Clear Sky Science · sv
Datamängd med maternell‑fetal ultraljudsvideo för helhetsbaserad intrapartum‑biometri och multitask‑inlärning
Varför mätning av förlossningsförloppet är viktig
När ett barn föds måste läkare och barnmorskor ständigt bedöma hur förlossningen fortskrider och om mor och barn är i säkerhet. I dag bygger dessa bedömningar i hög grad på en läkares förmåga att tolka suddiga ultraljudsbilder i realtid. Det kräver många års träning och kan fortfarande vara långsamt och subjektivt. Denna artikel presenterar en ny publik samling korta ultraljudsvideor tagna under förlossning, noggrant märkta av experter, för att hjälpa forskare bygga artificiella intelligenssystem som automatiskt kan följa hur långt ner fostrets huvud har trängt. På sikt skulle sådana verktyg kunna stödja säkrare och mer konsekventa beslut i förlossningssalar över hela världen.
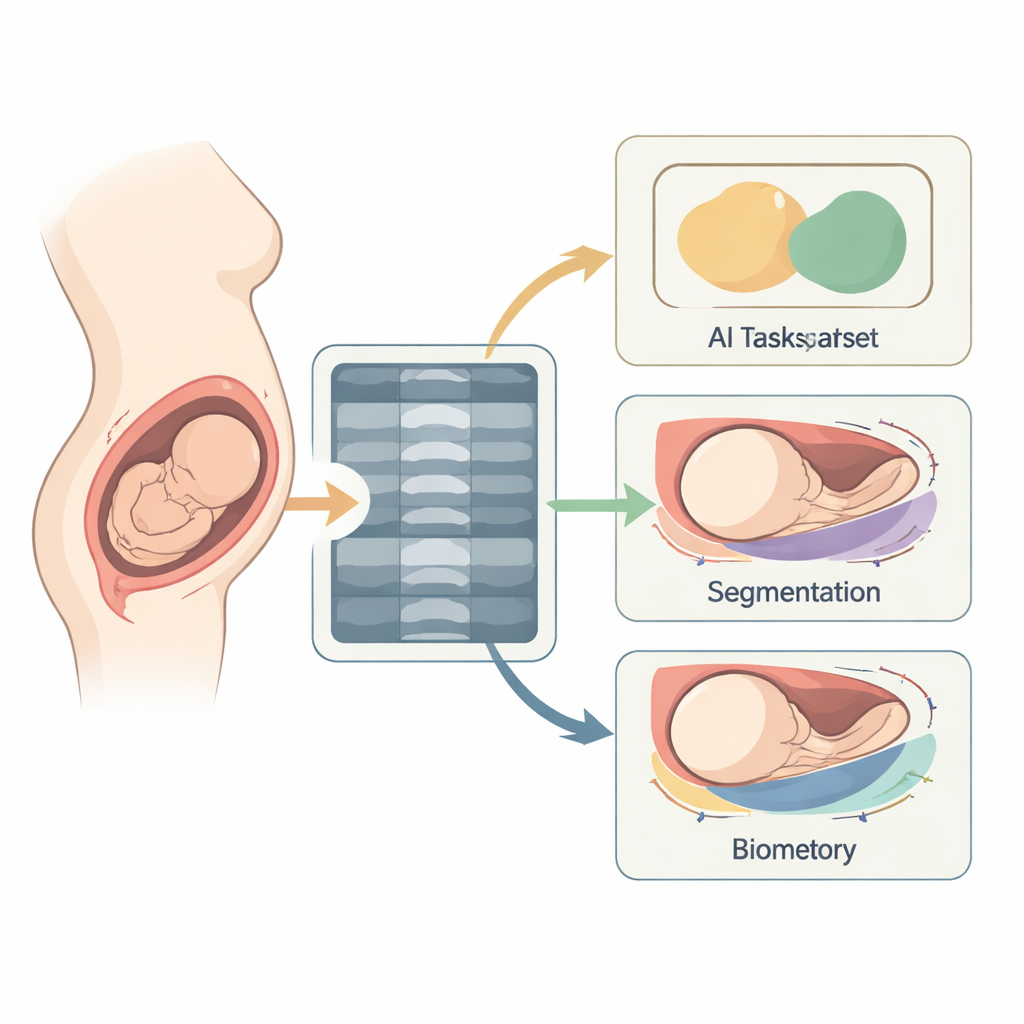
Ett nytt fönster in i förlossningen i realtid
Författarna fokuserar på en särskild typ av undersökning kallad intrapartum‑ultraljud, utförd medan förlossningen pågår. Dessa undersökningar är billiga, allmänt tillgängliga och har potential att minska dödsfall i samband med förlossning — en period då nästan hälften av alla mödra‑ och nyföddhetsdödfall inträffar. Professionella föreningar har utfärdat detaljerade riktlinjer som beskriver vilka vyer som bör fångas och vilka mätningar som bäst återspeglar hur fostret rör sig genom födslokanalen. Två av de viktigaste är progressionsvinkeln och avståndet mellan huvudet och symfysen, vilka tillsammans beskriver hur långt och hur snabbt fostrets huvud rör sig framåt. Fram till nu har det dock inte funnits någon större publik videodatamängd som visar dessa vyer under förlossning och kopplar dem till de mätningar som läkare använder.
Från råa videor till rikt annoterade data
För att överbrygga detta gap samlade teamet ultraljudsinspelningar från 774 födande kvinnor, alla med ett ensamfoster i huvudbjudning vid eller efter fullgången tid. Undersökningarna kom från tre stora sjukhus och tre olika ultraljudsmaskiner, vilket gör datan mer representativ för verklig klinisk praxis. Varje kort klipp varar ungefär två sekunder och består av dussintals ramar som visar fostrets huvud och moderns bäckenkam från sidan. Forskarna konverterade alla videor till en gemensam storlek, tog bort identifierande information som namn eller datum och standardiserade bilderna så att fysisk skala bevaras över enheter. Denna noggranna förberedelse gör att samlingen kan fungera som en rättvis testbädd för nya datorprogram.
Hur experter lärde datorn vad som är viktigt
Att skapa användbar träningsdata krävde betydligt mer än att spara videofiler. Erfaren ultraljudspersonal granskade klippen bild för bild. För utvalda ramar markerade de konturen av fostrets huvud och moderns blygdben och skapade färgade masker som visar var respektive struktur ligger. De angav också nyckelreferenspunkter längs dessa konturer — fyra särskilda punkter som kan användas för att återskapa progressionsvinkeln och avståndet från symfysen till fostrets huvud. Dessutom markerade de hela videor enligt flera ja‑ eller nej‑kliniska frågor, vilket förvandlade varje klipp till en kompakt sammanfattning av vad ett automatiserat system bör dra för slutsats. Författarna organiserade all denna information i tydliga mappar, tabeller och koordinatfiler så att andra enkelt kan koppla in den i sina egna algoritmer.
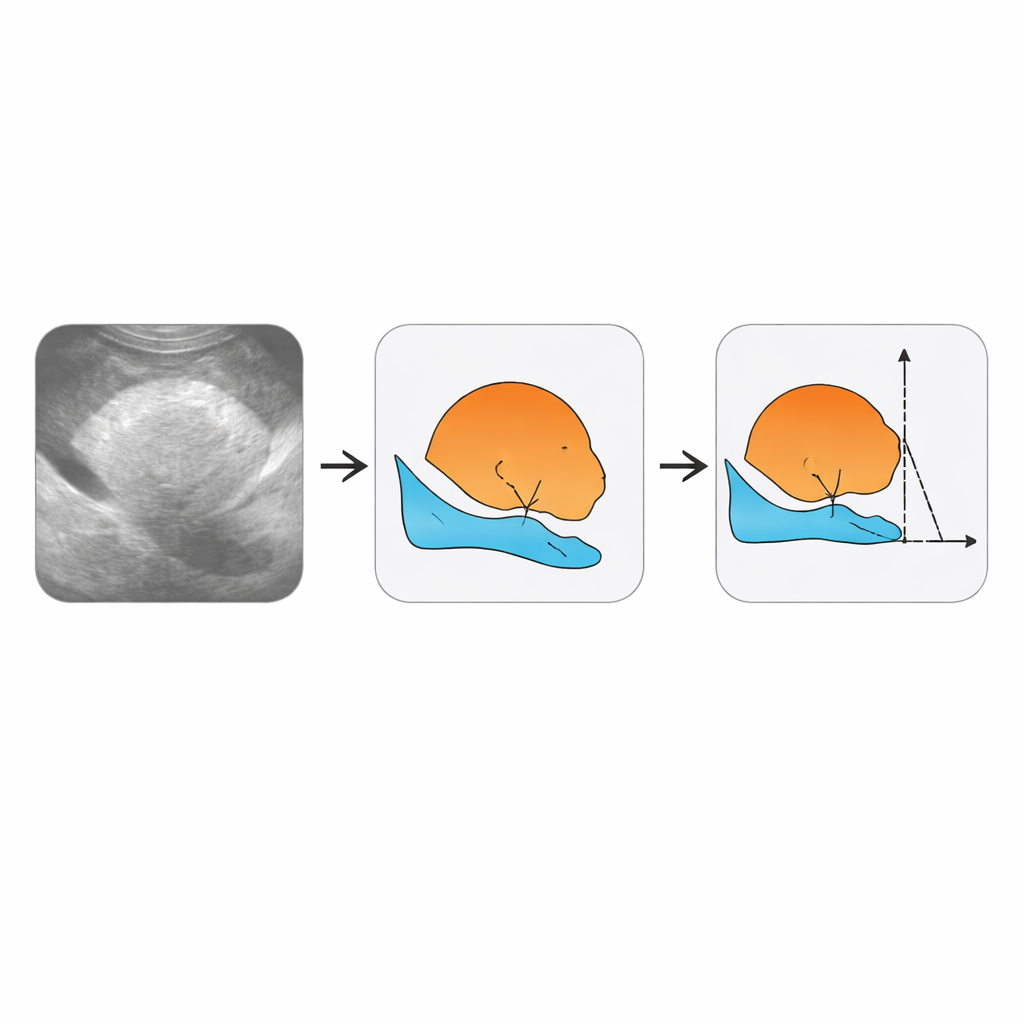
Verifiering av att mänskliga etiketter är tillförlitliga
Eftersom datormodeller endast kan vara lika pålitliga som exemplen de lär av lade teamet ner avsevärda insatser på att testa hur konsekvent olika experter märkte samma videor. Tre annotatörer från de deltagande sjukhusen granskade oberoende en gemensam uppsättning om 150 videor. Forskarna jämförde sedan varje persons arbete med en sammansatt ”konsensus”‑standard. För breda bedömningar — som om en ram visade rätt vy — var överensstämmelsen mycket hög. För att rita konturen av blygdbenet var också konsekvensen stark. Segmentering av fostrets huvud och härledning av exakta vinkel‑ och avståndsmätningar visade sig vara mer utmanande, vilket speglar den inneboende svårigheten att följa svaga, skuggade kanter i brusiga ultraljudsbilder. Ändå var överensstämmelsen tillräckligt god för att stödja meningsfull träning och testning av nya metoder.
En startuppsättning för smartare förlossningsövervakning
För att hjälpa andra att komma igång tillhandahåller författarna en enkel exempelmodell som först framhäver fostrets huvud och moderns bäckenkam i varje ram, och sedan använder dessa former för att uppskatta de centrala mätningarna. Även om detta baslinjesystem långt ifrån är perfekt visar det hur datamängden kan stödja ”end‑to‑end”‑metoder som går direkt från rå video till kliniskt relevanta siffror. Författarna diskuterar också nuvarande begränsningar, såsom svårigheten att hantera särskilt dålig bildkvalitet och det faktum att även experter ibland är oense om exakt var fostrets huvud slutar. Genom att göra videorna och etiketterna fritt tillgängliga inbjuder de den bredare forskarvärlden att ta sig an dessa utmaningar, med det långsiktiga målet att skapa mer objektiva och lättillgängliga verktyg för att vägleda beslut under förlossning.
Citering: Niu, M., Bai, J., Gao, Y. et al. Maternal-Fetal Ultrasouno Video Dataset for End-to-end Intrapartum Biometry and Multi-task Learning. Sci Data 13, 327 (2026). https://doi.org/10.1038/s41597-026-06900-5
Nyckelord: intrapartum‑ultraljud, förlossningsövervakning, fosterhuvudets nedträngning, AI för medicinsk bildbehandling, klinisk videodatamängd