Clear Sky Science · sv
Mot automatiserad rapportering: Ett bronkoskopirapportdatset för att förbättra multimodala stora språkmodeller
Smartare stöd för lungspecialister
När läkare tittar in i luftvägarna med en liten kamera får de mycket information om patientens lungor — men att omvandla det de ser till tydliga, detaljerade rapporter kräver tid och erfarenhet. Denna studie presenterar en ny, omsorgsfullt sammanställd samling av verkliga bronkoskopibilder och rapporter avsedd att lära avancerade AI-system hur de kan hjälpa till med den typen av textproduktion. För patienterna kan detta en dag innebära snabbare, mer konsekventa rapporter och färre risker att viktiga detaljer missas.
Varför undersökning av lungorna är viktig
Bronkoskopi är ett förfarande där ett tunt rör med kamera förs in i luftvägarna för att inspektera luftstrupen och lungornas förgrenade kanaler. Det hjälper läkare att upptäcka problem som inflammation, infektion, tumörer eller blödning, och kan också vägleda behandlingar som att ta bort främmande föremål eller placera små stöd för att hålla luftvägarna öppna. Därefter måste läkaren beskriva vad som observerats i en formell rapport, som blir en del av patientens journal och styr behandlingsbeslut. Att skriva dessa rapporter är ett detaljerat, repetitivt arbete som i hög grad bygger på läkarens utbildning och minne.
Varför befintliga data inte räckte
Under de senaste åren har kraftfulla AI-modeller som kan hantera både bilder och text gjort framsteg i att läsa medicinska avbildningar och utarbeta rapporter. För bronkoskopi har dock de tillgängliga data som använts för att träna sådana system varit smala och ofullständiga. Tidigare dataset täckte ofta bara några få uppgifter — till exempel att upptäcka en tumör eller markera kamerans position — samtidigt som många vardagliga fynd som slem, lätt blödning eller svullnad som läkare rutinmässigt beskriver ignorerades. Vissa samlingar var dessutom privata, små eller fokuserade endast på enkla ja-eller-nej-beslut, vilket gjorde dem olämpliga som undervisningsmaterial för en AI som behöver skriva rika, människoliknande beskrivningar av vad kameran visar.
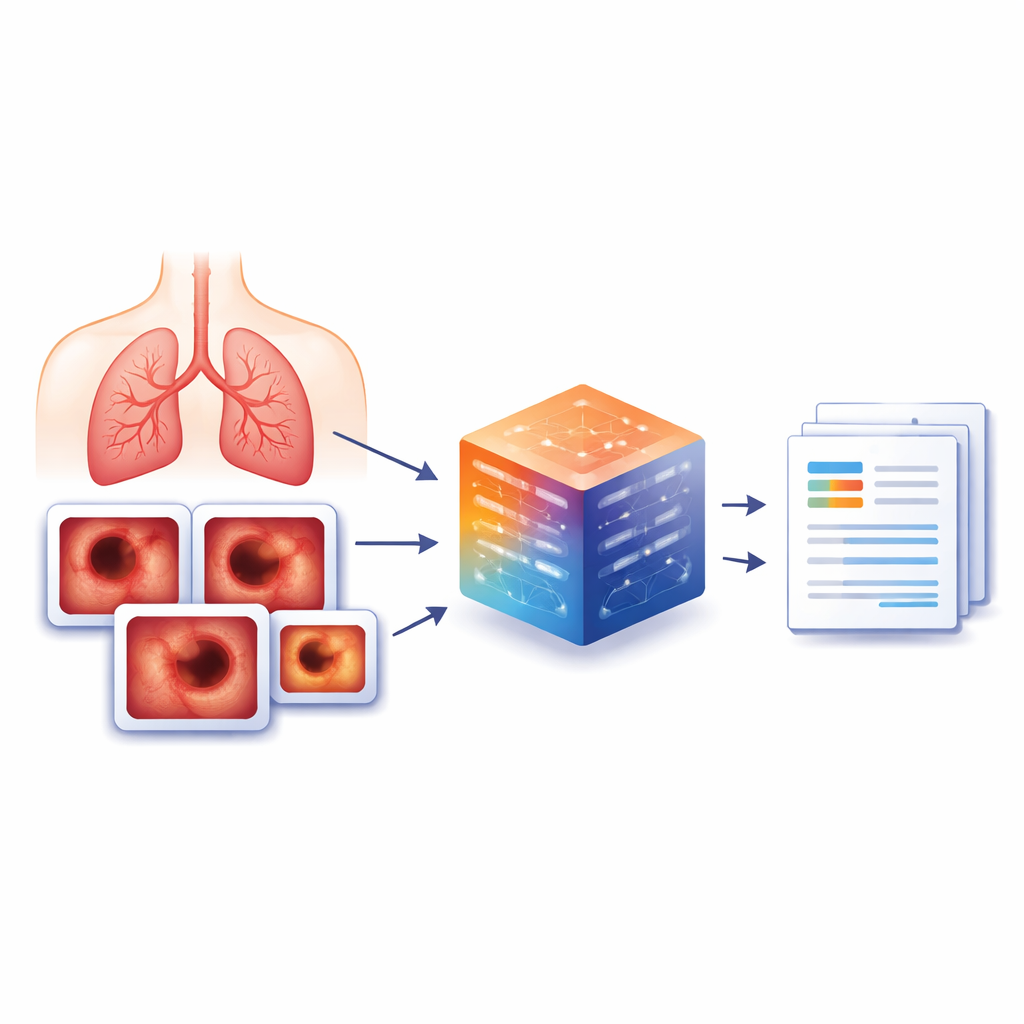
Att bygga ett mer omfattande bildbibliotek
För att täppa till denna lucka skapade författarna BERD, ett nytt dataset för bronkoskopiundersökningsrapporter byggt från verkliga procedurer vid ett större sjukhus i Kina. Av 8 477 bronkoskopier gjorda mellan 2022 och 2023 valdes 3 692 representativa patientfall och 6 330 nyckelbilder som läkare markerat som särskilt informativa. För varje bild kopplade utbildade kliniker den till precisa skriftliga beskrivningar av vad som var synligt, såsom tumörer, svullnad, beläggningar eller normalt vävnad. När en bild inte visade något problem användes en enkel standardfras som ”Det är normalt” för att hålla data konsekvent. Personuppgifter togs bort och de ursprungliga kinesiska rapporterna översattes till engelska med en lokalt körd språkmodell för att skydda integriteten.
Hur experter och AI samarbetade
Utöver rena beskrivningar ville teamet också att varje bild skulle märkas med en eller flera medicinska kategorier — som ”tumör”, ”kongestion” eller ”ödem” — så att AI-modeller kunde lära sig både att kategorisera och att beskriva fynd. För att göra detta effektivt definierade erfarna bronkoskopispecialister först en detaljerad lista med kategorier baserat på medicinska riktlinjer. En lokalt driftsatt språkmodell skannade sedan textbildtexterna för att föreslå vilka kategorier som gällde för varje bild. Människliga experter kontrollerade och korrigerade noggrant dessa förslag och behöll slutgiltig kontroll över den medicinska kvaliteten. Resultatet är en fint annoterad resurs där varje bild kopplas till en tydlig beskrivning, anatomisk plats och expertbekräftade etiketter, allt organiserat i enkla filer som forskare kan använda direkt.
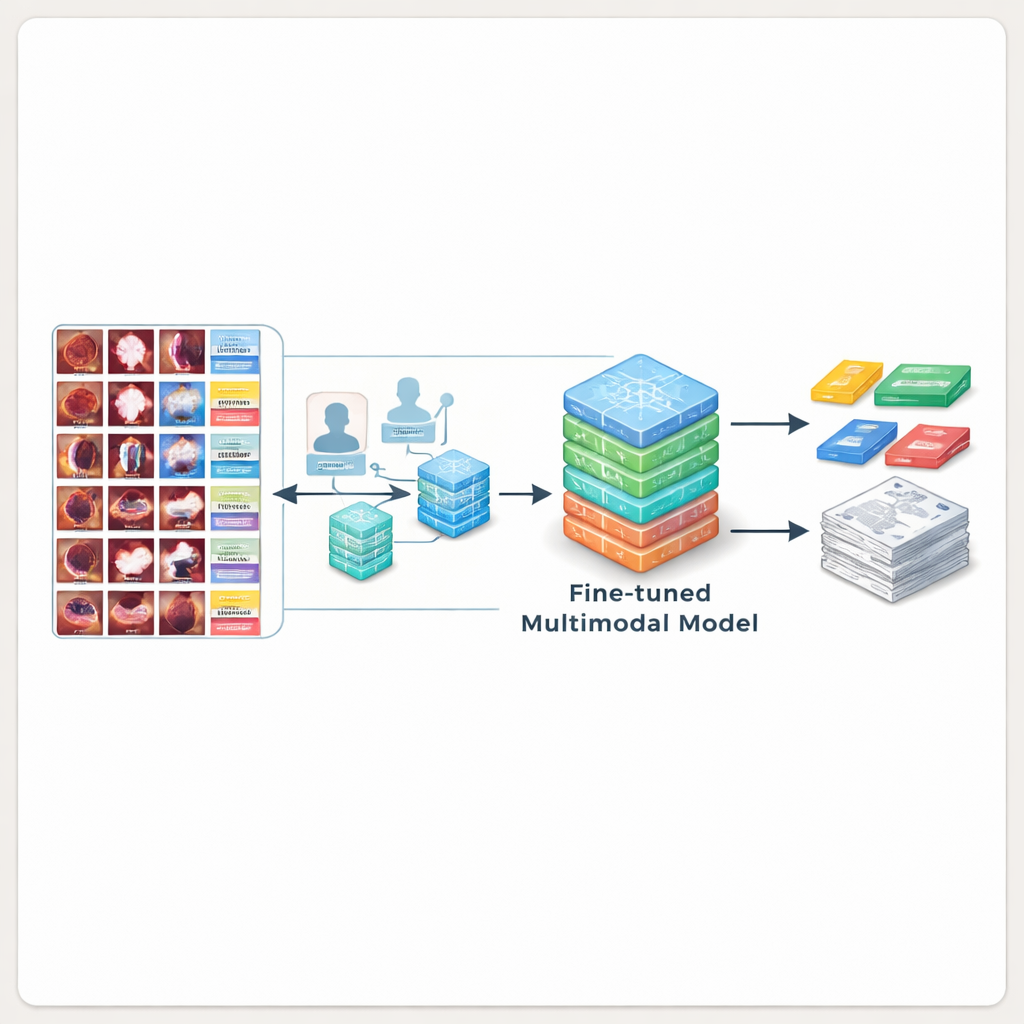
Att lära AI att skriva bättre rapporter
För att visa att BERD verkligen är användbart använde forskarna det för att träna flera ledande multimodala AI-modeller. Först testade de allmänna och medicinska AI-system som aldrig tidigare sett bronkoskopibilder. Dessa modeller missförstod ofta vad de såg, missade tumörer eller hittade på detaljer, och presterade dåligt jämfört med experttexter. Teamet finjusterade sedan open source-modeller på BERD-bilderna och bildtexterna. Efter denna extra träning producerade den bästa modellen beskrivningar som överensstämde mycket bättre med experternas formuleringar och bedömdes acceptabla av kliniker i över 80 % av fallen — vilket innebär att den AI-genererade texten ofta kunde infogas direkt i en riktig rapport med minimal redigering.
Vad detta betyder för framtida vård
Enkelt uttryckt ger detta arbete det saknade ”träningsbiblioteket” som AI-system behöver för att bli pålitliga assistenter vid bronkoskopirapportering. Även om data kommer från ett enda sjukhus och vissa numeriska detaljer medvetet tagits bort för att undvika att vilseleda modellerna, är datasetet offentligt, väl dokumenterat och tillräckligt omfattande för att sätta en ny standard inom området. När forskare bygger vidare på BERD kan patienter så småningom dra nytta av snabbare, mer enhetliga bronkoskopirapporter, vilket ger läkare mer tid att fokusera på beslut och behandling snarare än administration.
Citering: Luo, X., Huang, X., Liang, X. et al. Towards Automated Reporting: A Bronchoscopy Report Dataset for Enhancing Multimodality Large Language Models. Sci Data 13, 339 (2026). https://doi.org/10.1038/s41597-026-06692-8
Nyckelord: bronkoskopi, medicinsk bildbehandling, kliniska rapporter, multimodal AI, medicinska dataset