Clear Sky Science · sv
Globalt dataset för emissionsfaktorer för Scope 3‑maskininlärningsapplikationer
Varför det spelar roll att spåra dold koldioxid
Det mesta av klimatpåverkan från moderna företag kommer inte från deras egna skorstenar utan från långa, intrikata leverantörskedjor—allt de köper, säljer, skickar och lägger ut på entreprenad. Dessa så kallade ”Scope 3”‑utsläpp är notoriskt svåra att kartlägga. Artikeln presenterar ExioML, ett öppet globalt dataset och verktyg som omvandlar årtionden av komplexa ekonomiska och miljömässiga register till maskininlärningsklara data. Det gör det mycket enklare för forskare, beslutsfattare och företag att uppskatta var utsläppen verkligen kommer ifrån, jämföra metoder rättvist och utforma smartare klimatåtgärder.
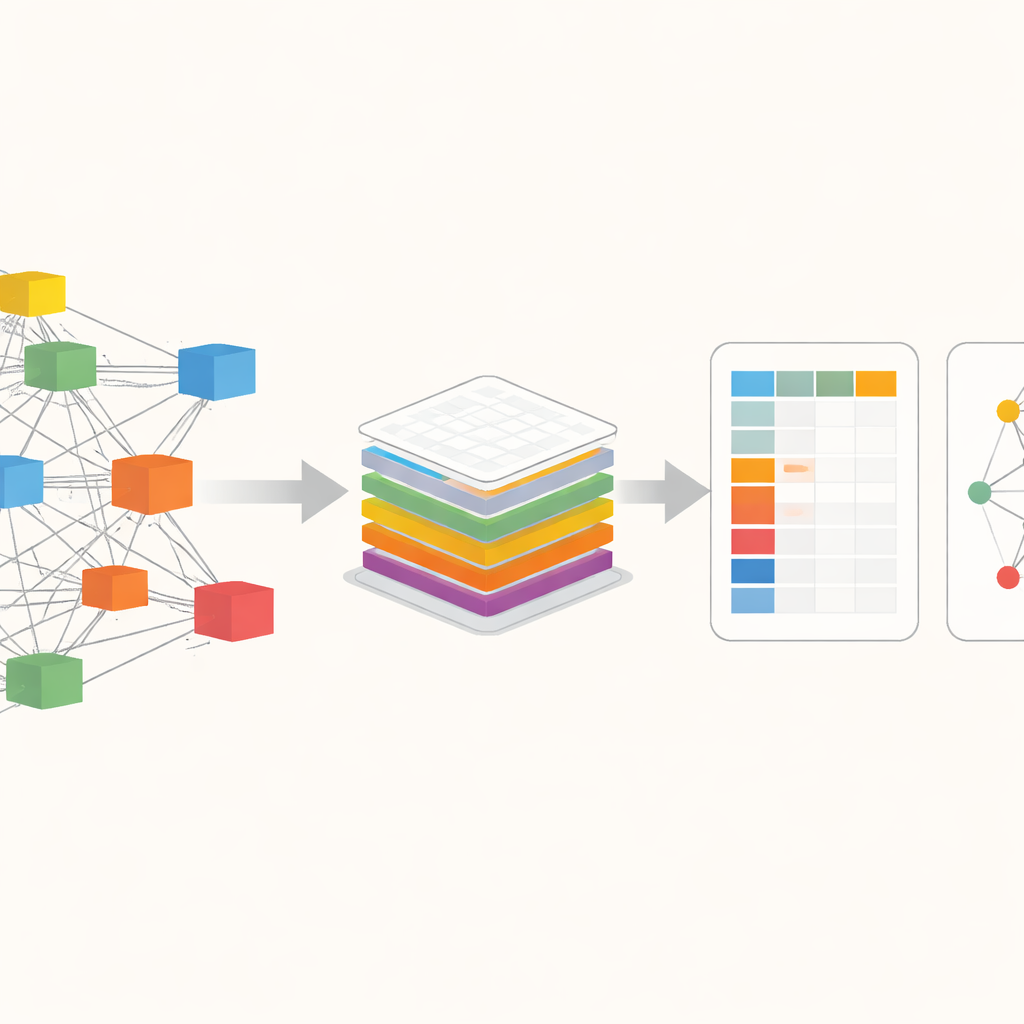
Att se världsekonomin som ett nätverk
I kärnan av ExioML finns ett sätt att betrakta världsekonomin som ett gigantiskt nätverk av branscher som handlar sinsemellan över gränser. I stället för att bara räkna hur mycket koldioxid som släpps ut inom ett land följer denna metod utsläppens spår längs leverantörskedjor: från råvaror, till fabriker, till butiker och slutligen till konsumenter. Befintliga databaser som gör detta är kraftfulla men ofta låsta bakom betalväggar, svåra att använda eller föråldrade. Författarna bygger vidare på en av de mest detaljerade öppna resurserna, EXIOBASE, och omorganiserar den så att vem som helst enkelt kan ställa frågor som: hur mycket växthusgas är kopplad till stålproduktion i ett visst land och år, eller hur utsläpp i en region är inbäddade i produkter som konsumeras någon annanstans.
Att omvandla råa siffror till användbar data
De råa EXIOBASE‑filerna är enorma—över 40 gigabyte med tabeller som beskriver transaktioner mellan hundratals sektorer i flera dussin regioner, plus parallella poster om utsläpp, resurser och energianvändning. Författarna designar ExioML för att destillera denna komplexitet till två huvuddelar. Den första är en ”faktorräkning”‑tabell: ett prydligt strukturerat kalkylblad där varje rad är en specifik sektor i en viss region och år, med kolumner för mervärde, sysselsättning, energianvändning och växthusgasutsläpp. Den andra är ett ”fotavtrycksnätverk”: en förenklad karta över de starkaste handelslänkarna mellan sektorer, som visar hur pengar, energi och utsläpp flyter genom den globala ekonomin. För att producera dessa förlitar de sig på högpresterande grafikprocessorer (GPU:er) för att knäcka de krävande matrisberäkningarna som spårar utsläpp längs leverantörskedjorna, och de standardiserar enheter, sektorkoder och namngivning så att alla 49 regioner och 28 år kan jämföras direkt.
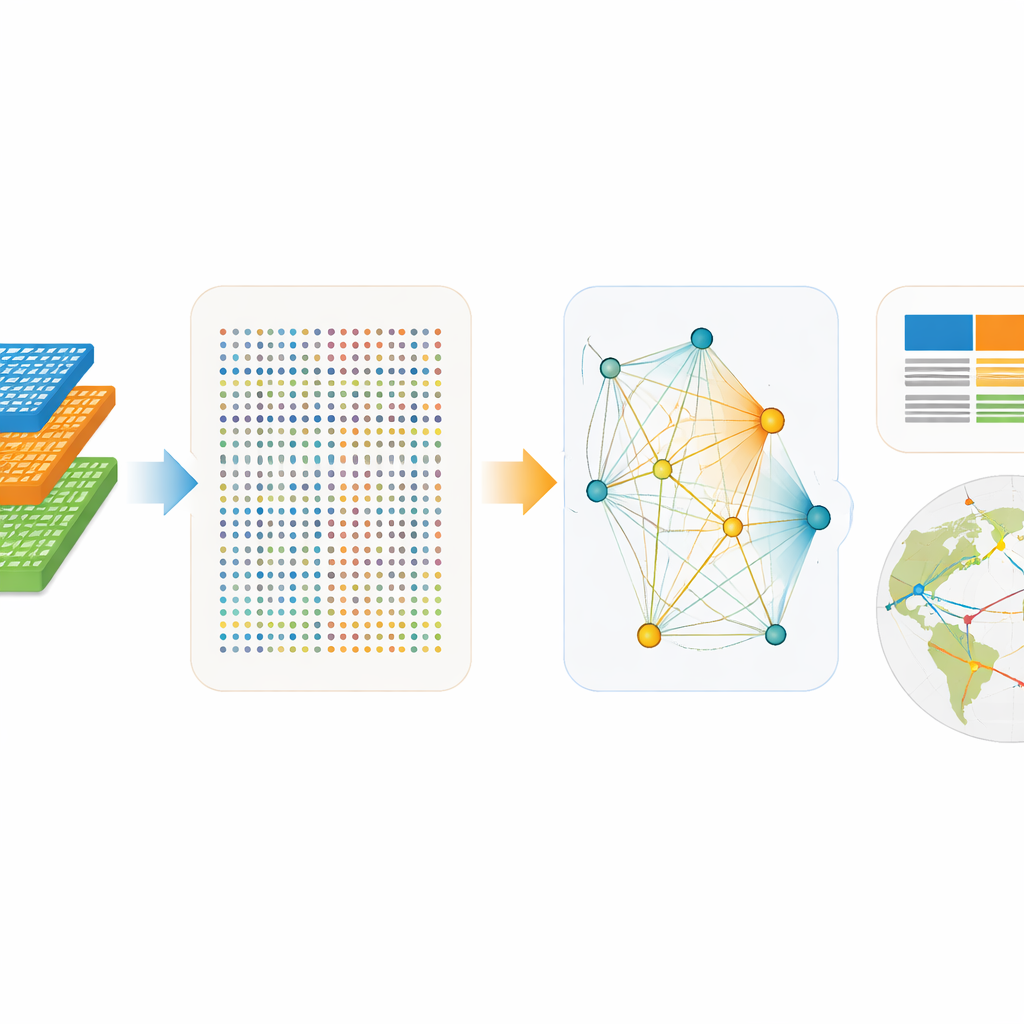
Byggt för modern maskininlärning
ExioML är konstruerat från grunden med maskininlärning i åtanke. Datasets täcker 49 regioner från 1995 till 2022 och erbjuder två kompatibla vyer: en uppdelad i 200 produkttyper och en annan i 163 industrier. Denna struktur gör det möjligt för forskare att behandla varje sektor–region–år som en datapunkt, och kombinera enkla numeriska egenskaper—som befolkning, inkomst per person, energi per produktionsenhet eller utsläpp per energienhet—med kategorisk information om var och vad sektorn är. Författarna publicerar också ett open‑source programvarupaket som kan läsa in datan, generera nätverkssummeringar och till och med leverera färdiga tränings-, validerings‑ och testuppdelningar. Det sänker tröskeln för både klimatforskare och dataforskare som vill bygga modeller utan att först bli experter på specialiserad ekonomisk redovisning.
Testa hur väl modeller kan förutsäga utsläpp
För att visa hur ExioML kan användas ställer författarna upp en benchmark‑uppgift: att förutsäga en sektors växthusgasutsläpp från ett litet antal ekonomiska och energirelaterade indikatorer. De jämför klassiska maskininlärningsmodeller, såsom närmaste granne och träd‑baserade ensemblemetoder, med moderna djupinlärningsmetoder som automatiskt kan lära sig kombinationer av egenskaper. Efter noggrann datarengöring, skalning och uppdelning finner de att enkla linjära modeller har svårt, vilket bekräftar att sambandet mellan produktion, sysselsättning, energianvändning och utsläpp är starkt icke‑linjärt. Träd‑baserade metoder och neurala nätverk presterar båda väl, där en grindad neural modell uppnår bäst noggrannhet. Förbättringen jämfört med väljusterade gradient‑boostade träd är dock måttlig, medan de djupa modellerna tar mycket längre tid att träna och är svårare att finjustera.
Vad det innebär för klimat- och dataarbete
För icke‑specialister är huvudbudskapet att ExioML förvandlar en ogenomskinlig härva av global ekonomisk och miljödata till en gemensam, öppen grund som vem som helst kan bygga vidare på. Företag som försöker förstå klimatpåverkan av sina inköp, forskare som utvecklar algoritmer för att hitta högutsläpps‑hotspots, och analytiker som undersöker hur policy‑ eller teknikförändringar kan påverka framtida utsläpp kan alla arbeta från samma transparanta resurs. Studien visar att med rätt struktur kan även relativt enkla maskininlärningsverktyg fånga mycket av det dolda mönstret i utsläpp över sektorer och regioner. Genom att kombinera öppenhet, teknisk stringens och praktisk programvara hjälper ExioML att föra koldioxidredovisningen från en lapptäcke av privata uppskattningar mot en mer reproducerbar, datadriven vetenskap.
Citering: Guo, Y., Guan, C. & Ma, J. Global emission factor dataset for Scope 3 machine learning applications. Sci Data 13, 348 (2026). https://doi.org/10.1038/s41597-026-06699-1
Nyckelord: Scope 3‑utsläpp, koldioxidredovisning, input–output‑analys, maskininlärning, leverantörskedjans utsläpp