Clear Sky Science · sv
StatLLM: Ett dataset för att utvärdera stora språkmodellers prestanda i statistisk analys
Varför detta är viktigt för vardagliga dataanvändare
När artificiella intelligensverktyg, som chattbaserade assistenter, blir en del av det dagliga arbetet ber fler människor dem att räkna, köra experiment och analysera data. Men när en AI skriver koden för en statistisk studie—till exempel för att kontrollera om en ny medicinsk behandling fungerar eller för att undersöka skolprestationer—hur kan vi veta att den gjorde jobbet korrekt? Denna artikel introducerar StatLLM, ett offentligt dataset utformat för att testa hur väl stora språkmodeller hanterar verkliga statistiska analystasker, och ger forskare och praktiker en tydligare bild av när man kan lita på AI-genererad kod och när man bör vara försiktig.
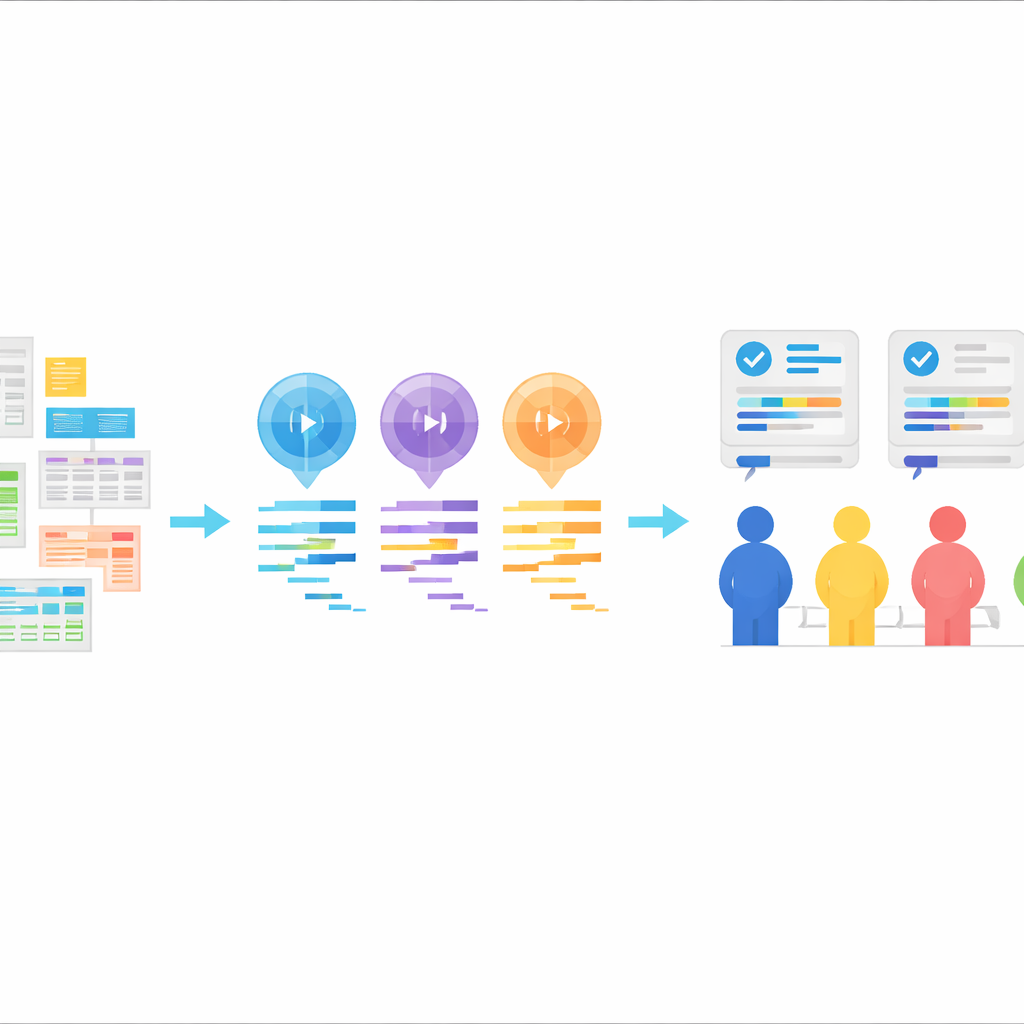
En ny testbädd för AI-genererad statistikkod
Kärnan i StatLLM är en noggrant sammansatt samling av 207 statistikanalysuppgifter byggda från 65 verkliga dataset hämtade från områden som utbildning, medicin, affärsliv, finans, teknik och sport. Varje uppgift levereras med en vardaglig problembeskrivning, en detaljerad förklaring av datasetet och dess variabler samt ett kort stycke SAS-kod skrivet och kontrollerat av mänskliga experter. Uppgifterna omfattar vad en stark kandidat på grund- eller masternivå i statistik kan förväntas lära sig: från enkla datasammanställningar och diagram till regression, överlevnadsanalys och mer avancerade metoder. Detta ger ett realistiskt test i klassrums- och branschmiljö för huruvida AI-verktyg kan förstå praktiska frågor och översätta dem till välgrundade analyssteg.
Låta AI skriva koden, sedan betygsätta dess arbete
Användandes dessa uppgifter bad författarna tre stora språkmodeller—GPT-3.5, GPT-4 och Llama‑3.1 70B—att generera SAS-kod. Varje modell fick samma ingredienser: en beskrivning av uppgiften, en beskrivning av datasetet, den faktiska datafilen och en tydlig instruktion att producera SAS-kod. Modellerna användes i ett "zero-shot"-läge, vilket innebär att de inte visades exempel på korrekt SAS-kod i förväg. Deras svar rensades så att endast koden blev kvar, utan förklaringar. Denna uppställning speglar ett vanligt verkligt mönster: en användare beskriver vad de vill ha, AI:n returnerar kod och den koden körs sedan i ett statistikpaket.
Mänskliga experter som guldkanten
För att bedöma hur bra den AI-genererade koden verkligen var organiserade teamet en rigorös mänsklig granskning. Nio erfarna SAS-användare delades in i tre grupper, där varje grupp fokuserade på en del av prestandan: om koden i sig var logiskt korrekt och läsbar, om den fungerade utan fel och om resultaten tydligt och korrekt svarade på den ursprungliga frågan. För varje uppgift blandades SAS-programmen från de tre modellerna så att bedömarna inte visste vilken modell som producerat vilken kod. Poäng sattes på en femgradig skala och kombinerades till en totalpoäng, vilket gav en nyanserad bild av styrkor och svagheter över hundratals modell–uppgiftspar. Dessa expertrecensioner finns nu tillsammans med all kod och alla uppgifter i StatLLM-datasetet.
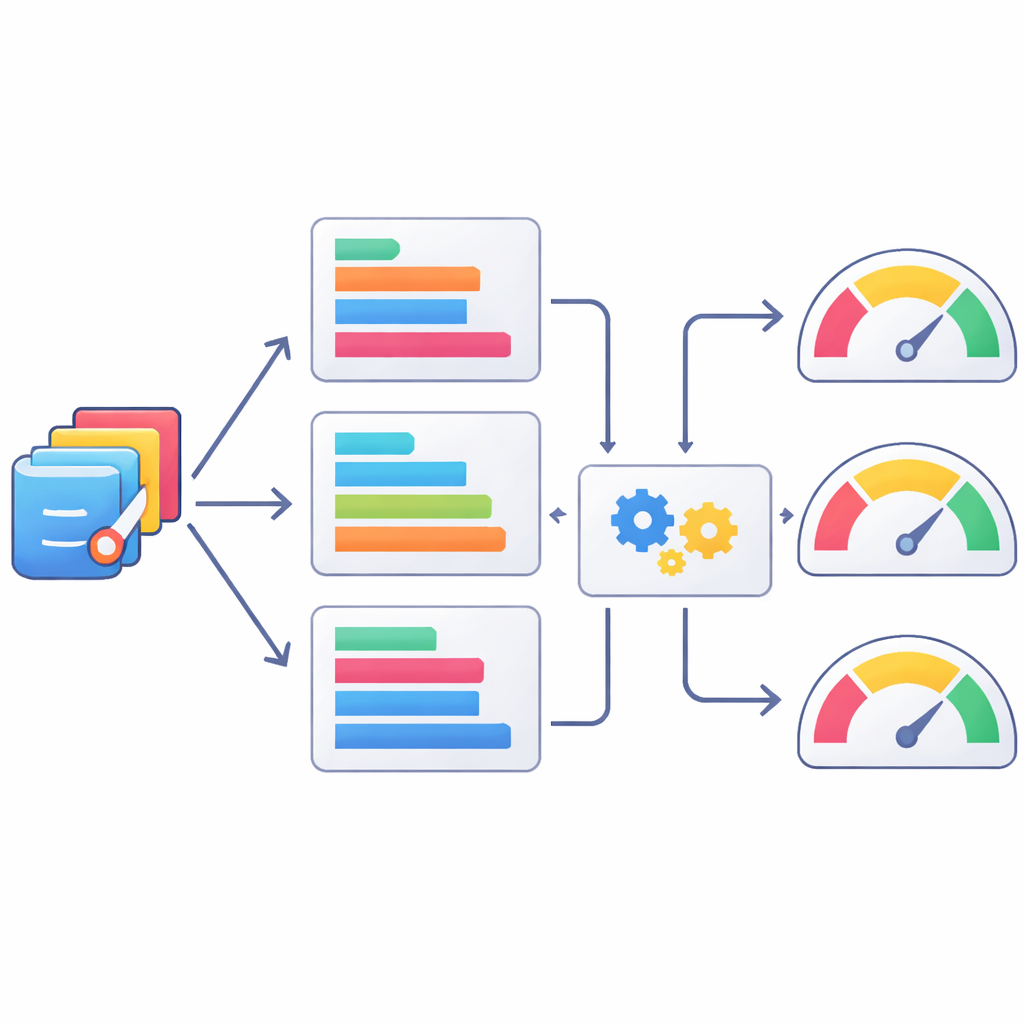
Lära maskiner att bedöma kod som människor
Eftersom mänsklig granskning är långsam och kostsam undersökte författarna också hur väl automatiska textbaserade mått kan fungera som grova domare av kvaliteten på statistikkod. De jämförde AI-genererade SAS-program med de mänskligt verifierade versionerna med hjälp av en uppsättning välkända mått från naturlig språkbehandling, och kontrollerade sedan hur dessa mått stämde överens med de mänskliga bedömningarna. Vissa mått, som varianter av ROUGE som spårar överlappningar i korta tokensekvenser, korrelerade bättre med mänskliga omdömen än andra, men alla var bara måttligt överensstämmande. Teamet gick ett steg längre och tränade maskininlärningsmodeller för att förutsäga människopoäng från kombinationer av dessa mått. Metoder som XGBoost förbättrade överensstämmelsen med de mänskliga bedömningarna, men kom fortfarande långt ifrån att helt fånga experternas omdömen, vilket understryker att automatiska mått högst är partiella ersättare.
Bygga för framtida AI-drivna statistiska verktyg
Utöver benchmarking visar författarna hur StatLLM kan stödja nya verktyg och forskningsriktningar. Eftersom varje uppgift beskrivs i generella termer kan samma problem användas för att testa kodgenerering i andra språk som R eller Python, eller för att kombinera kod från flera språk. Artikeln lyfter fram ensemblemetoder som kan blanda olika AI-genererade lösningar för ökad tillförlitlighet och demonstrerar en prototyp av en R Shiny-app där användare laddar upp ett dataset och en uppgiftsbeskrivning och ett AI-system automatiskt producerar och kör R-kod. StatLLM tillhandahåller också en plattform för att utforma och testa nästa generations statistiska programvara som förstår instruktioner på naturligt språk samtidigt som den hålls till tydliga, mätbara standarder.
Vad detta betyder för användning av AI i dataanalys
För icke-specialister är huvudbudskapet att AI redan kan skriva korta utdrag av statistikkod—men pålitligheten är långt ifrån garanterad, särskilt för uppgifter som går bortom enkla exempel. StatLLM erbjuder ett transparent, återanvändbart sätt att se hur väl olika modeller presterar, att förbättra automatiska kontroller av deras arbete och att utforma säkrare, mer robusta dataanalysverktyg. När nyare språkmodeller dyker upp kan de kopplas in i detta levande benchmark, vilket håller fältet ärligt kring vad AI kan och ännu inte kan göra i seriöst statistiskt arbete.
Citering: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Nyckelord: stora språkmodeller, statistisk analys, kodutvärdering, benchmark-dataset, SAS-programmering