Clear Sky Science · sv
Beräkning av meningslikhet genom hybrid djupinlärning med särskilt fokus på negationssatser
Varför ordens betydelse spelar roll för rättvis bedömning
När studenter svarar med egna ord måste datorer som hjälper lärare att rätta dessa svar förstå mer än bara delade nyckelord. Ett litet ord som ”inte” kan vända betydelsen i en mening, och om automatiska system missar den vändningen kan studenter bli bedömda orättvist. Denna artikel tar sig an problemet genom att utforma ett nytt sätt för datorer att jämföra meningars betydelse med särskild uppmärksamhet på hur negationsord förändrar det som sägs.
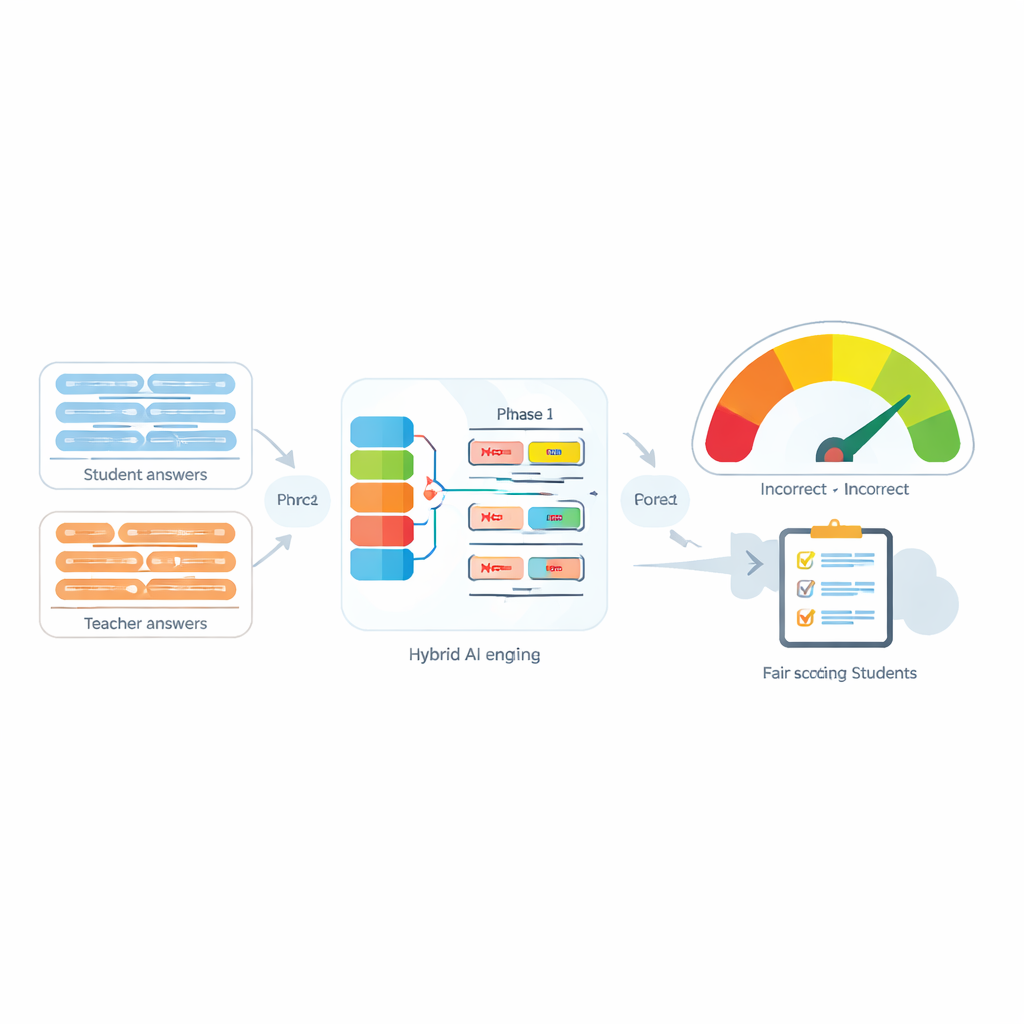
Utmaningen med små ord som har stor påverkan
Automatiska utvärderingssystem används i allt större utsträckning för att lätta lärarnas arbetsbörda genom att jämföra en students svar med lärarens modellösning. Många moderna verktyg gör detta genom att omvandla varje mening till ett numeriskt ”fingeravtryck” och sedan mäta hur nära dessa fingeravtryck ligger varandra. Dessa verktyg fungerar hyggligt när det inte finns negation, men de misslyckas ofta när ord som ”inte”, ”aldrig” eller ”ingen” förekommer. Till exempel kan ”Metoden är korrekt” och ”Metoden är inte korrekt” se förvånansvärt lika ut för en dator, trots att de betyder motsatser. Författarna visar att inte bara närvaron av negation, utan även hur många negationsord som förekommer och var de är placerade i en mening, kan förändra den avsedda betydelsen helt.
Att bygga en datamängd som lär ut nyanser
För att träna ett system som verkligen förstår negation behövde författarna först data som lyfter fram dessa knepiga fall. De skapade Negation-Sentence-Similarity Dataset, innehållande 8 575 meningpar från fyra datavetenskapliga domäner: operativsystem, databaser, datanätverk och maskininlärning. För varje par tilldelade mänskliga bedömare en likhetspoäng som redan tar negation i beaktande. Datamängden registrerar också hur många negationsord varje mening använder och vilken typ av negationsmönster den följer, såsom en enkel ”inte”, ett jämnt eller udda antal negationer, eller mer komplexa fall där negation interagerar med konjunktioner som ”eftersom” eller ”men”. Denna detaljerade märkning ger modellen explicita ledtrådar om hur negationen formar betydelsen.
En hybridmotor som förenar flera perspektiv
Kärnan i det föreslagna systemet, kallat Negation-Aligned Similarity Scorer, är en tvåfasig motor. I första fasen passerar systemet varje mening genom flera olika språkmodeller som var och en fångar något olika aspekter av betydelsen. Deras utdata sammanfogas och förs sedan genom ett bidirektionellt återkommande nätverk som betraktar meningen som helhet och tar hänsyn till ordningsföljd och lokal kontext. Detta producerar en kompakt sammanfattning av varje mening som är bättre anpassad till subtila formuleringar, inklusive var negationsord sitter i förhållande till andra ord.
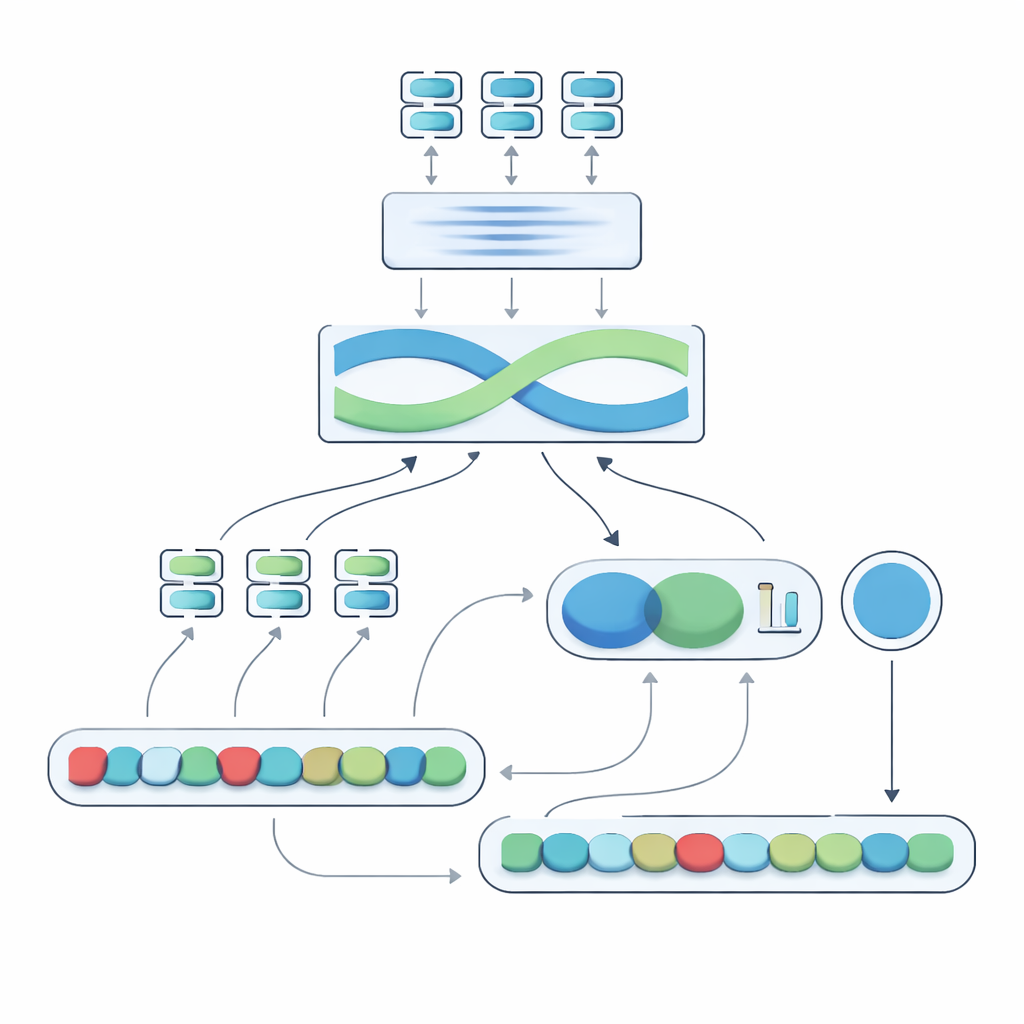
Att lära modellen att känna av negationens vändning
I andra fasen jämför systemet de två meningssammanfattningarna och lägger till explicit information om negation. Det ser hur mycket sammanfattningarna skiljer sig åt, hur mycket de överlappar, och kombinerar dessa signaler med tre enkla funktioner: skillnaden i antal negationsord, huruvida meningarna har udda eller jämna antal negationer (vilket kan vända eller annullera negativ betydelse), samt om negation förekommer i ungefär motsvarande positioner. Alla dessa ledtrådar blandas i ett litet prediktionsnätverk som ger en likhetspoäng från 0 till 100. Tränad end-to-end på den kuraterade datamängden blir denna poäng känslig för hur negation omformar betydelsen i stället för att behandla ”inte” som bara ett annat ord.
Hur väl den nya scorern presterar i praktiken
För att testa sin metod utvärderar författarna den både på deras anpassade datamängd och på en allmänt använd benchmark för meningslikhet. Jämfört med starka transformerbaserade baslinjer som använder standardmetoder uppnår den nya scorern lägre prediktionsfel och mycket högre klassificeringskvalitet, med en F1-poäng nära 0,97. I noga utvalda exempel ger den låga likhetspoäng när negation tydligt vänder betydelsen och höga poäng när dubbel negation i praktiken tar ut varandra, medan konkurrerande modeller fortfarande tenderar att överskatta likheten. En ablationsstudie bekräftar att båda huvudingredienserna — det sekvensmedvetna återkommande lagret och de explicita negationsfunktionerna — är viktiga för denna prestandaförbättring.
Vad detta innebär för studenter och framtida verktyg
För en lekmannaläsare är slutsatsen enkel: sättet vi säger ”inte” på spelar roll, och maskiner kan tränas att märka det. Genom att blanda flera språkmodeller, kontextuell bearbetning och enkla räkningar och positioner av negationsord erbjuder den föreslagna scorern ett rättvisare och mer pålitligt sätt att avgöra när två meningar verkligen betyder samma sak. Detta kan hjälpa automatiska rättningssystem att undvika allvarliga misstag, såsom att behandla ”är inte tillåtet” som om det vore ”är tillåtet”. Även om metoden är mer beräkningskrävande och fortfarande fokuserad på tekniska domäner pekar den mot framtida verktyg som bättre fångar vardagsspråkets finkorniga logik, vilket gör automatiserade språkteknologier både smartare och mer trovärdiga.
Citering: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Nyckelord: meningslikhet, negation i språk, automatisk rättning, bearbetning av naturligt språk, djupinlärningsmodeller