Clear Sky Science · sv
Relationsutvinning och begreppsnormalisering baserad på transformermodeller med ett annoterat corpus av kliniska prövningar
Hjälpa läkare hitta rätt patienter snabbare
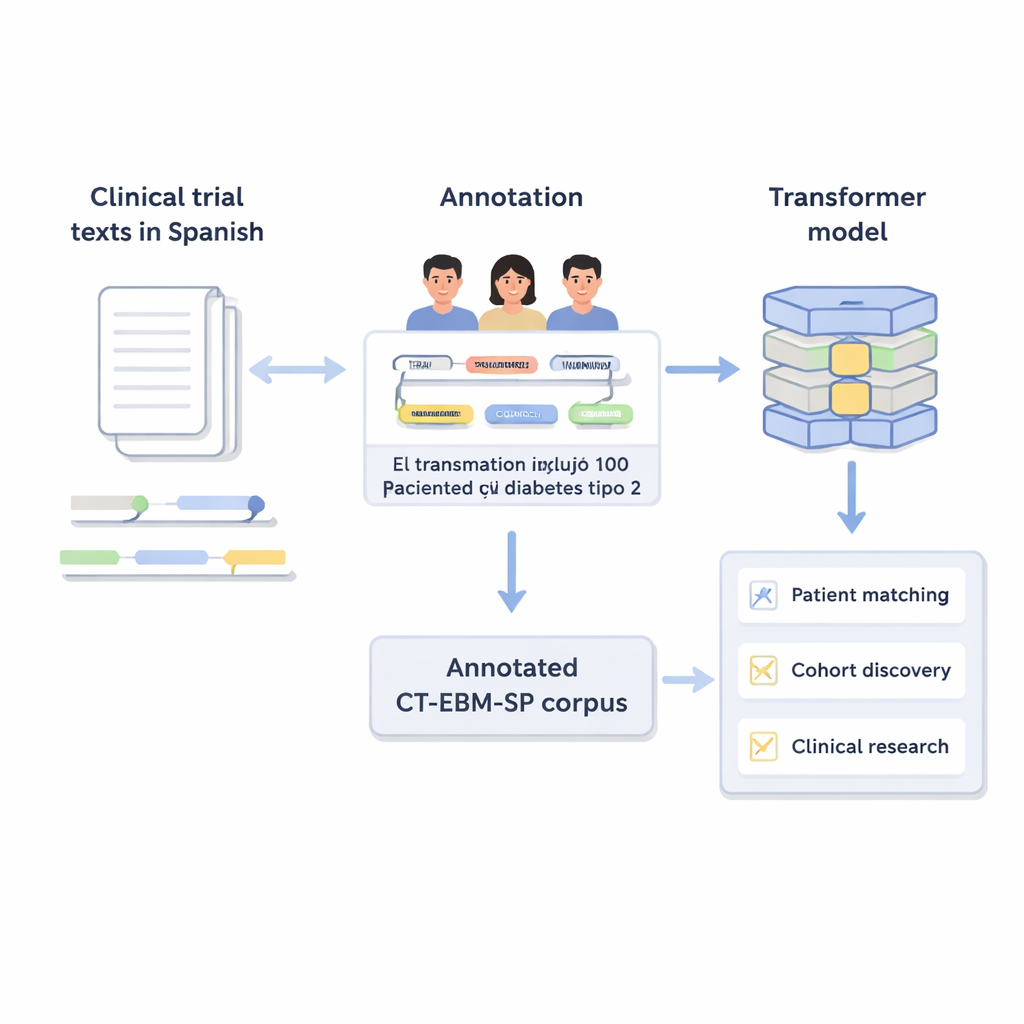
Varje klinisk prövning är beroende av att hitta patienter som uppfyller en lång lista med medicinska tillstånd, behandlingar och tidsramar. I dag måste läkare ofta läsa igenom elektroniska journaler och prövningsbeskrivningar för hand, vilket är långsamt och känsligt för fel. Den här artikeln presenterar en stor, noggrant kontrollerad samling spanska texter från kliniska prövningar och visar hur modern artificiell intelligens kan förvandla det ostrukturerade språket till organiserad data, vilket banar väg för snabbare, mer rättvis och mer precis medicinsk forskning.
Förvandla fritext till organiserad information
Kliniska prövningar beskriver vem som kan och inte kan delta med vardagligt medicinskt språk: åldersgränser, tidigare sjukdomar, laboratorievärden och prövade behandlingar. Datorer har svårt med den här sortens fritext. Författarna skapade version 3 av CT‑EBM‑SP‑korpuset, en datamängd med 1 200 spanska texter från kliniska prövningar innehållande nästan 300 000 ord. Mänskliga experter gick igenom dessa texter och markerade 23 typer av medicinska entiteter, såsom sjukdomar, läkemedel, testresultat och tidsuttryck, samt markörer för negation (till exempel ”ingen anamnes av”) och osäkerhet. De märkte också 11 attribut som fångar detaljer som om en händelse är i det förflutna eller i framtiden och om den drabbat patienten eller en familjemedlem.
Få medicinska termer att tala samma språk
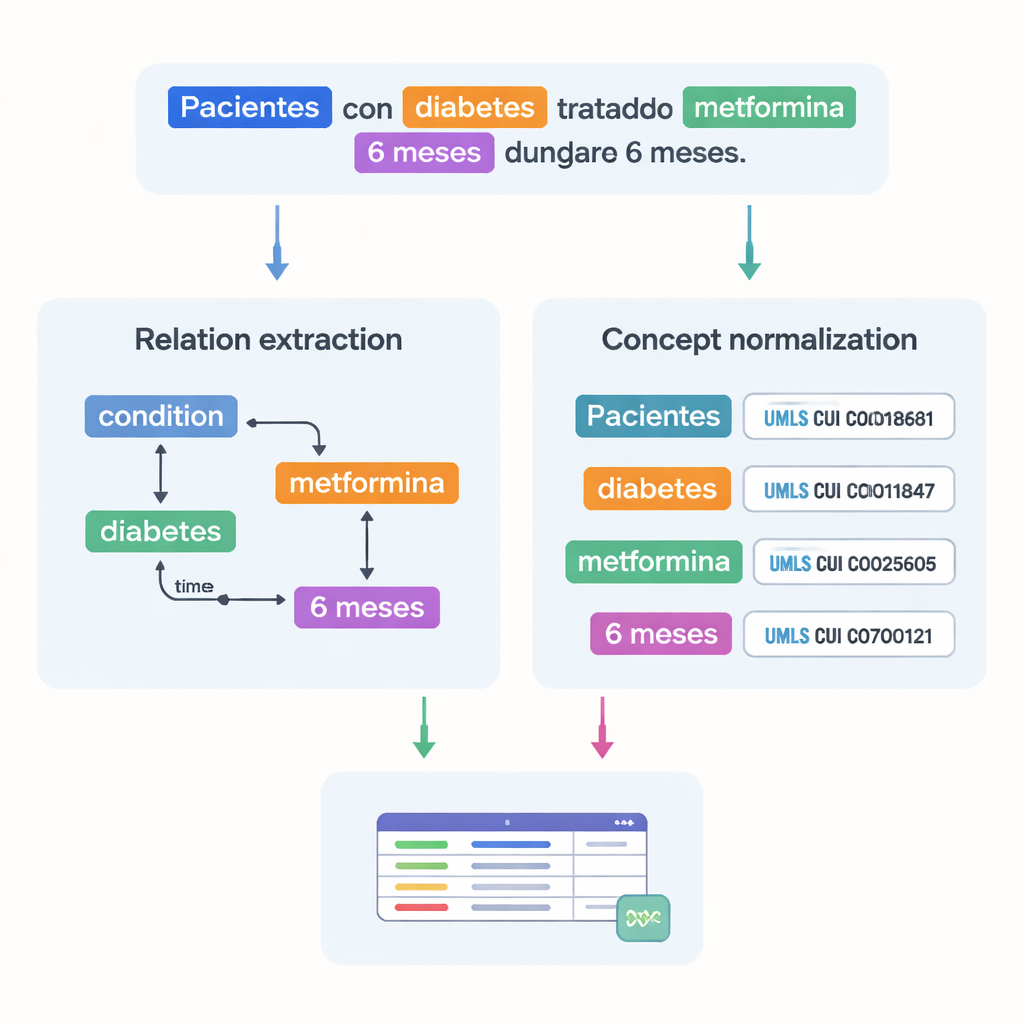
En stor utmaning inom medicinen är att samma begrepp kan skrivas på många sätt. För att lösa detta kopplade teamet de flesta markerade entiteterna till standardiserade koder från Unified Medical Language System (UMLS), en omfattande flerspråkig medicinsk ordbok. Det här steget, kallat begreppsnormalisering, innebär att olika stavningar eller fraser pekar på samma unika identifierare. Till exempel mappas flera varianter av ”25‑hydroxyvitamin D” till ett enda UMLS‑begrepp. Totalt innehåller korpuset över 87 000 entiteter och mer än 68 000 relationer, och omkring 82 % av entiteterna normaliserades med framgång. Två experter kontrollerade dessa länkar oberoende av varandra och uppnådde mycket hög överensstämmelse, vilket tyder på att annoteringarna är tillförlitliga.
Fånga hur medicinska fakta förhåller sig till varandra
Utöver att lista medicinska termer registrerar datasetet hur de hänger ihop. Författarna designade 18 typer av relationer för att fånga mönster som är viktiga i prövningar, som vilken dos som hör till vilket läkemedel, hur länge en behandling pågår eller vilket tillstånd en patient upplever. Temporala relationer visar om en händelse inträffar före eller efter en annan, och andra länkar markerar var en sjukdom förekommer i kroppen eller om en fras uttrycker negation eller spekulation. Tillsammans gör dessa relationer det möjligt för datorer att bygga grafer över en patients situation—vem patienten är, vilket tillstånd de har, vilken behandling de får och under vilken tidsram—i stället för bara att känna igen isolerade ord.
Träna och testa moderna AI‑modeller
För att visa att korpuset är praktiskt användbart finjusterade författarna flera transformermodeller, inklusive flerspråkiga versioner av BERT och RoBERTa. De tränade modellerna på två uppgifter: relationsutvinning, som lär sig återställa länkarna mellan entiteter, och medicinsk begreppsnormalisering, som mappar text till UMLS‑koder. För relationsutvinning nådde den bästa modellen ett F1‑värde nära 0,88, vilket betyder att den korrekt identifierade de flesta relationer med relativt få fel. För begreppsnormalisering gissade en flerspråkig modell kallad SapBERT, använd utan ytterligare träning, rätt begrepp på första försöket nästan 90 % av gångerna. Dessa resultat visar att väl annoterade, medelstora dataset kan driva precisa, effektiva modeller även utan mycket stora allmänna språkmodeller.
Varför denna resurs är viktig för framtida vård
CT‑EBM‑SP‑korpuset och tillhörande modeller ger en grund för verktyg som automatiskt kan tolka spanska texter från kliniska prövningar, matcha dem mot patientjournaler och stödja kohortupptäckt på sjukhus. Eftersom data är anpassade till internationella medicinska standarder och har noggrant granskats av experter kan de också hjälpa till att utveckla liknande resurser för andra språk med färre digitala verktyg. I vardagliga termer handlar detta arbete om att göra det enklare och säkrare att rätt patienter erbjuds rätt prövningar, snabba upp medicinska upptäckter samtidigt som bördan för vårdpersonalen minskar.
Citering: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Nyckelord: kliniska prövningar, medicinsk textmining, spansk vård, transformermodeller, evidensbaserad medicin