cancerformer
Även om kors-cancermodeller sällan överträffade de bästa sjukdomsspecifika modellerna kom de ofta nära — och då genom att bara använda information lånad från andra cancerslag. För sällsynta cancerformer som saknar stora, högkvalitativa dataset är detta ett uppmuntrande tecken: i framtiden kan läkare kanske förlita sig på modeller tränade på vanligare cancerformer för att erbjuda meningsfulla överlevnadsuppskattningar när specialistverktyg är omöjliga att bygga. Författarna varnar för att dessa metoder inte är redo för rutinanvändning i kliniken och att de måste testas i andra regioner och kombineras med djupare biologiska data. Ändå pekar arbetet mot en framtid där ingen patient lämnas utan vägledning enbart för att deras cancer är ovanlig.
Citering: Cardoso, L.B., Egydio, J.E., Toporcov, T.N. et al. Cross-cancer survival prediction using machine learning models. Sci Rep 16, 9623 (2026). https://doi.org/10.1038/s41598-025-34133-w
Nyckelord: prognos för canceröverlevnad, maskininlärning inom onkologi, modellering över cancerslag, sällsynta cancerformer, kliniska register