Clear Sky Science · sv
En storskalig datamängd med val- och svarstidsdata i intertemporala val
Varför väntan kontra nu spelar roll
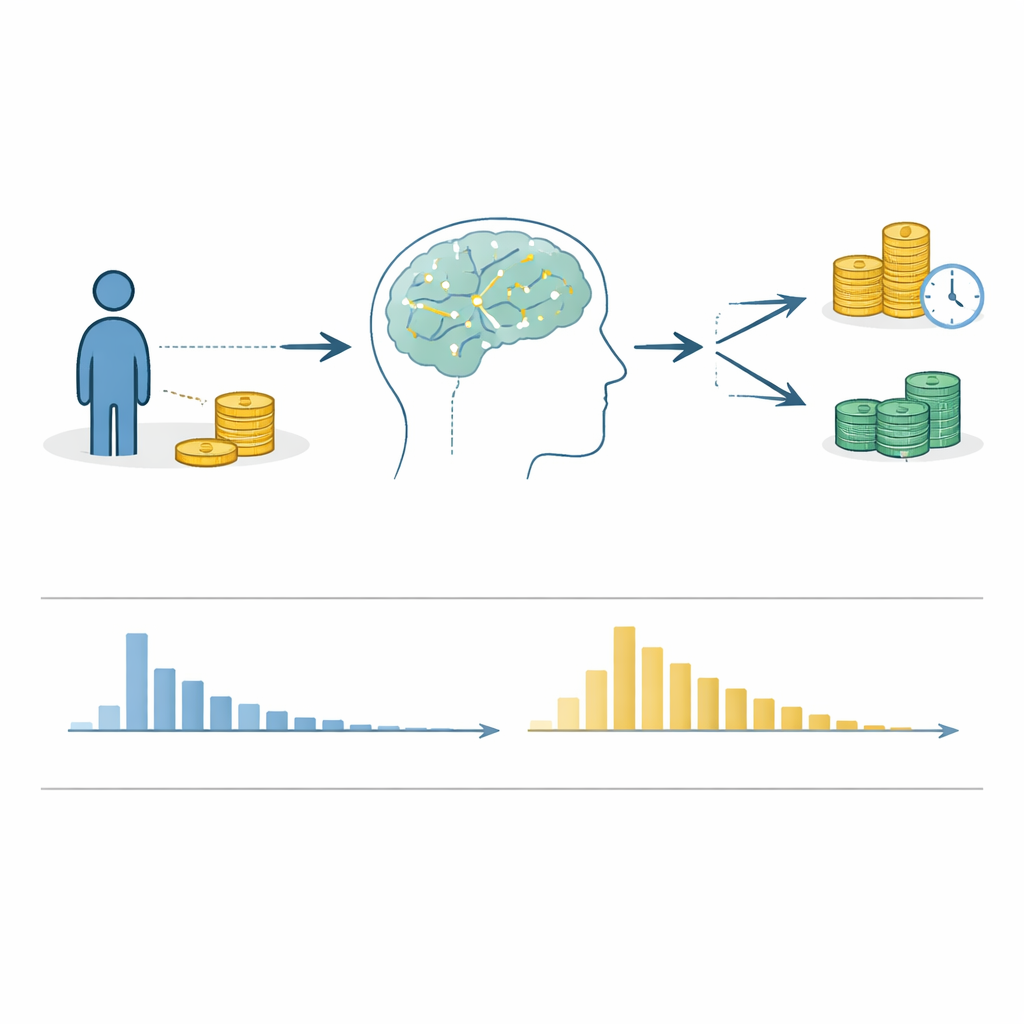
Vardagen är full av val mellan en mindre belöning nu och en större belöning senare: använda pengar idag eller spara till pensionen, ta efterrätten eller hålla fast vid en diet. Hur vi fattar dessa ”nu kontra senare”-beslut — kända som intertemporala val — formar vår hälsa, ekonomi och våra relationer. Ändå tvistar forskare fortfarande om vad som händer i våra sinnen under dessa beslut. Den här artikeln presenterar en omfattande ny öppen datamängd som samlar detaljerade register över hur nästan tolv tusen personer gjorde sådana val, inklusive inte bara vad de valde utan också hur lång tid de tog på sig att bestämma sig.
Samla spridda studier under ett tak
I årtionden har ekonomer och psykologer genomfört experiment där människor väljer mellan exempelvis en mindre summa pengar snart och en större summa senare. Många av dessa studier fokuserade endast på det slutliga valet och ignorerade själva beslutsprocessen. Författarna menar att detta förbiser en viktig källa till insikt: svarstider — hur många sekunder människor tar på sig att bestämma sig. Svarstider kan avslöja hur lätt eller svårt ett val känns och hjälpa till att pröva teorier om hur hjärnan väger omedelbara kontra framtida belöningar. För att gå bortom isolerade fynd samlade författarna rådata på enskilda försök från 100 separata studier, vilka tillsammans täcker 11 852 deltagare och 1 172 644 individuella beslut.
Spåra upp och förena data
Teamet genomförde först en stor, systematisk sökning i den vetenskapliga litteraturen i två större databaser för att hitta publicerade experiment som använde en standardiserad datorbaserad intertemporal uppgift med tydligt angivna penningbelopp och väntetider. Av mer än fyra tusen initiala träffar tillämpade de strikta kriterier för att exkludera studier som inte passade uppgiften, inte var peer-reviewed, använde icke-mänskliga försökspersoner, inte var på engelska eller saknade primärdata. Detta urval lämnade 1 709 potentiellt lämpliga artiklar. För var och en av dessa lokaliserade forskarna antingen befintliga öppna datafiler eller kontaktade författarna direkt, och skickade slutligen mer än 1 600 formella dataförfrågningar för att få tillgång till underliggande försöksnivåinformation.
Hur den sammansatta datamängden ser ut
Genom detta arbete erhöll författarna 112 dataset från 98 publikationer och, efter slutliga tillstånd och kvalitetskontroller, publicerade 100 dataset från 87 artiklar. Varje rad i den sammansatta filen motsvarar ett enskilt valförsök och innehåller vad som erbjöds (ett mindre-snabbare och ett större-senare belopp), vilken option som valdes samt hur lång tid personen tog på sig att svara. Ytterligare fält beskriver deltagaren (såsom ålder och land), hur uppgiften genomfördes (online kontra i labb, om val betalades ut verkligt, om det fanns tidspress) och hur data bör filtreras (till exempel försök med saknade värden). All data tillhandahålls i vanliga format och delar samma variabelstruktur, vilket gör det enkelt för andra forskare att analysera dem med olika mjukvaruverktyg.
Kontrollera data bakom kulisserna
Eftersom datamängden kombinerar många oberoende studier genomförde författarna omfattande tekniska kontroller för att säkerställa att siffrorna är rimliga. De jämförde de rapporterade stickprovsstorlekarna och antalet försök i varje artikel med vad som faktiskt fanns i filerna, dokumenterade eventuella avvikelser och granskade mönster av saknade svar. De verifierade att det mindre-snabbare alternativet verkligen var mindre och snabbare än det större-senare och följde upp med de ursprungliga författarna när något såg konstigt ut. De testade också om människors val uppförde sig rimligt — till exempel om större belöningar och kortare väntetider generellt ökade sannolikheten att ett alternativ valdes. För svarstider skannade de efter omöjliga värden, såsom negativa tider eller beslut som var osannolikt snabba eller långsamma, och granskade om de flesta deltagare visade det typiska mönstret med många snabba svar och färre långsamma.
En levande resurs för framtida insikter
Författarna har publicerat en statisk ögonblicksbild av denna storskaliga datamängd, kopplad till artikeln, samt en levande online-databas som kommer att fortsätta växa i takt med att fler forskare bidrar med sina data. Vid sidan av den sammanslagna huvuddatan finns också alla individuella dataset tillgängliga som separata nedladdningar där tillstånd medger det. Även om de ursprungliga bearbetningsskripten inte delas i alla fall är de resulterande uppgifterna dokumenterade och licensierade för vid återanvändning i icke-kommersiellt arbete. Denna resurs öppnar dörren för forskare att pröva nya modeller för hur människor jonglerar med nuvarande och framtida belöningar, att undersöka varför resultat ibland skiljer sig mellan miljöer och grupper, och att utforma mer tillförlitliga teorier om beslutsfattande. För den lekmannamässiga läsaren är huvudpoängen att forskare nu har en kraftfull, gemensam grund för att förstå varför det kan vara så svårt att vänta på en bättre morgondag — och hur den svårigheten varierar från person till person och situation till situation.
Citering: Pongratz, H., Schoemann, M. A large-scale dataset of choice and response-time data in intertemporal choice. Sci Data 13, 323 (2026). https://doi.org/10.1038/s41597-026-06947-4
Nyckelord: intertemporala val, tidsdiskontering, svarstider, beslutsfattande, öppen datamängd