Clear Sky Science · sv
En uppsättning histopatologiska bilder i hög förstoring för diagnostik och prognos av skivepitelcancer i munhålan
Varför denna forskning är viktig
Muncancer kan dölja sig i öppen dager, börja som ett litet sår i munnen och utvecklas till en livshotande sjukdom. Läkare förlitar sig på mikroskopbilder av vävnad för att avgöra hur allvarlig en tumör är och hur sannolikt det är att den återkommer eller sprider sig, men att läsa dessa bilder är ett långsamt och krävande arbete. Denna studie presenterar en rik ny bildsamling avsedd att hjälpa artificiella intelligens (AI)-system att läsa dessa preparat tillsammans med patologer, med det långsiktiga målet att ge patienter snabbare och mer tillförlitliga svar om sin sjukdom och behandlingsalternativ.
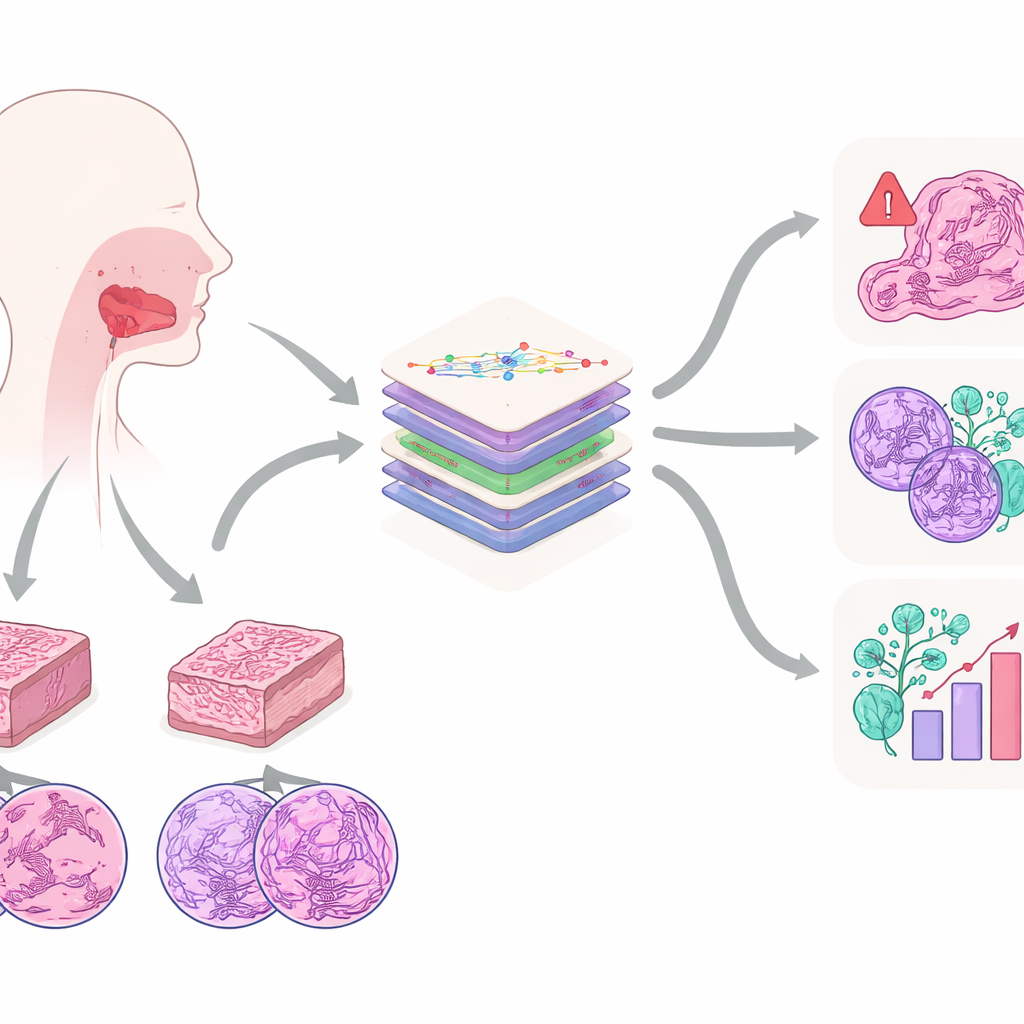
Närmare på en vanlig munhålecancer
Arbetet fokuserar på skivepitelcancer i munhålan, en av de vanligaste och mest aggressiva cancerformerna i munnen. Den uppstår ofta hos personer med historia av tobak- eller alkoholbruk och kan sprida sig till omgivande vävnader och lymfkörtlar i nacken. I dag är fortfarande patologens öga på färgade vävnadssnitt under mikroskop guldstandarden för diagnos. Från dessa snitt bedömer experter hur onormala cellerna ser ut, hur djupt tumören har växt, om den invaderat nerver eller blodkärl och många andra egenskaper som påverkar överlevnad. Författarna hävdar att dessa mikroskopiska mönster innehåller mycket mer information än vad någon människa enkelt kan hålla reda på, vilket gör dem till ett idealiskt mål för modern AI.
Bygga en rikare bild från vävnadsbilder
För att låsa upp denna information skapade teamet datasetet Multi‑OSCC: mikroskopbilder från 1 325 patienter behandlade för muncancer vid ett enda sjukhus mellan 2015 och 2022. För varje patient förberedde patologer två vävnadsblock—ett från tumörens centrum och ett från dess invasiva kant—och fångade sedan högupplösta bilder på tre zoomnivåer, liknande att betrakta en stad från ett flygplan, ett hustak och ett gatuhörn. Detta gav sex noggrant utvalda bilder per patient, var och en innehållande nyckelstrukturer såsom cancercellsholmar, keratininlagringar och starkt onormala cellkärnor. Parallellt med bilderna samlade forskarna detaljerade journaldata och långsiktig uppföljning för att se vilka tumörer som kom tillbaka eller spridde sig.
Sexton frågor läkare verkligen bryr sig om
Vad som särskiljer Multi‑OSCC är att det speglar verkliga kliniska frågor snarare än att fokusera på en enda etikett. Varje patient i datasetet annoterades för sex viktiga utfall. Ett är om tumören återkom inom två år efter operation, ett kritiskt fönster när de flesta recidiv inträffar. Ett annat är om cancerceller redan nått lymfkörtlarna i nacken, vilket styr beslut om omfattande nackkirurgi. Fyra ytterligare etiketter fångar hur väl differentierade tumörcellerna är, hur djupt tumören invaderar, och om den trängt in i blodkärl eller vuxit längs nerver—subtila men kraftfulla ledtrådar till hur farlig cancern är. Denna utformning tillåter AI-modeller att lära sig inte bara “cancer kontra normal”, utan en mer komplett bild av risk och svårighetsgrad.
Att lära AI läsa komplexa preparat
Forskarna utvärderade sedan hur olika AI-strategier hanterar detta krävande dataset. De jämförde flera moderna bildigenkänningsbackbones, inklusive både klassiska konvolutionsnätverk och nyare transformerbaserade modeller, och fann att transformermodeller förtränade specifikt på patologibilder presterade bäst överlag. De testade sätt att kombinera information från de sex bilderna per patient och upptäckte att en enkel strategi—att extrahera funktioner från varje bild och sedan sammanfoga dem—överträffade mer invecklade fusionsscheman. De undersökte också hur färgstandardisering av infärgningarna påverkade prestanda, och visade att bevarande av ursprunglig färg var avgörande för att förutsäga återfall, medan mild färgnormalisering hjälpte för de andra diagnostiska uppgifterna.
Begränsningar, överraskningar och vad som kommer härnäst
En överraskning var att träna en enda AI-modell för att hantera alla sex frågorna samtidigt ännu inte slog modeller som tränats separat för varje uppgift. En annan var att detaljerade mikroskopiska utsnitt, trots rik cellulär information, fortfarande saknar den breda arkitektoniska överblicken som helglasbilder ger. Ändå presterade modeller tränade på Multi‑OSCC:s bilder tydligt bättre än modeller som endast använde kliniska data såsom ålder, vanor och medicinsk historia, särskilt för att förutsäga tumöråterfall. Författarna positionerar Multi‑OSCC som en startpunkt: ett publikt, väl dokumenterat dataset som andra kan använda för att utveckla och jämföra metoder. För patienter är det långsiktiga löftet att framtida verktyg byggda på denna resurs kan hjälpa läkare att mer pålitligt upptäcka vilka muncancerformer som sannolikt kommer att återkomma eller sprida sig, vilket leder till mer skräddarsydda behandlingar och i slutändan bättre överlevnadschanser.
Citering: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Nyckelord: muncancer, histopatologiska bilder, artificiell intelligens, djuplärande, dataset för medicinsk bildbehandling