Clear Sky Science · sv
Tillämpbarhetsanalys av träd-baserad ensembleinlärning för modeller som förutsäger luftföroreningar
Varför renare luft kräver smartare prognoser
Människor i stora städer undrar ofta på morgonen om luften utomhus är säker för en joggingtur, pendling eller att låta barn leka utomhus. Väderappar visar nu luftkvalitetsindex bredvid temperaturen, men dessa siffror är bara så bra som modellerna bakom dem. Denna studie ställer en praktisk fråga med verkliga följder: vilka moderna artificiella intelligensverktyg gör bäst ifrån sig när flera stora luftföroreningar ska förutsägas samtidigt — och varför?
Spåra stadsluften dag för dag
Forskarna koncentrerade sig på fyra av Kinas största kommuner — Peking, Shanghai, Tianjin och Chongqing — eftersom de täcker olika klimat och föroreningsmönster, från vintersmog till sommarozon. De samlade mer än femtusen dagliga dataposter från 2021 till 2024, där varje post kombinerade mätningar av sex viktiga föroreningar (inklusive fina partiklar, grova partiklar, kvävedioxid, svaveldioxid, kolmonoxid och ozon) med väderdata såsom temperatur, luftfuktighet, vind, nederbörd och lufttryck. För att få ut mer av dessa observationer lade de till ytterligare ledtrådar: hur föroreningar från tidigare dagar kan bära över, hur temperatur och vind samverkar för att sprida förorenad luft, och hur kombinerade mått på partiklar och gaser bättre kan spegla hälsorisker.
Lära de digitala ”träden” att läsa luften
I stället för att använda traditionella, fysikbaserade vädermodeller vände sig teamet till en familj av datadrivna verktyg kända som träd-baserad maskininlärning. Dessa algoritmer fattar beslut genom att upprepade gånger dela upp data i grenar, lite som ett tjugo-frågor-spel som zoomar in på svaret. Studien jämförde tre varianter: ett enkelt beslutsträd; en random forest, som i genomsnitt tar fram resultatet från många träd för att jämna ut brus; och gradient boosting, som bygger träd efter varandra för att gradvis korrigera tidigare misstag. Forskarna finjusterade varje metod omsorgsfullt och använde en tidmedveten teststrategi så att modellerna lärde sig från tidigare dagar och utvärderades på senare dagar, vilket speglar verkliga prognosförhållanden.
Vilka modeller utmärker sig för vilka föroreningar
Jämförelsen visade att ingen enskild metod är bäst för allt, men flera framträdande metoder skiljde ut sig. Random forests var exceptionellt precisa för fina och grova partiklar samt för svaveldioxid och förklarade omkring 99 procent av variationen i deras nivåer — nära det som instrumenten själva kan mäta. För kolmonoxid och kvävedioxid matchade en form av gradient boosting nästan forestens prestanda, vilket tyder på att denna stegvisa korrigeringsmetod passar väl för trafikrelaterade och förbränningsrelaterade utsläpp som snabbt kan skjuta i höjden och falla. Överraskande nog höll det enkla beslutsträdet, trots sin enkelhet, jämna steg i att förutsäga ozon, en förorening som bildas genom solljusdriven kemi och tenderar att följa tröskelliknande mönster som grenreglerna kan fånga.
Titta in i den svarta lådan
För att göra dessa kraftfulla modeller användbara för politiska beslut behövde författarna visa inte bara hur väl de förutsäger utan också varför. De använde en teknik kallad SHAP, som tilldelar varje indata — såsom temperatur, vindhastighet eller en annan förorening — en bidragspoäng för varje prognos. Denna analys avslöjade några talande samband. Kolmonoxid framträdde som en viktig hjälp för uppbyggnaden av fina partiklar, vilket stämmer med dess roll som en markör för ofullständig förbränning som producerar partikelformande ångor. Temperatur ökade starkt ozon, vilket speglar hur varma, soliga dagar förstärker dess produktion. Fuktig luft som samverkade med svaveldioxid tenderade att dämpa partikelutveckling, och starka vindar hjälpte till att rensa ut små partiklar upp till en tröskel, bortom vilken turbulent blandning faktiskt kunde fånga dem lokalt. Dessa mönster kopplar matematiken tillbaka till verkliga atmosfäriska processer och ger ledtrådar för riktade åtgärder.
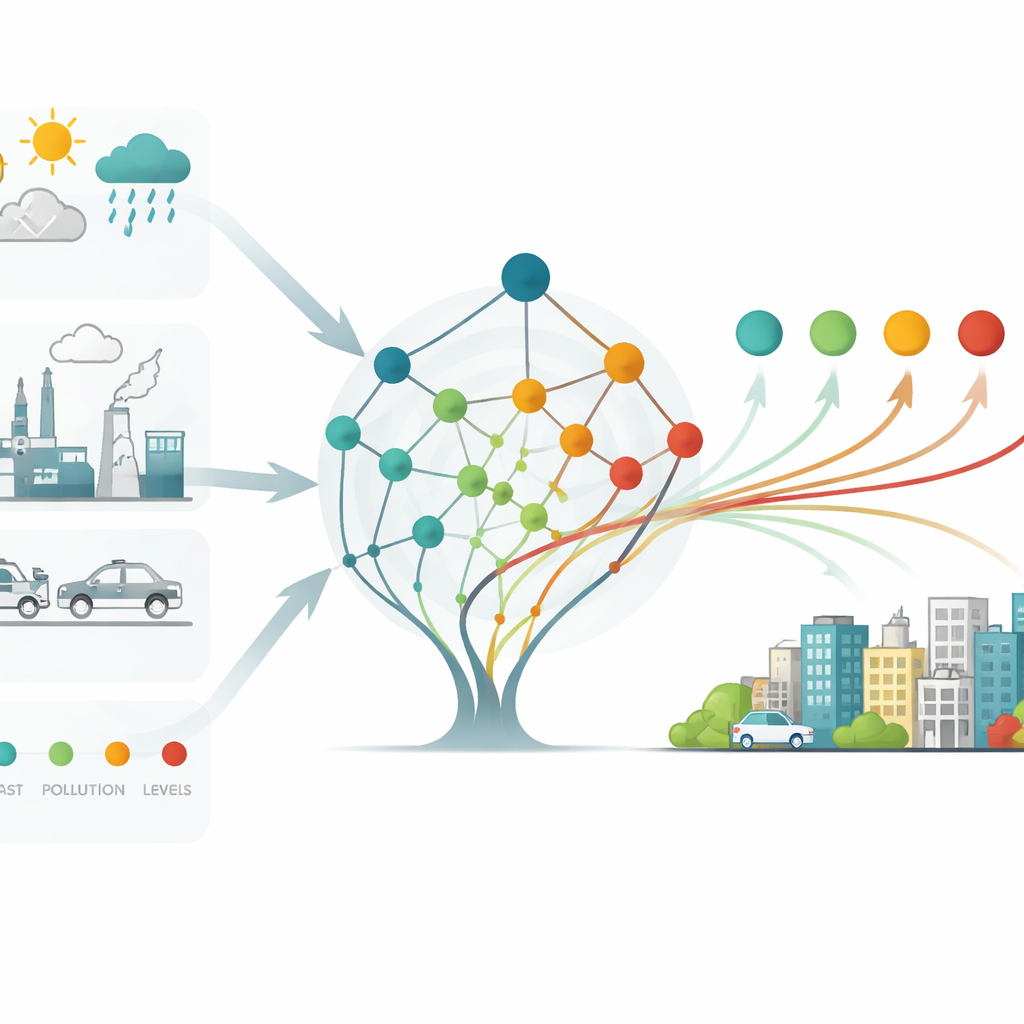
Från forskningskod till städernas varningssystem
Trots imponerande noggrannhet noterar författarna att modellerna fortfarande har problem under de mest allvarliga smogepisoderna och begränsas av grova beskrivningar av var utsläppen kommer ifrån samt av den relativt korta tidsperioden med data. De föreslår att man kombinerar traditionella väder–kemi-simuleringar med maskininlärning och använder SHAP-insikterna för att utforma smartare nödsvar när föroreningsnivåerna skjuter i höjden. Deras ramverk används redan i ett regionalt varningssystem för luftkvalitet som tjänar Peking och närliggande städer. I vardagliga termer visar studien att noggrant utvald och väl förklarad artificiell intelligens kan ge stadsansvariga tidigare, mer pålitliga varningar om dåliga luftdagar — och tydligare vägledning om vilka källor som bör åtgärdas först.
Citering: Zhu, X., Li, B., Cao, Y. et al. Applicability analysis of tree-based ensemble learning for air pollutant prediction models. Sci Rep 16, 9602 (2026). https://doi.org/10.1038/s41598-025-32652-0
Nyckelord: prognoser för luftkvalitet, stadsluftsförorening, maskininlärningsmodeller, random forest, prediktion av flera föroreningar