Clear Sky Science · sv
Biomedical Data Manifest: En lättviktig dokumentationskarta för biomedicinska data som ökar transparensen för AI/ML
Varför smartare dataanteckningar spelar roll för din hälsa
När sjukhus och forskare skyndar sig att använda artificiell intelligens för att förutsäga sjukdom och styra behandling, formar kvaliteten på de data som matar dessa verktyg tyst vem som gynnas — och vem som kan bli lämnad utanför. Denna artikel introducerar ett praktiskt sätt att "märka lådan" för biomedicinska dataset, så att alla som bygger AI-system snabbt kan se var datan kommer ifrån, vilka den representerar och hur den bör — och inte bör — användas. Genom att effektivisera denna typ av dokumentation vill författarna göra medicinsk AI mer rättvis, säkrare och lättare att lita på.
De dolda berättelserna i medicinska data
De flesta stora biomedicinska dataset — samlingar av laboratorieresultat, avbildningar eller behandlingsutfall — skapades aldrig med AI i åtanke. De saknar ofta tydliga register över hur datan samlades in, vilka patienter som inkluderades eller vad som ändrats över tid. Dessa bortfall av detaljer kan dölja snedvridningar, till exempel att vissa grupper är underrepresenterade eller att viktig information registrerats inkonsekvent. När sådan data används för att träna maskininlärningssystem kan de resulterande verktygen fungera bra för vissa patienter men dåligt för andra, vilket förstärker befintliga vårdklyftor. Författarna menar att bättre, standardiserad dokumentation är avgörande för att upptäcka och hantera dessa risker innan algoritmer tas i bruk.
Att kombinera de bästa idéerna i en enkel guide
Flera data"faktablad"-metoder finns redan inom AI-gemenskapen, såsom Datasheets for Datasets, Data Cards och HealthSheets. Var och en erbjuder strukturerade frågor om ett datasets syfte, innehåll, insamlingsmetoder och begränsningar. De var dock mest designade av datavetare för AI-specifika dataset och kan vara långa och svåra för upptagna biomedicinska forskare att fylla i. För att undvika att uppfinna hjulet på nytt kartlade och harmoniserade teamet först fält från fyra mycket citerade mallar och byggde en konsoliderad lista med 136 frågor som fångade de viktigaste begreppen samtidigt som överlappning togs bort. De förfinade sedan listan till 100 fält grupperade i sju intuitiva kategorier, från grundläggande information och hur datan används till frågor som etik, juridiska begränsningar och hur etiketter skapades.
Att lyssna på dem som använder och skapar datan
Därefter bad forskarna verkliga biomedicinska intressenter — inklusive kliniker, laboratorieforskare, datamanagers och beräkningsspecialister — att bedöma hur oumbärliga varje dokumentationsfält var för deras arbete. Tjugotre deltagare från ett multicenter cancerforskningsnätverk genomförde enkäten. Teamet grupperade respondenterna i två breda "personas": de som stod närmare datainsamling vid bänken eller sängkanten, och de som främst hanterar, kuraterar eller analyserar data. Detta visade tydliga skillnader i prioriteringar. Till exempel värderade båda grupperna högt att veta när ett dataset senast uppdaterades och när det kan komma att ändras igen. Men endast datamanagers och beräkningsspecialister prioriterade starkt detaljer om hur etiketter tilldelades eller hur framtida uppdateringar skulle se ut, medan kliniker och bänkforskare lade större vikt vid avsedd användning och olämpliga användningsområden.
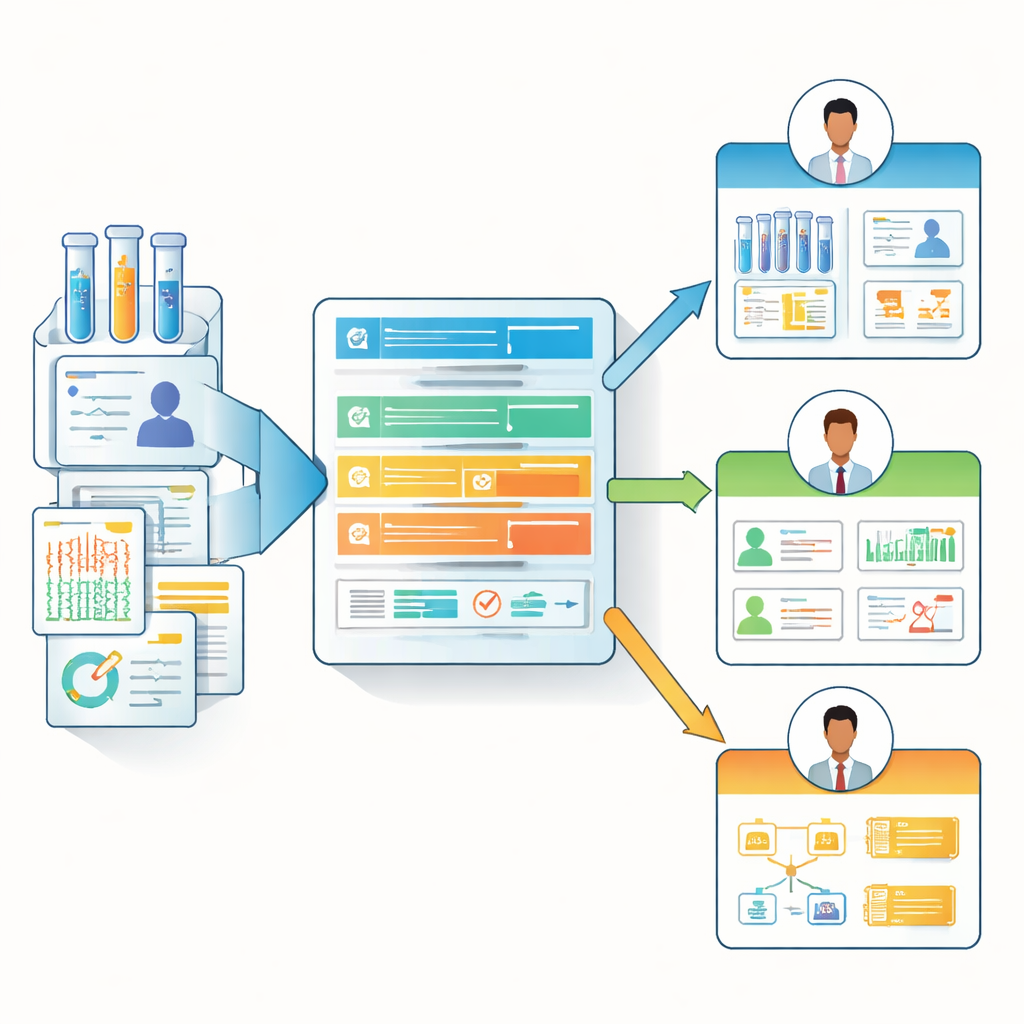
Från en-storlek-passar-alla till rollmedvetna dataanteckningar
Baserat på dessa enkätinsikter designade författarna "Biomedical Data Manifest", en lättviktig, webbaserad dokumentationsmall som anpassar sig efter olika roller. Istället för att tvinga varje bidragsgivare att fylla i en massiv checklista använder manifestet en hierarki av kärnfrågor och frivilliga, mer detaljerade frågor. Det kan lyfta fram de mest relevanta fälten för varje persona — till exempel visa dataursprung och uppdateringsdetaljer för analytiker, samtidigt som kliniskt sammanhang och begränsningar betonas för frontlinjeforskare och kliniker. Teamet tillhandahåller ett färdigt formulär (till exempel i Microsoft Forms), en HTML-visningsmall och ett öppen källkod R-paket kallat BioDataManifest. Denna mjukvara kan automatiskt omvandla enkätssvar till tydliga manifest-sidor och till och med hämta information från större offentliga arkiv som Genomic Data Commons och dbGaP för att skapa partiella manifest för befintliga dataset.
Vad detta innebär för framtidens medicinska AI
I slutändan är Biomedical Data Manifest ett praktiskt verktyg för att göra det "finstilta" i biomedicinska dataset enklare att skapa, dela och förstå. Genom att separera dokumentation om data från dokumentation om specifika AI-modeller, och genom att skräddarsy vad som visas för olika användarrollar, minskar ramen bördan för forskare samtidigt som den ger efterföljande användare det sammanhang de behöver för att bedöma om ett dataset är lämpligt för ett givet ändamål. I vardagstermer förvandlar det ogenomskinliga medicinska dataset till tydligt märkta paket, vilket hjälper AI-utvecklare att upptäcka begränsningar och potentiella bias innan de påverkar patienter. Om det antas i stor skala kan denna typ av rollmedveten, återanvändbar dokumentation göra biomedicinsk AI mer transparent, reproducerbar och rättvis.
Citering: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Nyckelord: dokumentation av biomedicinska data, ansvarsfull AI inom medicin, datalagrsgenomskinlighet, partiskhet i maskininlärning, dataförvaltning