Clear Sky Science · sv
En storskalig datamängd med perifera blodceller för automatiserad hematologisk analys
Varför bilder av blodceller spelar roll
Varje rutinblodprov döljer en mikroskopisk värld av celler som kan avslöja infektioner, anemi eller till och med blodcancer långt innan symtom blir uppenbara. Läkare undersöker traditionellt dessa celler med blotta ögat under mikroskopet — ett noggrant men tidskrävande hantverk. Denna studie presenterar en mycket stor, noggrant märkt samling av bilder på blodceller avsedd att lära datorer att känna igen dessa celler automatiskt. Målet är att göra framtida blodprov snabbare, mer konsekventa och mer tillgängliga genom att ge artificiell intelligens den visuella erfarenhet som behövs för att hjälpa läkare att tolka blodutstryk korrekt.
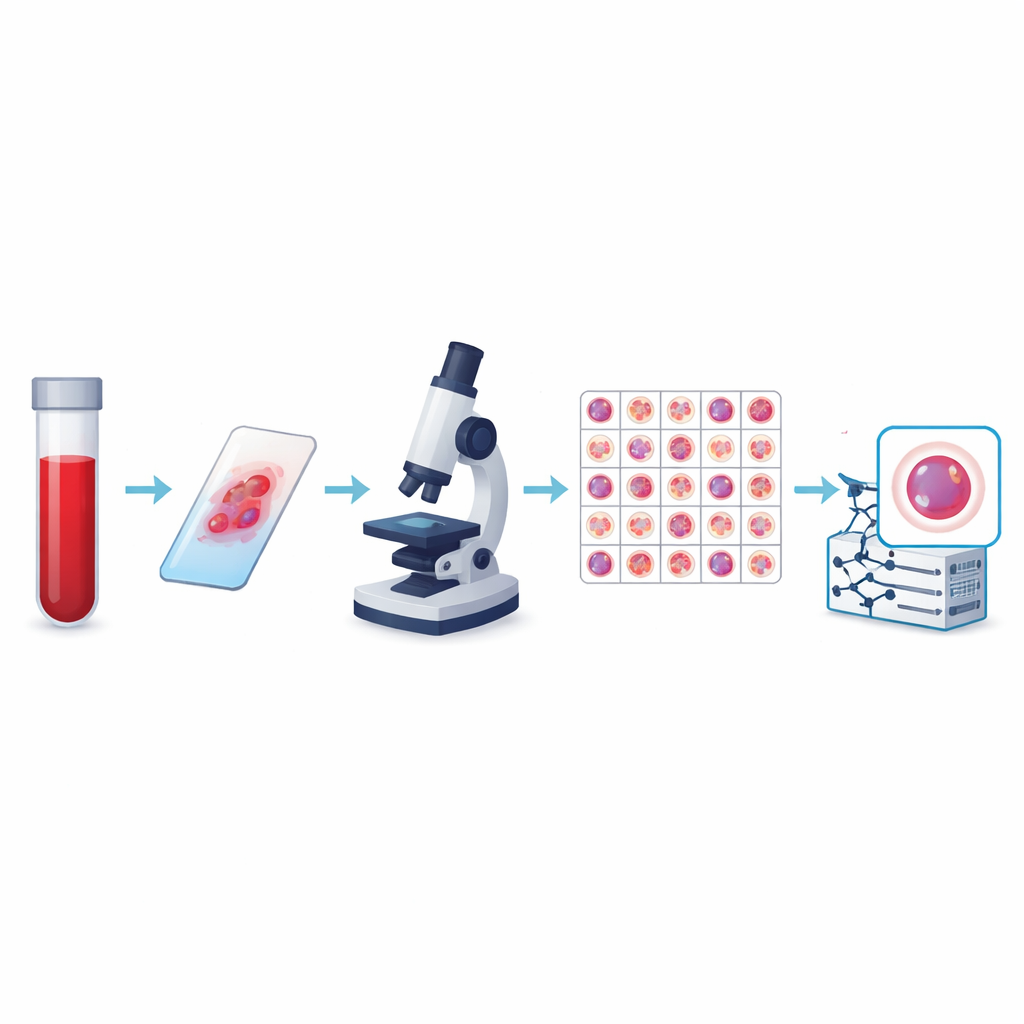
Från enkla räkningar till smart bildanalys
Vita blodkroppar är nyckelns försvarare i vårt immunförsvar, och deras sammansättning och utseende ger viktiga ledtrådar om vår hälsa. En ökning av vissa celltyper kan signalera infektion eller allergi, medan ett plötsligt inslag av omogna ”blast”-celler kan varna för leukemi. Laboratorier använder redan automatiska maskiner för att räkna celler, men subtila formförändringar kräver ofta fortfarande en experts öga. Mänskliga granskare kan vara oense, och att gå igenom preparat ett för ett tar tid. Allteftersom medicinen lutar allt mer mot digital bildanalys och artificiell intelligens växer behovet av stora, pålitliga bildsamlingsregister som kan träna datorer att upptäcka dessa karaktäristiska cellmönster lika pålitligt som en erfaren hematolog.
Att bygga ett jättelikt bibliotek av blodceller
Författarna skapade vad som för närvarande är den största offentliga samlingen av bilder på perifera blodceller, kallad KU-Optofil PBC-datamängden. Den innehåller 31 489 högupplösta bilder av enskilda celler fördelade på 13 grupper, inklusive vanliga försvarare som lymfocyter och segmenterade neutrofiler, samt mer ovanliga men medicinskt viktiga typer som blaster, myelocyter och reaktiva lymfocyter. Alla bilder kommer från infärgade blodutstryk framställda under standardiserade förhållanden på ett enda sjukhus med samma avbildningssystem. Denna konsekvens innebär att datorer som lär sig från datan får en stabil, välkontrollerad bild av varje celltyp istället för ett lapptäcke av inkompatibla bilder.
Experternas ögon och noggrann kuration
För att göra datamängden trovärdig märktes varje bild oberoende av två erfarna laboratorietekniker, och en tredje expert löste eventuella oenigheter. Statistiska kontroller visade mycket stark överensstämmelse mellan granskare för varje huvudcelltyp, inklusive perfekt överensstämmelse för vissa. Teamet tillämpade också strikta regler för vilka bilder som skulle behållas, och sorterade bort suddiga, överlappande eller dåligt infärgade celler. De slutliga bilderna har alla samma storlek och färgformat, och de är organiserade i tränings-, validerings- och testmappar så att andra forskare kan jämföra algoritmer på ett rättvist sätt. Ytterligare filer länkar varje bild till en anonym patient, vilket möjliggör studier som testar om en modell verkligen generaliserar från en person till en annan.
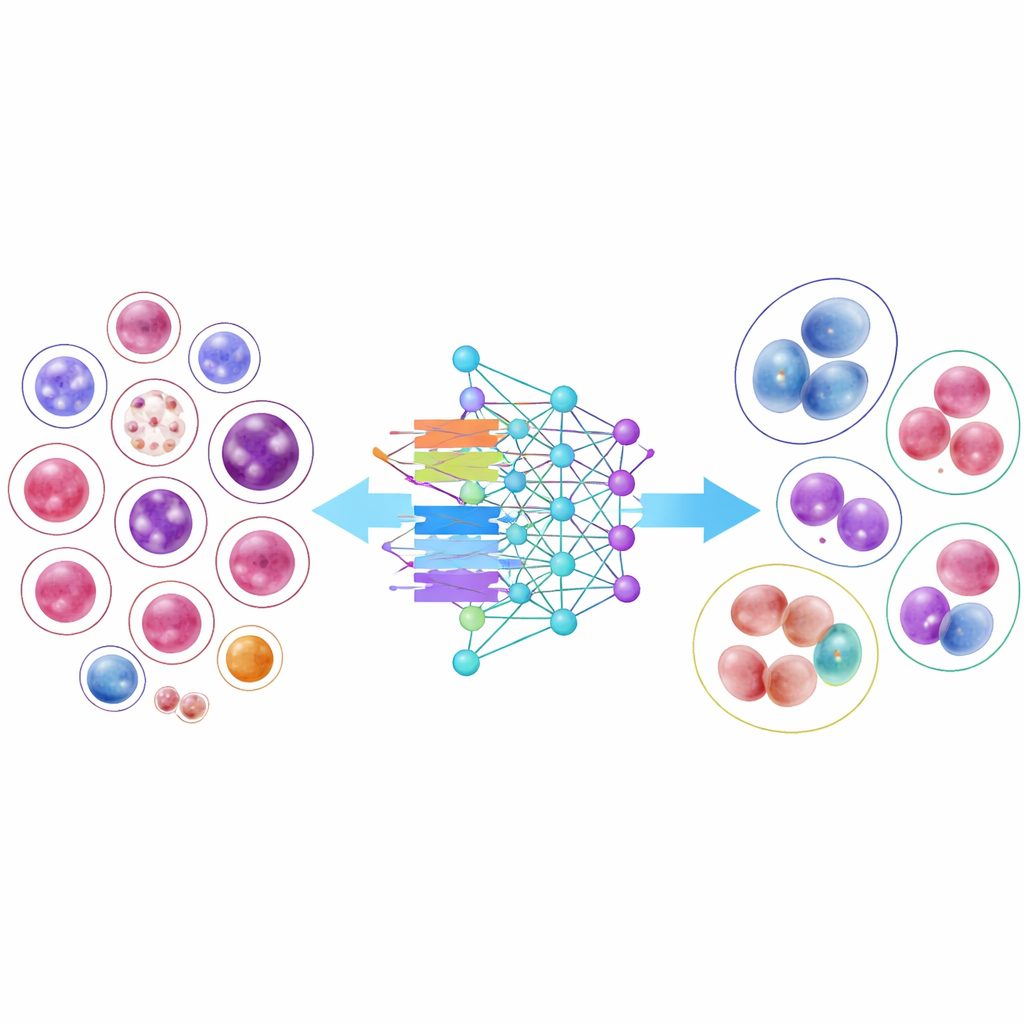
Att sätta AI-modeller på prov
För att visa hur användbart detta bibliotek kan vara tränade forskarna 14 moderna bildigenkänningsmodeller, från klassiska konvolutionella neurala nätverk till nyare design baserade på transformrar. Flera kompakta, effektiva modeller presterade förvånansvärt väl, och en arkitektur, DenseNet-121, klassificerade celler korrekt mer än 95 procent av gångerna i genomsnitt. Resultaten lyfte dock också fram en viktig verklighetsutmaning: vanliga celltyper med tusentals exempel kändes igen nästan perfekt, medan mycket sällsynta celler med bara några dussin bilder fortsatte att vara betydligt svårare att klassificera. Även när forskarna anpassade träningen för att ”ge mer uppmärksamhet” åt dessa knappa klasser sjönk den totala noggrannheten, och vinsterna för sällsynta typer var blygsamma, vilket understryker svårigheten att lära sig från begränsade exempel.
Vad detta betyder för framtida blodtester
För icke-specialister är huvudbudskapet att detta arbete tillhandahåller den råa visuella erfarenhet som datorsystem behöver för att bli pålitliga partners vid tolkning av blodutstryk. Genom att sammanställa ett stort, mångsidigt och noggrant granskat bibliotek av bilder på blodceller och visa att många olika AI-modeller kan lära sig från det, lägger författarna grunden för verktyg som kan snabba upp diagnostik, minska mänskliga misstag och utöka expertanalys till kliniker med färre specialister. Samtidigt påminner de blandade resultaten för sällsynta celltyper oss om att även stora datamängder har blinda fläckar, och att förbättrad vård för patienter med ovanliga eller tidiga sjukdomsstadier kräver att dessa bildsamlingar utökas och förfinas ytterligare.
Citering: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Nyckelord: bildtagning av blodceller, medicinsk AI, hematologi, djupinlärning, medicinska datamängder