Clear Sky Science · sv
Högpresterande IP-uppslag via GPU-acceleration för att stödja skalbar och effektiv dirigering i datadrivna kommunikationsnät
Varför snabbare internetvägar spelar roll
Varje bild du delar, video du strömmar eller meddelande du skickar måste passera genom ett nätverk av digitala korsningar kallade routrar. Varje router måste snabbt avgöra vart varje datapaket ska skickas härnäst. När den globala internetanvändningen exploderar sker dessa beslut miljarder gånger per sekund, och även små fördröjningar kan ge upphov till långsammare surfning eller trånga nät. Denna artikel utforskar ett nytt sätt att snabba upp ett av de mest tidskrävande stegen i den beslutsprocessen genom att utnyttja grafikprocessorns massiva parallella kraft — samma chip som driver videospel och AI — för att hålla framtidens nät snabba och skalbara.
Internets dolda adressbok
I hjärtat av varje router finns en gigantisk adressbok, kallad en vidarebefordringstabell, som mappar IP-adressintervall till nästa hopp på resan. När ett paket anländer måste routern slå upp vilken post som bäst matchar paketets destination, enligt regeln om "längsta prefixmatch": bland alla partiella adressmatchningar väljs den mest specifika. Traditionella programvarumetoder lagrar dessa prefix i trädliknande strukturer och går igenom dem steg för steg. Det fungerar, men när tabeller växer till tiotusentals eller hundratusentals poster blir processen långsammare och mer minneskrävande, särskilt på vanliga centralprocessorer som bara hanterar ett begränsat antal uppgifter samtidigt.
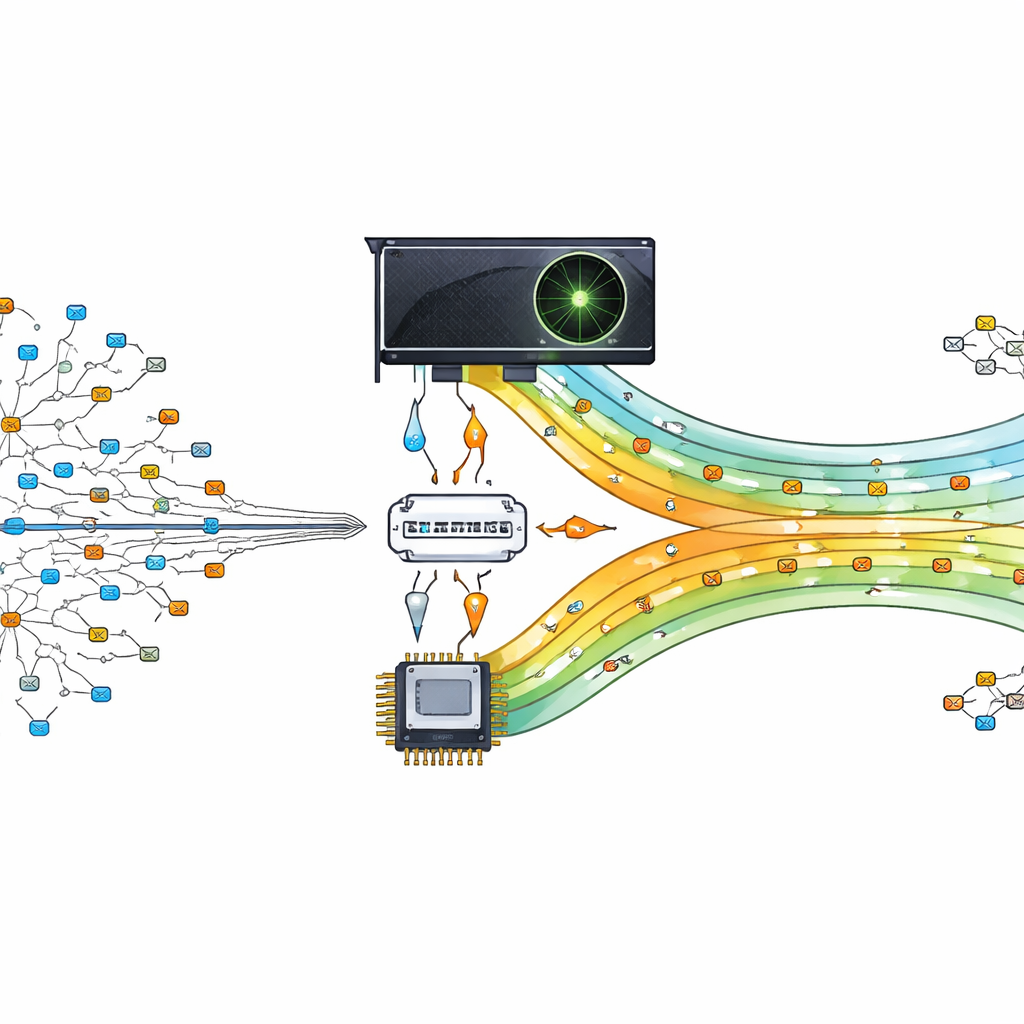
Förvandla ett grafikchip till en trafikpolis
Författarna föreslår att denna tunga uppslagsarbete avlastas till en grafikenhet (GPU), ett chip designat för att köra tusentals små uppgifter parallellt. Deras design behandlar GPU:n som en hjälpare till huvudprocessorn. Huvudprocessorn förbereder och organiserar routningstabellen och skickar sedan kompakta versioner av data till GPU:n. När paket anländer delas deras destinationsadresser upp och skickas till GPU:n, där många trådar samtidigt söker efter bästa match. Genom att låta hundratals eller tusentals uppslag ske parallellt kan routern hålla jämna steg med moderna, datadrivna kommunikationsbehov.
Förkorta adresser för snabbare beslut
Ett viktigt insiktsmoment i arbetet är att kortare adresser är snabbare att söka i. Istället för att använda råa IP-adresser komprimerar författarna dem med en förlustfri metod kallad Huffmankodning, som tilldelar kortare koder till de vanligaste adressmönstren. Detta minskar det genomsnittliga antalet bitar som behövs för att representera varje post, vilket reducerar både minnesanvändning och höjden på den underliggande sökstrukturen. De lagrar sedan prefixen i ett "multibit"-träd som undersöker flera bitar åt gången, snarare än bara en, vilket ytterligare minskar antalet steg som krävs. För att passa GPU:ns styrkor omvandlar de detta träd till enkla endimensionella arrayer och ersätter komplex pekarjakt med regelbundna indexberäkningar som tusentals trådar kan utföra effektivt.
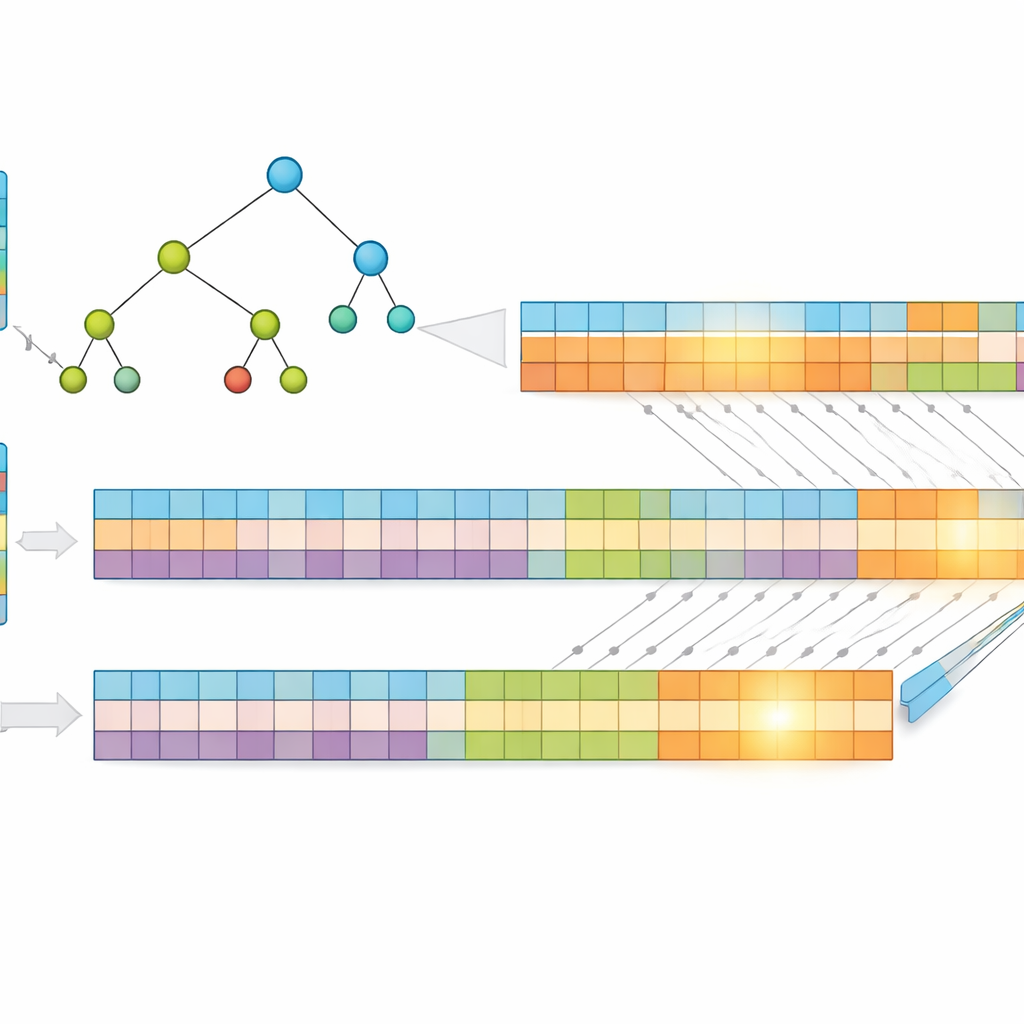
Dela upp problemet för massiv parallellism
För att driva prestandan ännu längre delar forskarna varje komprimerad adress i två lika stora halvor och bygger två separata träd — ett för första halvan och ett för andra. När ett paket anländer söker GPU:n i båda träden parallellt. Varje sökning returnerar en liten uppsättning möjliga träffar, och det slutgiltiga svaret fås genom att intersecta dessa uppsättningar för att hitta det gemensamma, mest specifika prefixet. Eftersom arbetet delas upp och bearbetas samtidigt beror den tid som krävs huvudsakligen på maximalt prefixlängd och antalet bitar som undersöks per steg, inte på hur många poster tabellen innehåller. Tester med verkliga internetroutningsdata visar att denna design upprätthåller en nästan konstant uppslagstid även när tabellen växer.
Vad experimenten visar
Teamet jämförde sin GPU-baserade metod med en rad välkända angreppssätt, inklusive klassiska binära träd, komprimerade träd och andra GPU-accelererade scheman såsom hashing och binära sökträd. På verkliga routningsdataset gav deras system dramatiska vinster: omkring 83–91 procent snabbare än populära CPU-baserade trädmetoder och 89–97 procent snabbare än tidigare GPU-metoder. Kompression minskade också minnesanvändningen med ungefär en tredjedel i genomsnitt, vilket minskade belastningen på det begränsade on-chip-minnet och bidrog till att hålla GPU:ns sökstrukturer grunda och effektiva. Viktigt är att metodens prestanda förblev stabil över olika routningstabellstorlekar, vilket understryker dess lämplighet för växande nätverk.
Vad detta betyder för vanliga användare
För icke-specialister är slutsatsen att författarna visar hur man kan förvandla ett grafikchip till en mycket effektiv trafikkoordinator för internetdata genom smart komprimering och uppdelning av adressinformation. Genom att kombinera kompression, smartare trädlayout och massiv parallell sökning hittar deras angreppssätt det bästa routvalet för varje paket mycket snabbare än många befintliga tekniker, utan att bromsas när internets adressböcker växer. Även om arbetet främst demonstreras för dagens adressystem kan samma idéer utsträckas till morgondagens större adressutrymmen och hjälpa till att hålla framtida onlinetjänster responsiva i takt med att vår dataaptit fortsätter att växa.
Citering: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Nyckelord: GPU-dirigering, IP-uppslag, nätverksskalbarhet, paketframåtriktning, parallellberäkning