Clear Sky Science · sv
En annoterad datamängd av Gram-färgningar från positiva blodkulturer
Varför snabba svar vid infektioner spelar roll
När bakterier eller svamp tar sig in i blodomloppet kan varje timme utan rätt behandling avgöra skillnaden mellan liv och död. Läkare förlitar sig på ett snabbt laboratorietest kallat Gram-färgning för att se vilken typ av mikroorganism som finns och för att välja tidiga antibiotika. Men att läsa dessa färgade mikroskopiska preparat är ett skickligt, manuellt arbete som tar tid och kan variera mellan teknologer. Denna studie beskriver en ny, noggrant annoterad bildsamling av verkliga sjukhusblodkulturpreparat, skapad för att hjälpa datorer att lära sig läsa Gram-färgningar automatiskt och stötta snabbare, mer pålitlig vård.
Att omvandla verkliga sjukhuspreparat till data
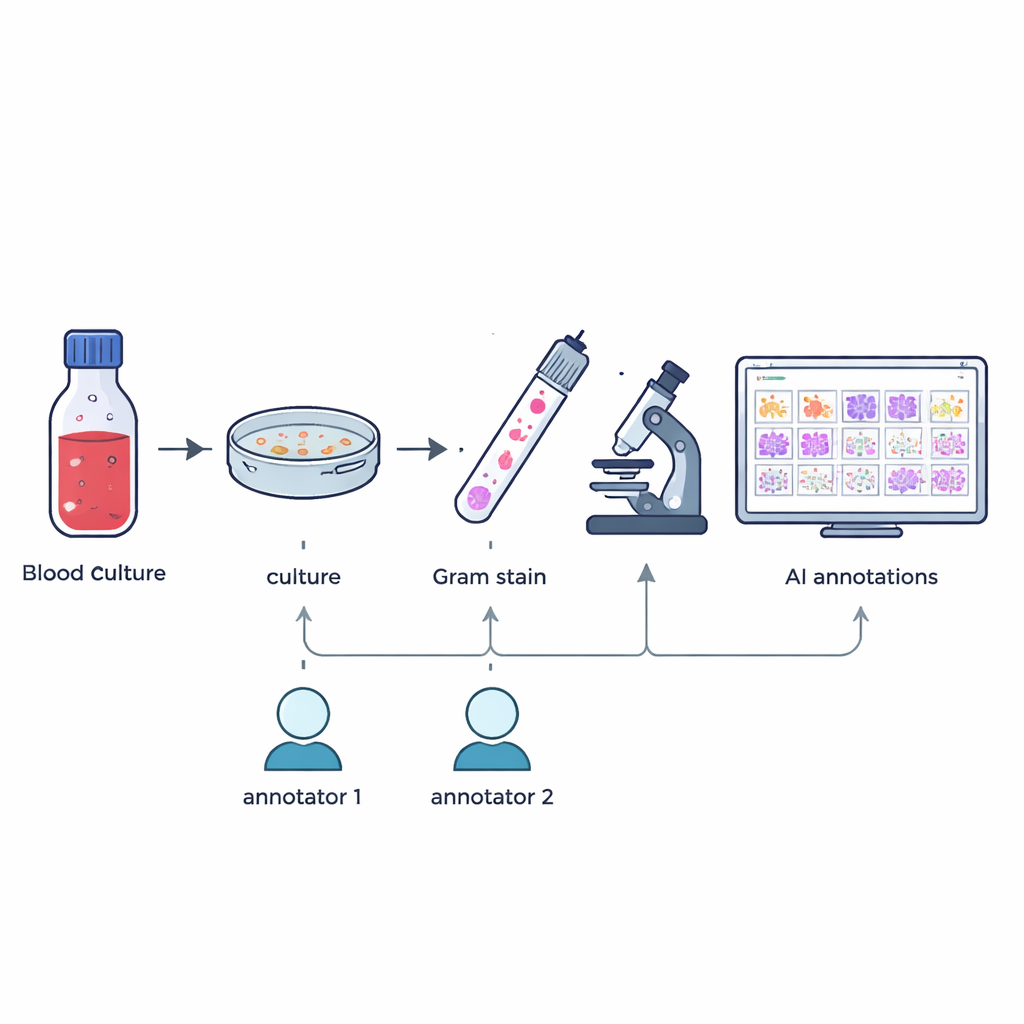
Forskarna samlade 57 olika slag av bakterier och svamp som odlats från patienters positiva blodkulturflaskor som en del av sjukhusets dagliga arbete. Från januari till maj 2024, när en blodkultur visade positivt, gjorde personalen Gram-färgade utstryk på objektglas och fastställde den exakta arten med en högprecisionsmetod kallad MALDI-TOF-masspektrometri. Utan att ändra normala rutiner eller ta extra prover fångade teamet därefter högupplösta digitala bilder av typiska synfält under ett 100× oljeimmersionsmikroskop, vilket resulterade i 505 stora färgbilder som speglar vad teknologer ser i praktiken.
Noga märkning av små former
Att bygga ett användbart träningsset för artificiell intelligens innebär att man vet exakt var varje mikroorganism finns i varje bild. Två erfarna mikrobiologiteknologer ritade oberoende rutor runt individuella mikroorganismer eller kluster i varje bild, guidade endast av vad de såg i mikroskopet. Ett specialbyggt mjukvaruverktyg jämförde de två uppsättningarna markeringar: rutor som överlappade tillräckligt slogs ihop, och eventuella avvikelser eller oenigheter flaggades. En senior expert med mer än 20 års erfarenhet granskade sedan dessa fall manuellt. Denna flerstegsprocess gav 7 528 kontrollerade annotationer som markerar kocker (runda celler), baciller (stavformade celler) och svamp, medan partiella eller tveksamma objekt utelämnades.
Vad datamängden innehåller
Den färdiga resursen kombinerar flera informationslager. Alla 505 bilder tillhandahålls som högupplösta JPEG-filer, och de slutliga, expertverifierade rutorna lagras i standardformatet COCO JSON som är allmänt använt inom datorvisionsforskning. Extra filer länkar varje bild till dess mikrobiella art, om den är Gram-positiv eller Gram-negativ, dess breda formgrupp, typen av blodkulturflaska den kommer från och hur lång tid odlingen tog för att bli positiv. Eftersom varje bild innehåller bara en art delar alla rutor inom en given bild samma biologiska egenskaper. Användare kan välja mellan en enda stor annoteringsfil eller separata filer per bild, och ett enkelt Pythonskript ingår för att visualisera vilken bild som helst med dess rutor överlagrade.
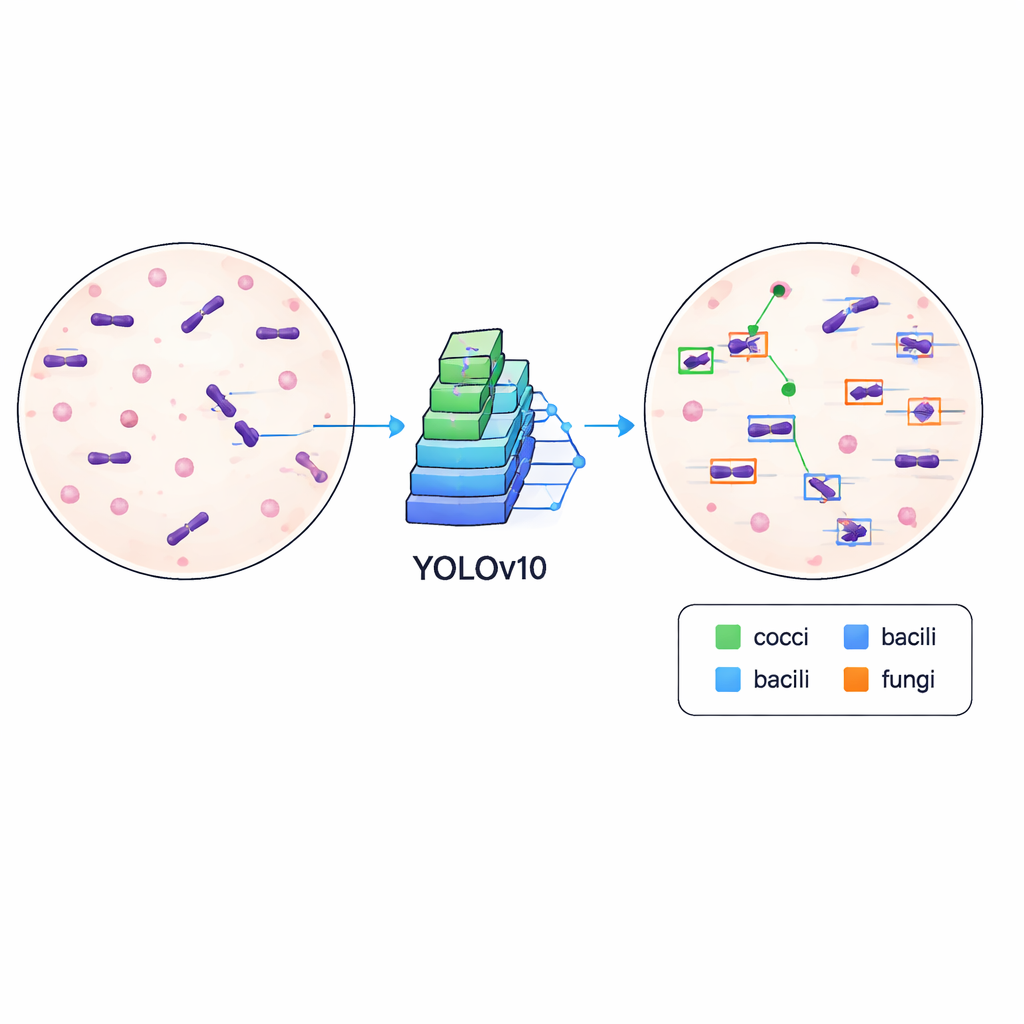
Att lära datorer att känna igen mikrober
För att visa att datamängden inte bara är välordnad utan också praktisk tränade författarna en modern objektigenkänningsalgoritm känd som YOLOv10 för att hitta och klassificera mikrober i bilderna. De delade upp data i tränings- och valideringsuppsättningar och körde modellen i 500 träningsomgångar på ett högpresterande grafikkort och följde hur väl den lärde sig att rita exakta rutor och skilja mellan olika celltyper. Det tränade systemet uppnådde en medelgenomsnittlig precision på cirka 84,6 % vid en standard tröskel för matchning, vilket indikerar att det pålitligt kan lokalisera och etiketterar mikrober över varierande preparatutseenden, inklusive skillnader i färgintensitet, bakgrundsopor och fokus.
Hur denna resurs kan användas
Eftersom data följer vanliga format kan de kopplas in i många befintliga datorvisionspipelines. Forskare kan först träna ett system enbart för att skilja verkliga mikrober från skräp, vilket hjälper laboratorier att filtrera bort falskt positiva kultursignaler. De kan också gruppera mikrober i breda formkategorier, vilket motsvarar vad kliniker behöver för en tidig så kallad "Tier 1"-rapport som vägleder initialt antibiotikaval. Ett mer ambitiöst mål är att skilja individuella arter vid hjälp av subtila visuella ledtrådar. Författarna noterar begränsningar: vissa celler är grupperade, vissa preparat kommer från en enda källa per art och fokus kan variera — precis som i verkliga livet. Ändå har varje inkluderad ruta noggrant kontrollerats, vilket gör datamängden till en trovärdig utgångspunkt.
Vad detta betyder för patienter
Enkelt uttryckt förvandlar detta arbete rutinmässiga blodkulturpreparat till en gemensam träningsarena för smart programvara. Genom att göra både bilderna och expertmarkeringarna offentligt tillgängliga sänker studien tröskeln för team över hela världen att bygga och testa AI-verktyg som kan läsa Gram-färgningar snabbt och konsekvent. Medan sådana system inte kommer att ersätta mänskliga mikrobiologer kan de hjälpa till att upptäcka farliga infektioner tidigare, minska tolkningsfel och stödja bättre användning av antibiotika. För patienter kan det innebära snabbare, mer precis behandling när det spelar som mest roll.
Citering: Yi, Q., Gou, X., Zhu, R. et al. An annotated dataset of Gram stains from positive blood cultures. Sci Data 13, 294 (2026). https://doi.org/10.1038/s41597-026-06651-3
Nyckelord: blodströmsinfektioner, Gram-färgning, medicinsk bilddatamängd, artificiell intelligens, mikrobiologisk diagnostik