Clear Sky Science · sv
Estimering av utbildningspercentilrankning på samhällsnivå i Kina med multisource big data och maskininlärning
Varför ditt grannskaps utbildningsnivå spelar roll
Var vi bor påverkar vilka skolor våra barn går i, hur säkra våra gator är och till och med värdet på våra hem. Ändå har grundläggande information om hur utbildade olika grannskap är länge varit svår att få i Kina. Denna studie ändrar på det genom att använda satellitbilder, gatufoton och avancerade datoralgoritmer för att uppskatta den relativa utbildningsnivån i mer än 120 000 samhällen i hela landet, och erbjuder en ny inblick i social ojämlikhet och stadsliv.
Att se bortom antalet skolår
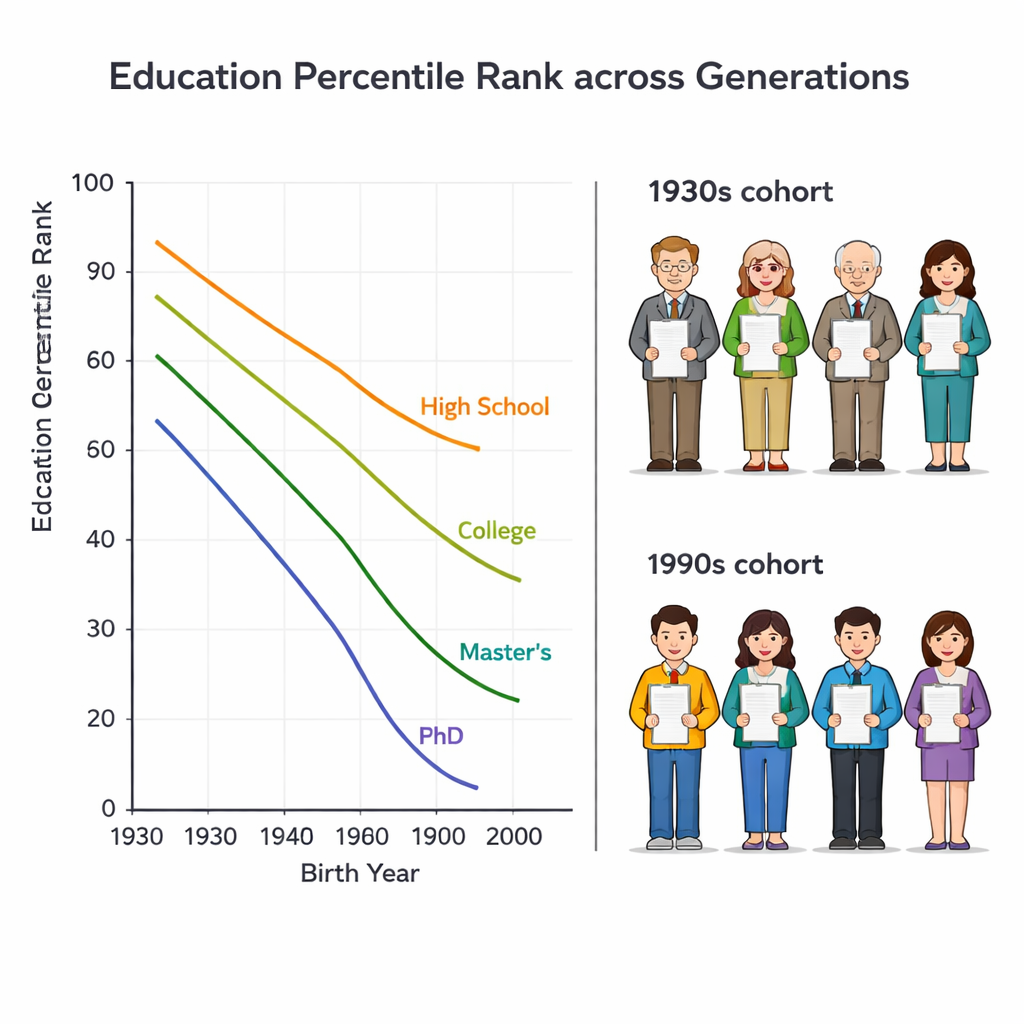
De flesta statistiska jämförelser av utbildning räknar hur många år människor gått i skolan. Men det kan vilseleda över generationer. Ett gymnasiebetyg placerade förr någon nära toppen i sin åldersgrupp; idag har många av deras barn universitetsutbildning. Författarna använder istället en "utbildningspercentilrankning" som visar var en person står inom sin egen födelsekohort, från 0 (minst utbildad) till 100 (mest utbildad). På så vis kan en äldre person med bara mellanskoleutbildning och en yngre med kandidatexamen erkännas som att de har liknande social ställning om båda till exempel ligger kring den 70:e percentilen i sin generation.
Att omvandla stadslandskap till sociala ledtrådar
För att kartlägga utbildningspercentilrankningar på samhällsnivå använde teamet sex vågor av en stor nationell undersökning plus ett brett spektrum av "big data" som beskriver den byggda miljön. De tittade på vilken typ av platser som omger varje grannskap—butiker, skolor, sjukhus, parker och kontor—hur tätt byggnader och vägar ligger, hur ljust området syns på natten från satelliter, och hur många människor som vanligtvis finns där. Från miljoner gatubilder använde de datorseende för att mäta grönområden, trottoarer, trafik, tecken på förfall som skräp eller klotter, och till och med hur välbärgat eller säkert en gata ser ut för mänskliga observatörer. De tog också hänsyn till terräng, som höjd och lutning, eftersom branta eller avlägsna områden ofta halkar efter i utveckling.
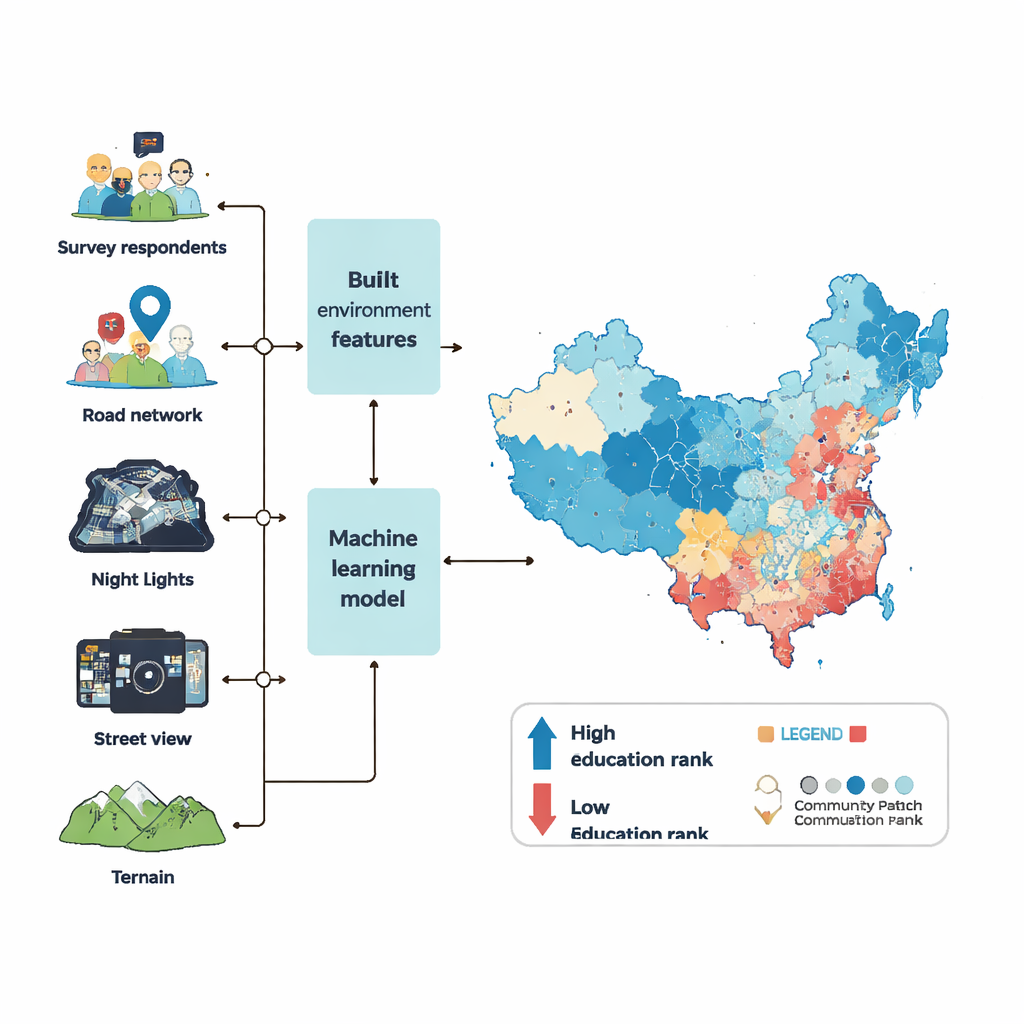
Att lära maskiner att läsa staden
Med dessa ingredienser tränade forskarna en kraftfull maskininlärningsmodell (kallad XGBoost) att lära sambandet mellan ett samhälles fysiska karaktär och dess invånares genomsnittliga utbildningspercentilrankning. De fyllde först i luckor i miljödata med en noggrann statistisk "imputations"-process så att saknade värden inte skulle snedvrida resultaten. Sedan finjusterade de modellens interna inställningar genom hundratals optimeringskörningar och bedömde prestandan efter hur väl modellen kunde förutsäga utbildningsrankningar för undersökningssamhällen den inte sett tidigare. Den slutliga modellen kunde förklara mer än 90 procent av skillnaderna mellan samhällen i testdata, med endast små fel—en starkare prestation än liknande insatser i andra länder.
Vad den nya nationella kartan avslöjar
Med den tränade modellen förutspådde författarna genomsnittliga utbildningspercentilrankningar för 122 126 samhällen i fastlands-Kina år 2020, vilket täcker större delen av det urbana området och omkring 85 procent av befolkningen. Stadskärnor framträder generellt som mest utbildade, följt av sekundära nav och sedan avlägsna förorter, även om varje metropol har sitt eget mönster. Pekings historiska kärna, till exempel, hyser inte de allra högsta rankningarna, medan Shenzhens högutbildade zoner är utspridda över flera centra. För att kontrollera tillförlitligheten jämförde teamet sina uppskattningar med officiell folkräkningsdata och med proprietära platsbaserade tjänstregister där sådana fanns. På prefekturnivå och länsnivå visar områden med högre förutsagda percentilrankningar också fler skolår i folkräkningen. På grannskapsnivå i Peking och Guangzhou stämmer deras karta väl överens med både företags- och folkräkningsmått.
Varför detta spelar roll i vardagen
För beslutsfattare, planerare och forskare erbjuder denna nya öppna dataset en detaljerad, aktuell bild av utbildningsmässiga fördelar och nackdelar i kinesiska städer. Den kan användas för att studera var medelklassöar bildas, hur långt gentrifiering har spridit sig, eller vilka distrikt som kan behöva bättre skolor, sociala tjänster eller kollektivtrafik. För allmänheten är kärnbudskapet enkelt: genom att "läsa" gator, ljus och byggnader i ett grannskap kan moderna dataverktyg approximera dess invånares sociala position med förvånansvärd noggrannhet. Detta arbete ersätter inte traditionella folkräkningar, men det ger ett snabbt, kostnadseffektivt sätt att fylla luckorna mellan dem och bättre förstå hur de platser vi bygger återspeglar och förstärker våra sociala klyftor.
Citering: Zhang, Y., Pan, Z., You, Y. et al. Community-level education percentile rank estimation in China using multi-source big data and machine learning. Sci Data 13, 304 (2026). https://doi.org/10.1038/s41597-026-06664-y
Nyckelord: utbildningsojämlikhet, urbana Kina, big data, maskininlärning, grannskap