Clear Sky Science · sv
Detektion av kamouflerade objekt via kontext- och texturmedveten hierarkisk interaktion
Varför det är viktigt att upptäcka dolda former
Från lövfärgade insekter till militär kamouflage och till och med svårupptäckta växter i medicinska skanningar — vår omgivning är full av saker konstruerade för att smälta in i bakgrunden. Att lära datorer att pålitligt hitta dessa dolda objekt kan hjälpa till att skydda vilda djur, förbättra säkerhetsinspektioner och hjälpa läkare att upptäcka sjukdomar tidigare. Denna artikel presenterar ett nytt artificiellt intelligenssystem, kallat CTHINet, som lär sig se igenom kamouflage genom att uppmärksamma inte bara den övergripande scenkontexten utan också små texturledtrådar som det mänskliga ögat ofta missar.
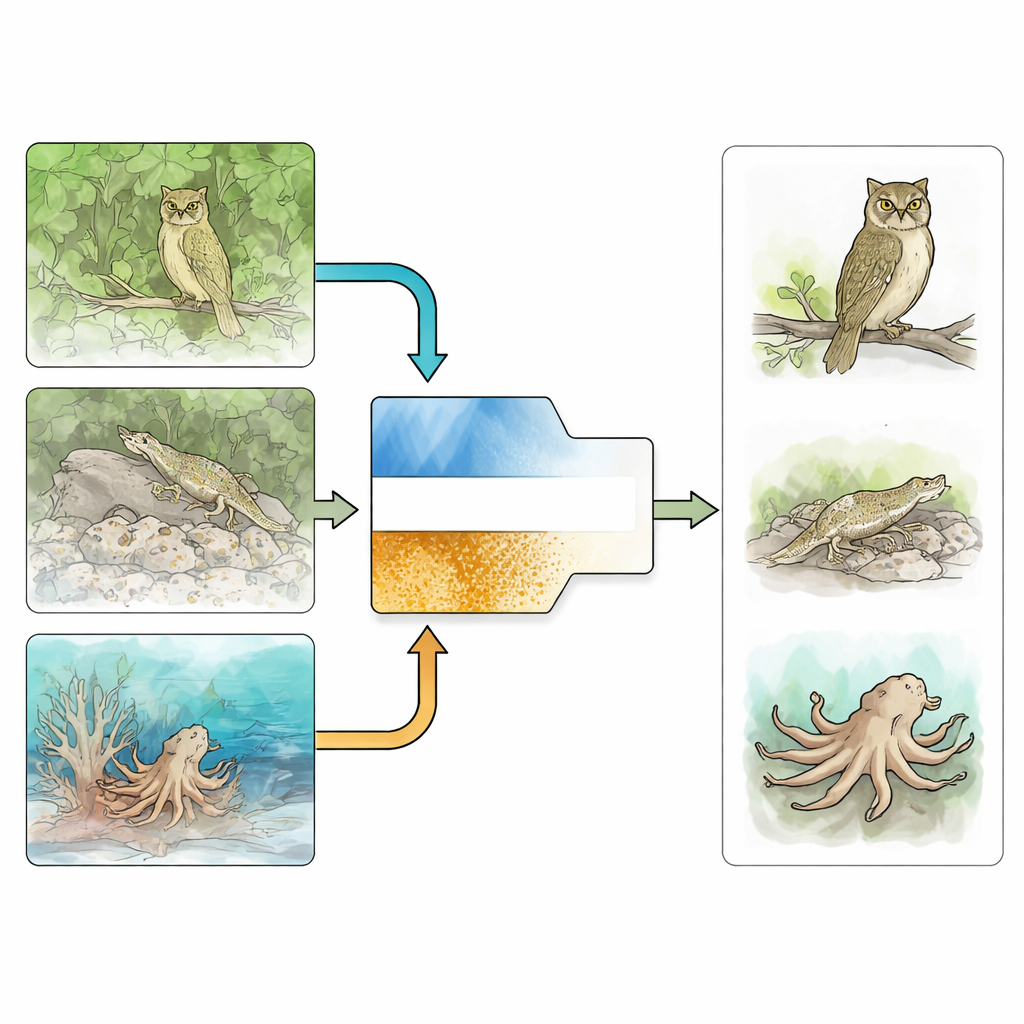
Se både skogen och träden
Detektion av kamouflerade objekt är mycket svårare än vanlig objektigenkänning eftersom målet ofta matchar omgivningen i färg, ljusstyrka och form. Tidigare datorbaserade metoder förlitade sig på enkla handgjorda ledtrådar som rörelse, kanter eller grundläggande textur, vilka fallerar i röriga eller brusiga scener. Moderna djupinlärningsmetoder har gjort framsteg genom att träna stora nätverk på specialiserade bildsamlingar med kamouflerade djur och människoskapade objekt. Många av dessa metoder tillsätter extra ledtrådar, som att rita gränser runt objekt eller uppskatta osäkerhet, men de kan lätt vilseledas när själva kanterna är suddiga eller oklara — vilket är precis fallet vid effektivt kamouflage.
Små texturledtrådar som avslöjar spelet
Författarna hävdar att även det bästa kamouflaget lämnar avslöjande spår i bildens fina textur — små skillnader i kornighet, mönster eller släthet som lätt förbises om man bara fokuserar på konturer. Byggt på denna idé delar CTHINet in lärandet i två koordinerade grenar. En "kontext"-gren, baserad på en kraftfull vision transformer-backbone, fångar bred, flerskalig information om hela scenen: hur områden relaterar till varandra, var stora former ligger och vilka områden som rimligen kan innehålla ett objekt. Parallellt fokuserar en dedikerad "textur"-gren snävt på subtila ytmönster, tränad med specialiserade texturetiketter som berättar för nätverket vilka typer av finare detaljer som tillhör det dolda objektet snarare än bakgrunden.
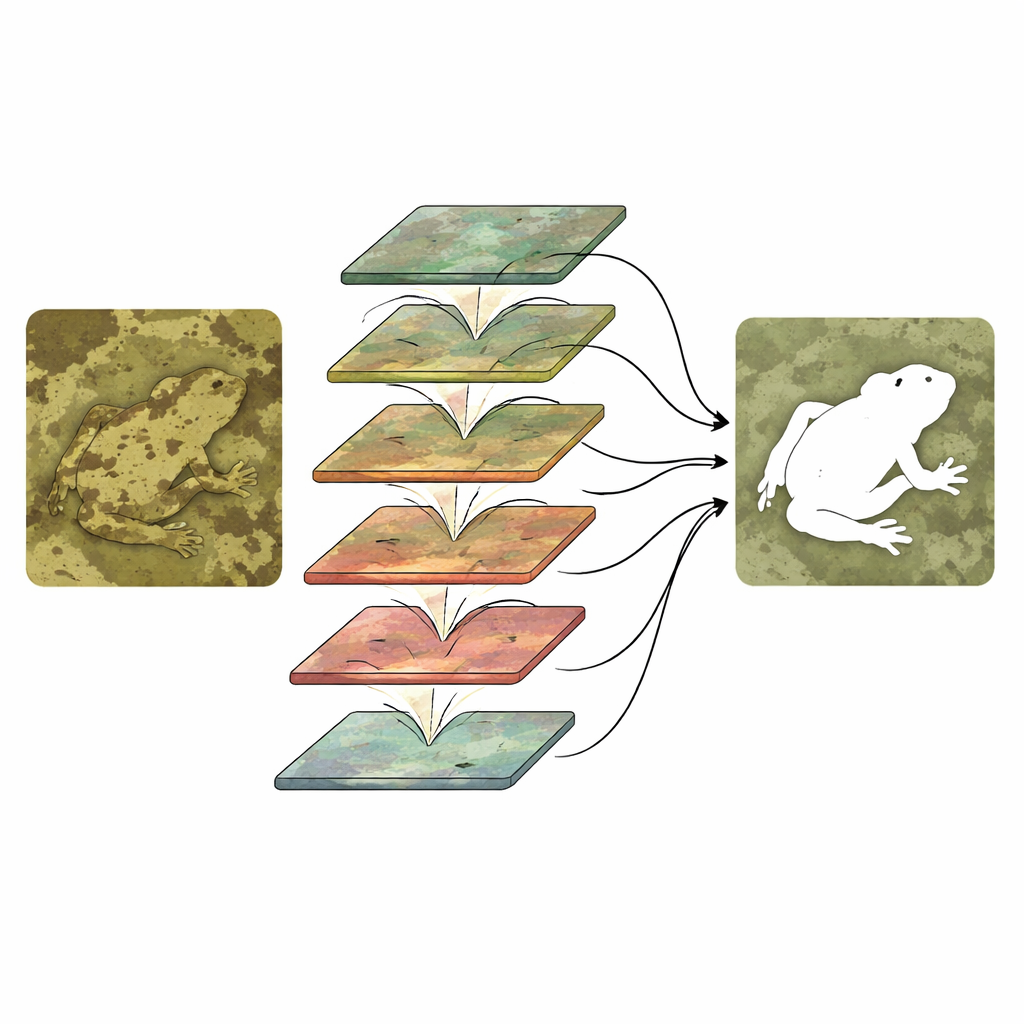
Hur de två grenarna samverkar
Att köra två grenar är inte tillräckligt; de måste interagera på ett smart sätt. CTHINet förfinar först kontextfunktionerna med en Multi-head Feature Aggregation Module. Denna modul delar upp informationen i flera delar, där varje del bearbetas med en annan effektiv "zoombild", så att systemet kan hantera både pyttesmå insekter och stora djur. Den återkombinerar sedan dessa vyer så att de informerar varandra utan att explodera beräkningskostnaden. Därefter länkar en serie Hierarchical Mixed-scale Interaction Modules kontext- och texturströmmarna. Vid varje steg grupperar och blandar nätverket kanaler från båda grenarna, låter dem utbyta information och omviktar dem sedan så att de mest informativa kombinationerna förstärks medan mindre användbara undertrycks. Denna grov-till-finkorniga stapling skärper gradvis en dold objektskontur och separerar den från distraherande bakgrundsdetaljer.
Bevis på att det fungerar i naturen och i kliniken
För att testa CTHINet utvärderade forskarna det på tre utmanande offentliga benchmarks för kamouflerade djur och objekt, innehållande tusentals bilder i varierande naturliga miljöer. Över flera standardmått för noggrannhet överträffade den nya metoden konsekvent mer än tjugo ledande system, särskilt i svåra scener med små mål, stark bakgrundsmatchning eller partiell ocklusion. Teamet testade också samma nätverk, med minimala ändringar, på en medicinsk uppgift: segmentering av polyper i koloskopibilder. Polyper smälter ofta in i tarmväggen på liknande sätt som djur smälter in i lövverk. Även här levererade CTHINet de bästa resultaten bland flera starka modeller för medicinska bilder, vilket tyder på att dess sätt att kombinera kontext och textur är allmänt användbart.
Vad detta betyder för att hitta det nästan osynliga
I vardagliga termer förkroppsligar CTHINet en enkel men kraftfull insikt: för att hitta något som är avsett att vara dolt måste en dator betrakta både helhetsbilden och de allra minsta ytdetaljerna, och låta dessa två perspektiv informera varandra steg för steg. Genom att utforma ett nätverk som tydligt separerar dessa roller för att sedan återförena dem genom noggrant uppbyggda interaktioner uppnår författarna mer exakt detektion av kamouflerade mål och visar lovande resultat för medicinska och industriella inspektionsuppgifter där viktiga strukturer lätt kan förbises. När bilddata fortsätter att växa kan sådana kontext- och texturmedvetna system bli nyckelverktyg för att avslöja det som var avsett att förbli osett.
Citering: Wang, Z., Deng, Y., Shen, C. et al. Camouflaged object detection via context and texture-aware hierarchical interaction. Sci Rep 16, 9328 (2026). https://doi.org/10.1038/s41598-025-32409-9
Nyckelord: detektion av kamouflerade objekt, datorseende, texturanalys, segmentering av medicinska bilder, djupinlärning