Clear Sky Science · sv
En datamängd med vetenskapliga citeringar i amerikanska patentmyndighetens Office Actions
Varför patentciteringar spelar roll för vardaglig innovation
När du hör om en ny pryl, medicin eller ren energiteknik finns det oftast en pappersspår av idéer bakom. Mycket av det spåret dokumenteras i patent och de källor de hänvisar till. Denna artikel presenterar en stor ny datamängd som visar, med ovanlig detaljrikedom, vilka vetenskapliga arbeten patentgranskare förlitar sig på när de avgör om en uppfinning förtjänar skydd. Genom att öppna detta dolda fönster in i granskningsprocessen ger författarna forskare, beslutsfattare och även nyfikna medborgare ett nytt sätt att studera hur vetenskaplig kunskap driver verklig innovation.
En dold nivå i patentprocessen
De flesta studier av patent tittar endast på de citeringar som står på framsidan av beviljade patent. Dessa listor verkar enkla, men de är slutresultatet av ett komplext fram‑och‑tillbaka mellan sökande och statliga granskare. Under processen skickar granskare formella brev kallade Office Actions, där de förklarar varför ett patent bör godkännas eller avslås och hänvisar till tidigare arbete de anser viktigt. Många av dessa citerade källor, särskilt vetenskapliga artiklar, dyker aldrig upp i det slutliga patentet. Fram till nu har de varit svåra att komma åt i bulk, vilket innebär att forskningen till stor del har förbises detta rika register över hur beslut faktiskt fattas.
Att bygga en ny karta från Office Actions
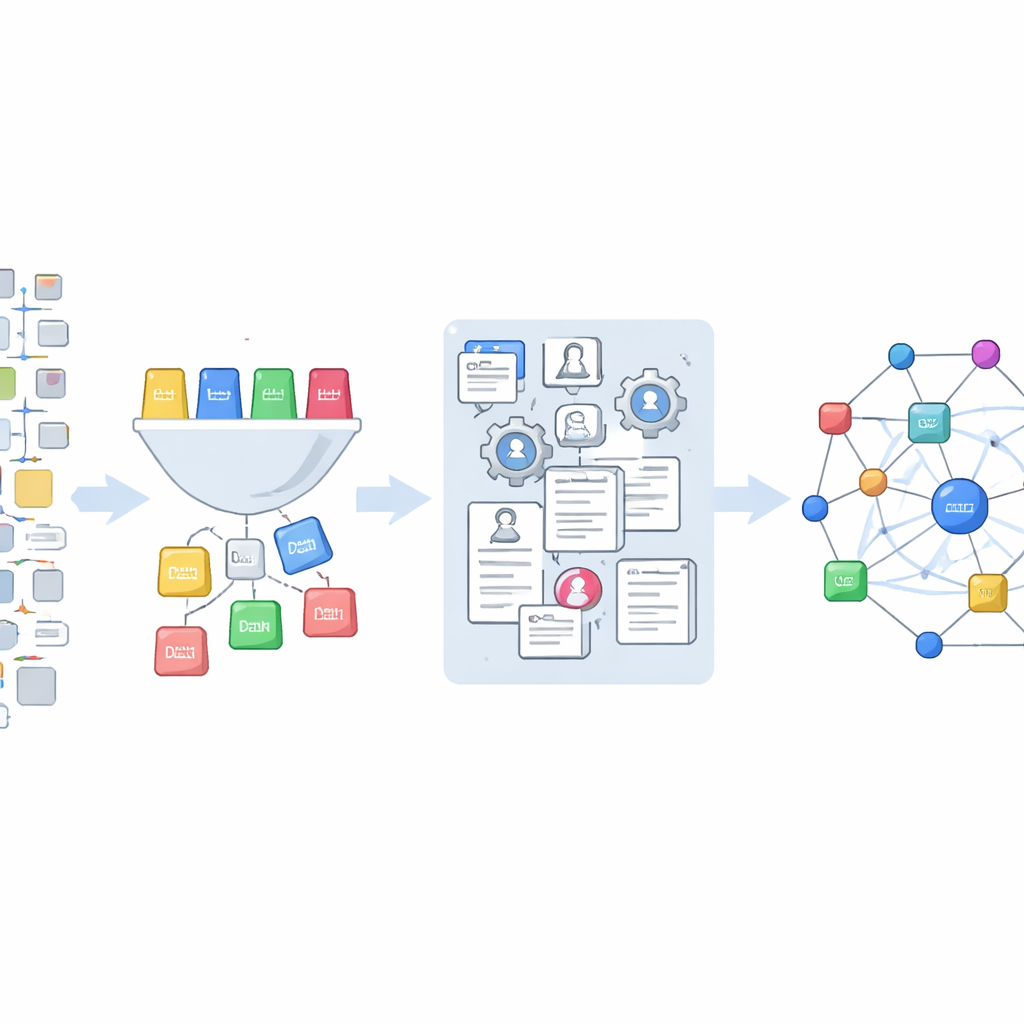
Författarna använder en skattkista av Office Action‑data som släppts av U.S. Patent and Trademark Office och lagras på Google Cloud. Från miljontals referenser isolerar de omkring 850 000 som inte pekar på andra patent utan istället på externa källor som tidskriftsartiklar, böcker, webbplatser och produktmanualer. De utformar ett system med 14 vardagliga kategorier—allt från böcker och konferenshandlingar till webbsidor och produktdokumentation—och tränar sedan en maskininlärningsmodell för att sortera varje citering i en av dessa typer. Denna modell, förfinad med hjälp av exempel märkta med ett avancerat språkverktyg, klassificerar nästan 847 000 unika citeringsträngar.
Från röriga referenser till rena forskningsposter
Att identifiera vilka citeringar som är vetenskapliga är bara första steget. Verkliga referenser är röriga: titlar kan vara ofullständiga, årtal felstavade och sidnummer ihopblandade. För att förvandla denna röra till användbar data matar teamet in de råa strängarna i ett specialiserat verktyg som delar upp dem i delar som författare, år, tidskrift och sidspann, samtidigt som noggranna rensningsregler tillämpas. De matchar sedan dessa rensade poster mot OpenAlex, en stor öppen databas över forskningspublikationer, med två strategier. När en titel finns tillgänglig söker de efter titel och behåller endast högkonfidensmatchningar; när den inte finns förlitar de sig på kombinationer av författarnamn, tidskrift, år och sidor. Om OpenAlex inte hittar en match söker de i stället i Crossref, en annan stor källa för publikationsidentifierare, och går tillbaka till OpenAlex med eventuella upptäckta digitala objektidentifierare.
Hur tillförlitlig är den nya datamängden?
Eftersom denna resurs är avsedd att ligga till grund för framtida studier ägnar författarna betydande arbete åt att testa dess noggrannhet. Deras klassificerare tilldelar referenser till rätt typ i ungefär 92 procent av fallen totalt, och den presterar särskilt väl för de vanligaste klasserna såsom tidskriftsartiklar och patent. För matchningssteget visar manuella kontroller att titelbaserade sökningar blir mer korrekta ju högre matchningspoängen är, och når mitten av 90‑procentintervallet i den bästa gruppen, medan sökningar baserade på detaljerad metadata är korrekta 99 procent av gångerna i ett urval. Korskontroller av poster som återfunnits via Crossref visar också nästintill perfekt överensstämmelse. Författarna är öppna med svagare områden—såsom sällsynta kategorier som avhandlingar eller tekniska rapporter—och uppmuntrar användare att förfina dessa där det behövs.
Nya sätt att studera hur vetenskap driver teknik
Den färdiga datamängden länkar ungefär 265 000 vetenskapliga referenser från Office Actions till enskilda amerikanska patentansökningar och till omfattande publikationsposter i OpenAlex. Detta gör det möjligt för forskare att ställa nya typer av frågor: Hur mycket förlitar sig olika granskargrupper eller teknikområden på vetenskapliga artiklar? Vilka studier anses viktiga under granskningen men faller bort i det slutliga patentet? Bygger övergivna patent på en annan del av den vetenskapliga litteraturen än framgångsrika sådana? Eftersom all kod och data släpps öppet kan andra anpassa verktygen, utöka täckningen och förfina klassificeringarna. I klartext förvandlar detta arbete en obskyr och utspridd uppsättning juridiska dokument till en tydlig, återanvändbar karta över hur vetenskap och teknik möts inom patentsystemet.
Citering: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Nyckelord: patentciteringar, office actions, vetenskaplig litteratur, innovationsdata, OpenAlex