Clear Sky Science · sv
Bildprediktionsalgoritm för dimmiga väg scener baserad på förbättrad transformer
Varför det spelar roll att se genom dimma
Att köra genom tät dimma kan kännas som att stirra mot en vit vägg. För både mänskliga förare och självkörande bilar förvandlar dålig sikt vanliga vägar till farliga platser. Denna studie utforskar ett nytt sätt för datorer att "se" tydligare genom dimma genom att omvandla suddiga gatubilder till skarpare, mer informativa bilder. Målet är inte bara vackrare bilder, utan säkrare beslut för autonoma fordon som måste upptäcka körfält, bilar och hinder under alla slags väderförhållanden.
Från suddiga vägar till klarare vyer
Dimma försämrar bilder genom att sprida ljus, tvätta ut färger, mjuka upp kanter och dölja avlägsna objekt. Traditionella tillvägagångssätt försöker vända detta genom att förlita sig på handgjorda regler om hur dimma beter sig, eller genom att förbättra kontrasten på ett generellt, enhetligt sätt. Nyare djupinlärningsmetoder förbättrar detta, men många har svårt att fånga långräckta mönster i en scen, såsom hur avlägsna körfältsmarkeringar eller fordon relaterar till det som är nära kameran. De tenderar också att vara tunga och långsamma, vilket är ett problem för bilar som måste reagera i realtid.
En smartare synmotor för dimmiga vägar
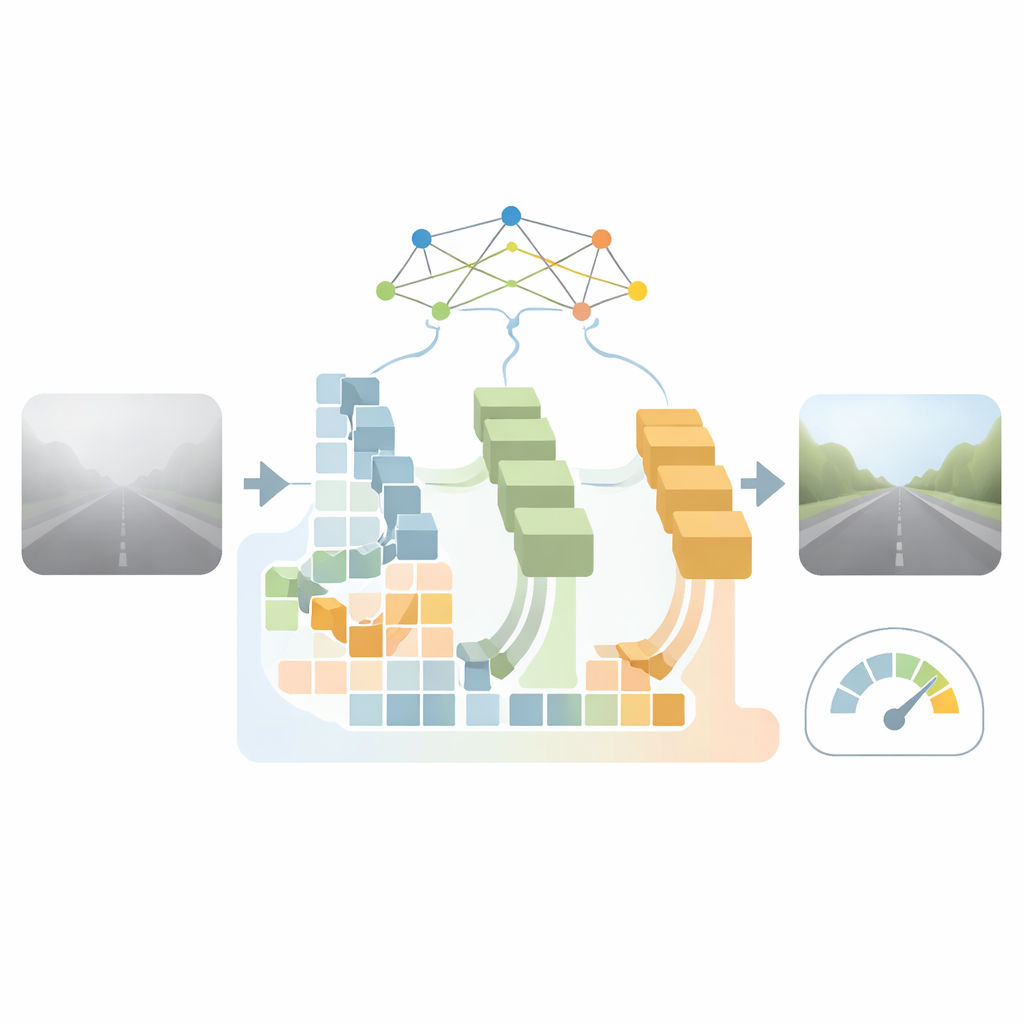
För att tackla dessa begränsningar designar författarna ett specialiserat synsystem baserat på en modern AI-arkitektur känd som Transformer—ursprungligen skapad för att förstå språk, men nu anpassad för bilder. Deras nätverk tar en enda dimmig vägimage och förutspår en klarare version tillsammans med en uppskattning av hur långt fram föraren kan se. Det delar upp bilden i överlappande bitar i flera storlekar, vilket gör det möjligt att fokusera både på fina detaljer som körfältskanter och trafikskyltar, och på den bredare vägutformningen. Dessa bitar bearbetas sedan i flera parallella grenar anpassade till olika dimtätheter, så att lätt dugg eller tät dimma hanteras olika istället för att tvingas genom samma pipeline.
Följa struktur istället för brus
Inuti detta system är den centrala nyheten en strömlinjeformad attention-mekanism som låter nätverket väga relationer mellan avlägsna delar av en bild utan en explosion i beräkningskostnad. Författarna approximera en kostsam intern beräkning så att den beter sig liknande men körs snabbare, vilket förvandlar ett långsamt, kvadratiskt steg till ett mycket mer effektivt. Detta hjälper modellen att koncentrera sig på viktiga strukturer—som inriktningen av körfältsmarkeringar och fordonens konturer—samtidigt som mycket av det slumpmässiga dimbruset ignoreras. Ytterligare attention-moduler förfinar sedan vilka feature-kanaler som är viktigast och vilka rumsliga regioner som förtjänar fokus, vilket ytterligare skärper relevanta kanter och former som är kritiska för navigering.
Testning på verklig och syntetisk dimma
Forskarna sätter samman tre dataset med vägscener som blandar datorgenererad dimma med verkliga dimmiga bilder från städer och motorvägar, och täcker lätt, medel och tät dimma. De tränar sitt system att producera både en avdimmd bild och en synlighetsuppskattning, och jämför sedan med en stark fysikledd metod och flera ledande avdimmningsmodeller. Deras metod återhämtar fler vägdetaljer i många fall—särskilt avlägsna körfältsmarkeringar och fordonskonturer—samtidigt som den använder avsevärt färre parametrar än vissa populära alternativ. Viktigt är att den körs tillräckligt snabbt för realtidsbruk på grafik-hårdvara liknande den som kan vara installerad i en modern bil, och upprätthåller flera dussin bilder per sekund även vid högre upplösningar.
Klarare bilder för säkrare beslut
I vardagliga termer erbjuder detta arbete en lättviktig "digital avdimmare" som hjälper automatiserade körsystem att se mer av vägen under ogynnsamt väder. Även om den inte är perfekt—färgskiftningar och artefakter kan fortfarande uppträda i mycket täta eller komplexa scener—hittar den en praktisk balans mellan bildkvalitet och hastighet. Genom att kombinera multiskaliga vyer, specialiserade grenar för olika dimnivåer och en effektiv attention-mekanism, levererar metoden klarare, mer informativa vägbilder utan att överbelasta omborddatorer. Detta gör den till ett lovande steg mot säkrare autonom körning i de dunkla, lågsynliga förhållanden som utmanar både människor och maskiner.
Citering: Zhang, BT., Zhao, AY. & Xiong, P. Image prediction algorithm for foggy road scenes based on improved transformer. Sci Rep 16, 9579 (2026). https://doi.org/10.1038/s41598-025-25974-6
Nyckelord: dimma vägseende, bildavdimmning, autonom körning, transformer-baserad avbildning, perception i ogynnsamt väder