Clear Sky Science · sv
En enhetlig datamängd för design av antikroppar och nanobodies inklusive sekvens-, struktur- och bindningsstyrkedata
Varför små immunsystemverktyg och stor data spelar roll
Antikroppar och deras mindre släktingar, nanobodies, är kroppens precisionsstyrda missiler mot infektioner och cancer. Läkemedelsutvecklare försöker nu designa dessa molekyler i datorer, precis som ingenjörer designar flygplan. Men fram till nyligen var råmaterialet för sådan artificiell intelligens—pålitliga data om antikroppsdelar, former och hur hårt de binder sina mål—spritt över många oförenliga databaser. Denna artikel presenterar Antibody and Nanobody Design Dataset (ANDD), en enhetlig, offentlig resurs skapad för att ge forskare rena, omfattande data de behöver för att utforma nästa generations riktade terapier.
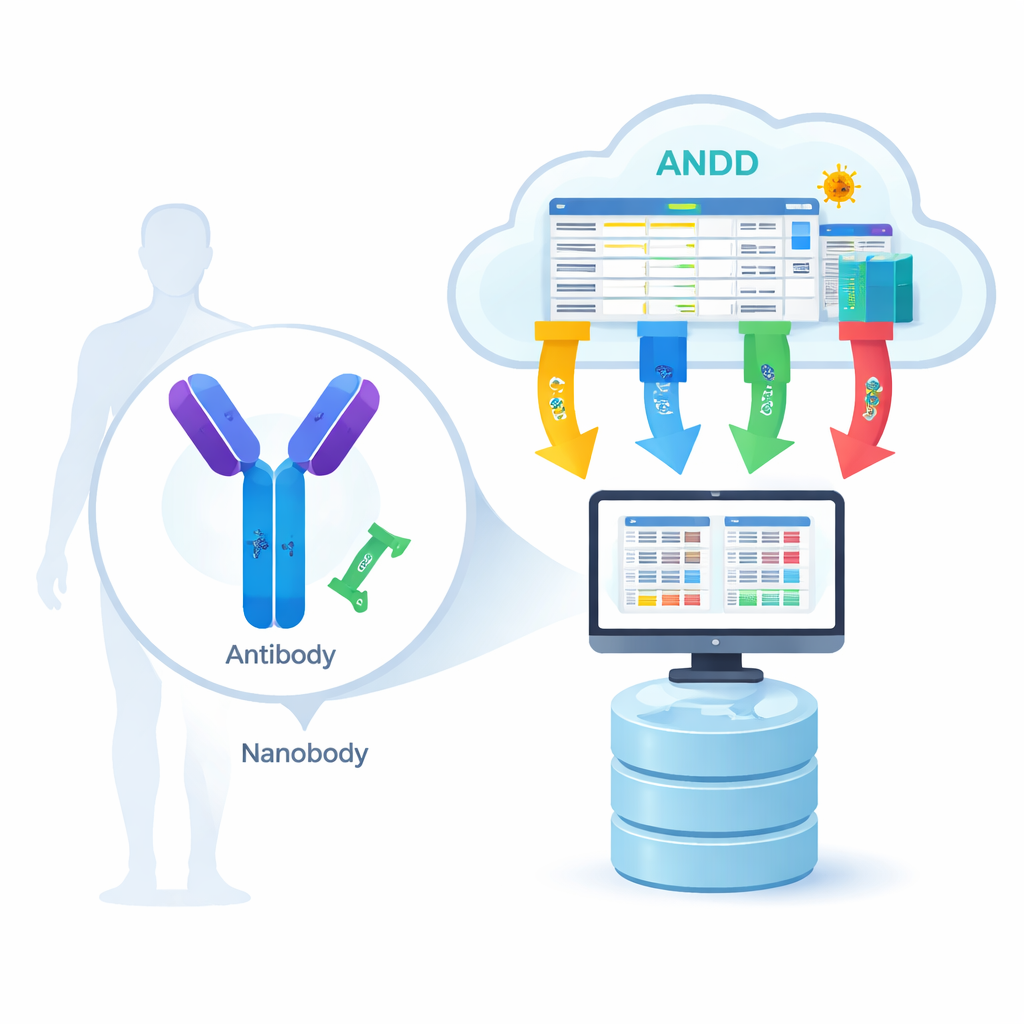
Från biologiskt lås-och-nyckel till digital ritning
Antikroppar är stora Y-formade proteiner, medan nanobodies är mycket mindre enkeldelade versioner som finns hos djur som lamor och alpackor. Båda känner igen specifika “lås” på virus, cancerceller eller andra sjukdomsrelaterade proteiner. För att datorbaserade modeller ska lära sig hur denna igenkänning fungerar behöver de fyra slags information för många olika exempel: aminosyrasekvensen (delarlistan), 3D-strukturen (formen), antigenet (målet) och bindningsstyrkan (hur hårt de två sitter ihop). Fram tills nu fångade de flesta resurser endast en eller två av dessa bitar åt gången, vilket tvingade forskare att hoppa mellan databaser och manuellt pussla ihop informationen—det saktade ner framsteg och gav utrymme för fel.
Att samla spridda bitar i ett organiserat bibliotek
ANDD-teamet samlade data från 15 stora källor, inklusive dedikerade antikropps- och nanobody-databaser, allmänna proteinarkiv och till och med patentdokument. De förde sedan dessa råa indata genom en noggrant skriven pipeline: nedladdning, omformatering till ett gemensamt schema, korskontroll av identifierare, borttagning av dupliceringar och harmonisering av namngivningsregler. När olika databaser var oense prioriterades kurerade källor och direkta experiment. Slutresultatet är en enda tabell plus en uppsättning strukturfiler som kopplar sekvens, struktur, mål och bindningsinformation på ett konsekvent sätt, där varje post är taggad så att användare exakt kan spåra var den kom ifrån och hur den bearbetades.
Lager av detalj för olika forskningsbehov
Inte alla poster i ANDD är lika rika, så författarna organiserade samlingen i lager med ökande detaljrikedom. På den bredaste nivån finns 48 683 antikropps- och nanobody-poster med sekvensinformation. En stor delmängd har dessutom 3D-strukturer, och en mindre delmängd inkluderar vidare sekvenser för målproteinerna. Det mest detaljerade lagret—tusentals poster—lägger till uppmätt eller predikterad bindningsstyrka. För antikroppar har till exempel 18 464 poster sekvenser, samma antal kombinerar sekvens och struktur, över 8 000 inkluderar också antigensekvenser, och 7 737 har fullständig sekvens, struktur, antigen och affinitetsdata. En parallell hierarki finns för nanobodies, vilket ger både experimentella forskare och modellbyggare flexibilitet: de kan välja stora, enkla datamängder eller mindre, mer informationsrika delmängder.
Att fylla i luckorna kring bindningsstyrka
Bindningsstyrka är avgörande för läkemedelsdesign, men experimentella värden är få och rapporterade ojämnt. För att hantera detta utan att sudda ut gränsen mellan data och prediktion använde författarna ett specialiserat djupinlärningsverktyg, ANTIPASTI, för att uppskatta bindningsstyrka endast för poster som hade strukturer men saknade mätningar. Dessa 2 271 predikterade värden är tydligt märkta och hålls åtskilda från de ungefär 7 000 experimentellt uppmätta värdena. Teamet kontrollerade sedan den övergripande konsekvensen med en annan modell, AlphaBind, och genom att jämföra matematiskt relaterade bindningsmått. Starka korrelationer och låga fel tyder på att de kurerade experimentella värdena är tillförlitliga, och att de predikterade värdena följer rimliga trender utan att behandlas som absolut sanning.
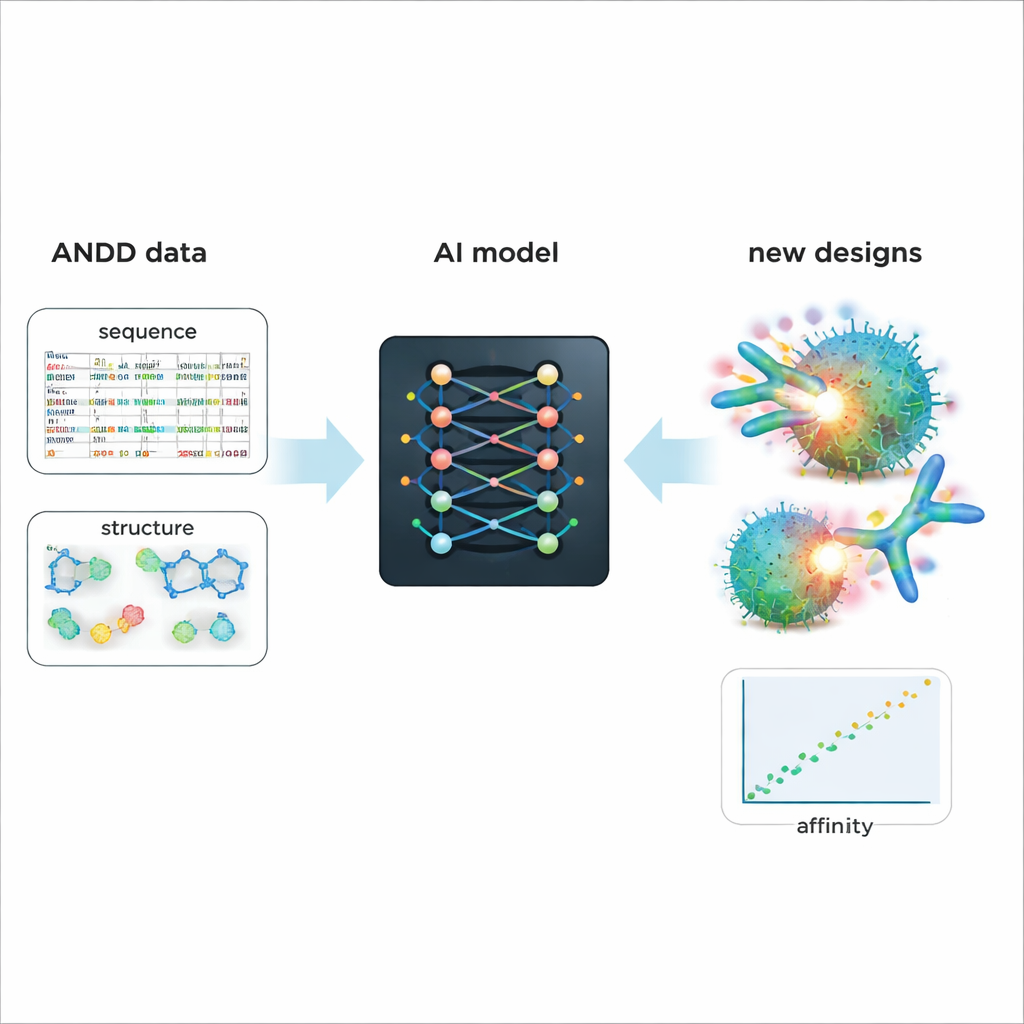
Driva smartare design av framtida läkemedel
För att demonstrera ANDD:s praktiska värde finjusterade författarna en befintlig generativ AI-modell som designar antikroppar och nanobodies. Träning på ANDD:s kombinerade sekvens-, struktur-, mål- och affinitetsinformation ledde till genererade molekyler med bättre förutsagd bindning och mer realistiska former än en baslinjemodell tränad på äldre, enklare data. Utöver denna fallstudie är ANDD öppet tillgängligt under en generös licens, levereras med full dokumentation och en reproducerbar byggpipeline, och är utformat för att uppdateras regelbundet. För icke-specialister är huvudbudskapet att ANDD förvandlar ett rörigt lapptäcke av antikroppsdata till ett sammanhängande, trovärdigt bibliotek—vilket ger AI-verktyg en betydligt bättre utgångspunkt för att designa precisa, mer effektiva biologiska läkemedel.
Citering: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Nyckelord: antikroppsdesign, nanobodies, bindningsstyrka, biologiska läkemedel, AI-läkemedelsupptäckt