Clear Sky Science · sv
En kinesisk dataset för named entity recognition för immateriellt kulturarv
Varför skyddet av levande traditioner kräver smart läsning
Runt om i världen riskerar levande traditioner som folkmusik, hantverk och lokala festivaler att försvinna ur vardagen. I Kina finns stora mängder text som redan beskriver dessa praktiker, men det mesta ligger i långa webbsidor som både människor — och datorer — har svårt att söka i eller analysera. Denna studie presenterar en noggrant sammanställd dataset på kinesiska och en avancerad artificiell intelligensmodell som automatiskt kan hitta nyckelinformation i texterna, såsom namn på hantverk, mästare, material och platser. Tillsammans erbjuder de nya verktyg för att bevara och studera immateriellt kulturarv i digital skala.
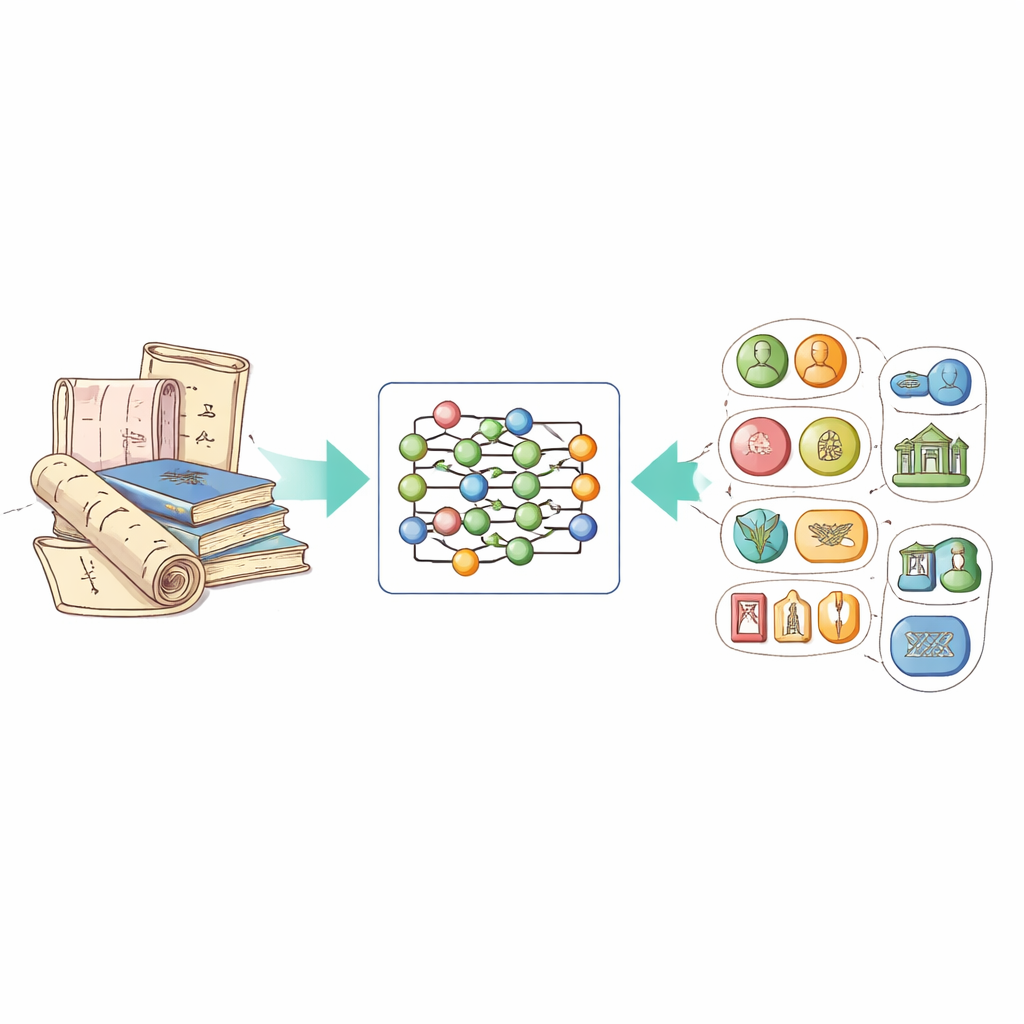
Att omvandla rörig text till organiserad kunskap
Huvudidén bakom arbetet är en teknik som kallas named entity recognition, som lär datorer att markera viktiga element i text: personer, platser, tidpunkter, organisationer och så vidare. För immateriellt kulturarv innebär det också att känna igen särskilda entitetstyper som namn på kulturarvsprojekt, specifika hantverkstekniker och de material som används. Problemet är att det fram till nu saknats en offentlig dataset anpassad till detta domän på kinesiska, och allmänna system kämpade med livfulla beskrivningar, poetiskt språk och regionala uttryck som finns i kulturarvstexter.
Att bygga en fokuserad samling kulturarvstexter
För att fylla detta gap samlade författarna en ny dataset, kallad ICH-NER, från Kinas officiella nätverk för immateriellt kulturarv. De fokuserade på hantverksrelaterade poster — såsom traditionella textilier, keramik, metallarbete och snideri — eftersom dessa beskrivningar är rika på detaljer om processer och material. Efter att ha rensat bort annonser och dubbletter definierade de åtta nyckelkategorier av entiteter: namn på kulturarv, platser, personer, organisationer, tidsperioder, etniska grupper, material och hantverkstekniker. Varje kinesiskt tecken i texterna taggades med en enkel kod som anger om det tillhör en entitet och i så fall vilken typ. Totalt innehåller datasetet 7 779 exempel och mer än 21 000 märkta entiteter, vilket gör det till en stabil referenspunkt för framtida forskning.
Omsorgsfulla regler för konsekvent märkning
Eftersom det saknades ett standardiserat klassificeringssystem för denna typ av kulturarvstexter tog forskarna först fram detaljerade riktlinjer baserade på nationella kulturarvslistor och officiella beskrivningar. De genomförde en pilotfas för att hantera svåra fall, såsom platser som också ingår i projektnamn, eller inbäddade fraser där en entitet ligger inuti en annan. En enda utbildad annotatör märkte sedan hela datasetet med öppen källkodsprogramvara och återbesökte upprepade gånger tidigare arbete för att rätta inkonsekvenser. Slutligen delades data upp i tränings- och utvecklingsset, med omsorg för att behålla liknande andelar av varje entitetstyp och en bra blandning av regionala termer och skrivstilar i båda delarna.
Att designa en AI-modell anpassad till kulturarvsspråk
Parallellt med datasetet föreslår studien en specialiserad igenkänningsmodell som staplar flera moderna AI-komponenter. Först omvandlar en kraftfull språkkodare (RoBERTa) de kinesiska tecknen till kontextkänsliga numeriska representationer som speglar hur ord används i omgivande text. Därefter lär en Kolmogorov–Arnold Network-modul subtila, icke-linjära mönster — till exempel hur vissa material tenderar att kopplas till särskilda tekniker eller regioner. Ett multi-head attention-lager undersöker sedan relationer över hela meningen ur flera vinklar, och slutligen väljer ett avkodningslager den mest sannolika sekvensen av entitets-taggar. Denna arkitektur är utformad för att hantera långa, komplexa meningar fyllda med metaforer och flerskiktiga kulturella referenser.
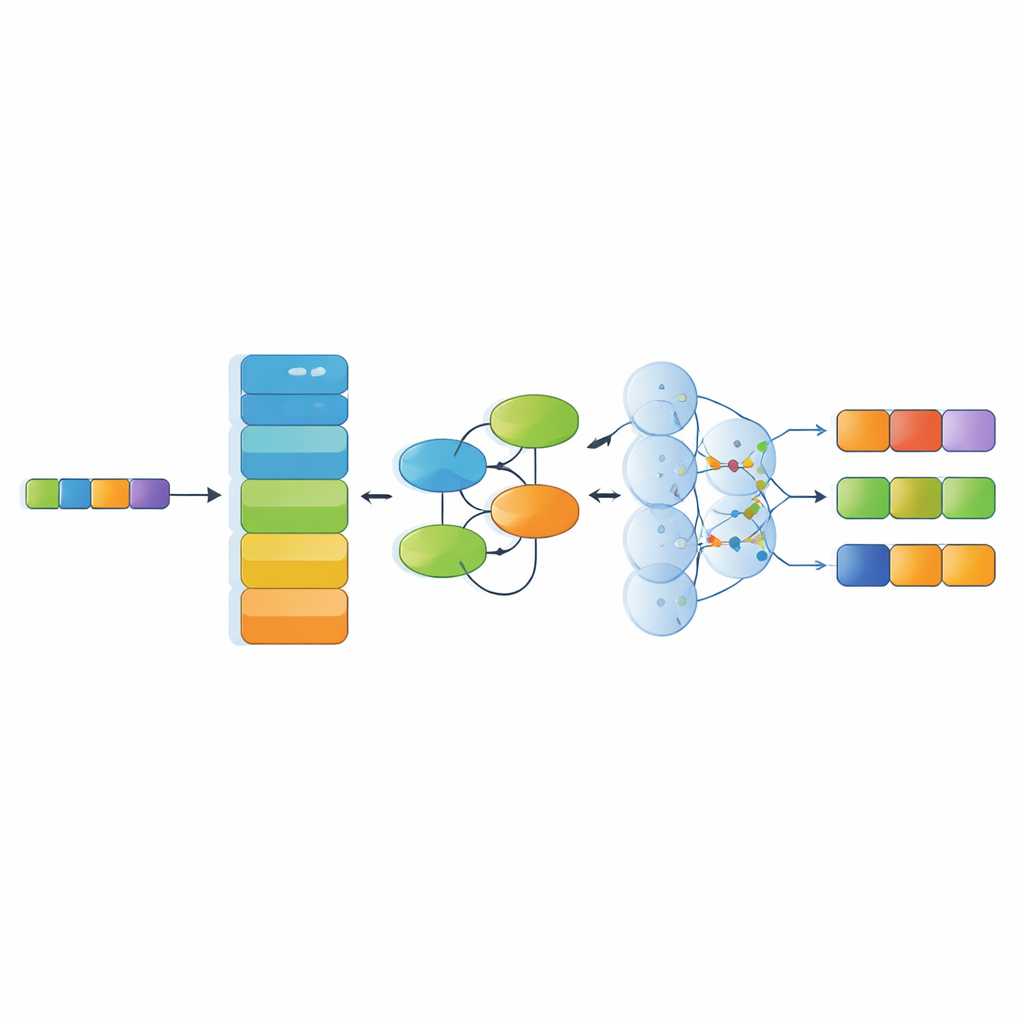
Hur väl systemet förstår kulturarvstext
Författarna jämförde sin modell med flera starka baslinjer som ofta används i språkforskning, inklusive system baserade på återkommande nätverk, gitterstrukturer för kinesisk text och en nyare metod som behandlar entiteter som segment som förfinas steg för steg. På ICH-NER-datasetet presterade metoder som förlitar sig på moderna förtränade språkmodeller tydligt bättre än äldre angreppssätt. Deras kombinerade RoBERTa–KAN–attention–decoder-system uppnådde den bästa totala balansen mellan precision och återkallning, särskilt för utmanande kategorier som material, organisationer och hantverkstekniker, där data är relativt knappa och beskrivningarna ofta är invecklade eller tvetydiga.
Vad detta betyder för levande kultur i den digitala tidsåldern
I praktiska termer gör den nya datasetet och modellen det lättare för datorer att plocka ut vem, vad, var och när ur rika beskrivningar av traditionella hantverk. Denna strukturerade information kan matas in i kunskapsgrafer, interaktiva kartor eller sökverktyg som hjälper forskare, kuratorer och allmänheten att utforska hur tekniker sprids, hur vissa familjer eller regioner formar ett hantverk och hur praktiker utvecklas över tid. Även om arbetet är tekniskt har det en mänsklig påverkan: det erbjuder ett sätt att omvandla spridda, textbundna beskrivningar av levande traditioner till organiserad kunskap som bättre kan stödja bevarandet och förståelsen av immateriellt kulturarv.
Citering: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Nyckelord: immateriellt kulturarv, named entity recognition, kinesisk språkbearbetning, kulturella dataset, digital bevarande