Clear Sky Science · sv
Filmnivådata om scener från Amazon X-Ray på den amerikanska marknaden kombinerat med IMDb
Varför filmscener spelar roll för att förstå kultur
Filmer formar vår bild av världen, men större delen av filmforskningen har koncentrerat sig på biljettintäkter, breda genrer eller stjärnstatus — inte på vad som faktiskt utspelar sig bildruta för bildruta. Den här artikeln presenterar en ny datamängd som låter forskare zooma in på nivåer av enskilda scener, karaktärer och repliker för mer än tretusen filmer som strömmas i USA på Amazon Prime Video. Genom att kombinera Amazons X-Ray-funktion med Internet Movie Database (IMDb) erbjuder författarna en detaljerad, standardiserad karta över vem som syns var och när i varje film, vilket öppnar dörren för rikare studier av representation, berättande och även AI-system som lär sig från video.
Från grova manus till färdiga scener
Hittills har de flesta storskaliga studier av film förlitat sig på manus eller undertextfiler. Dessa källor är användbara men ofullkomliga. Manus är ofta tidiga utkast som skiljer sig från slutklippet och kan utelämna mindre karaktärer eller sena redigeringsändringar. Undertexter fångar talade repliker men missar tysta gestalter, statister i bakgrunden och rent visuellt berättande — till exempel kamerans kvarhållna fokus på en karaktärs ansikte. På grund av dessa luckor har tidigare försök att spåra vem som interagerar med vem på skärmen, eller hur olika grupper representeras, tvingats gissa utifrån text ensam, vilket kan leda till felaktiga identifieringar av karaktärer och deras relationer.
Att göra X-Ray till forskningsfärdiga data
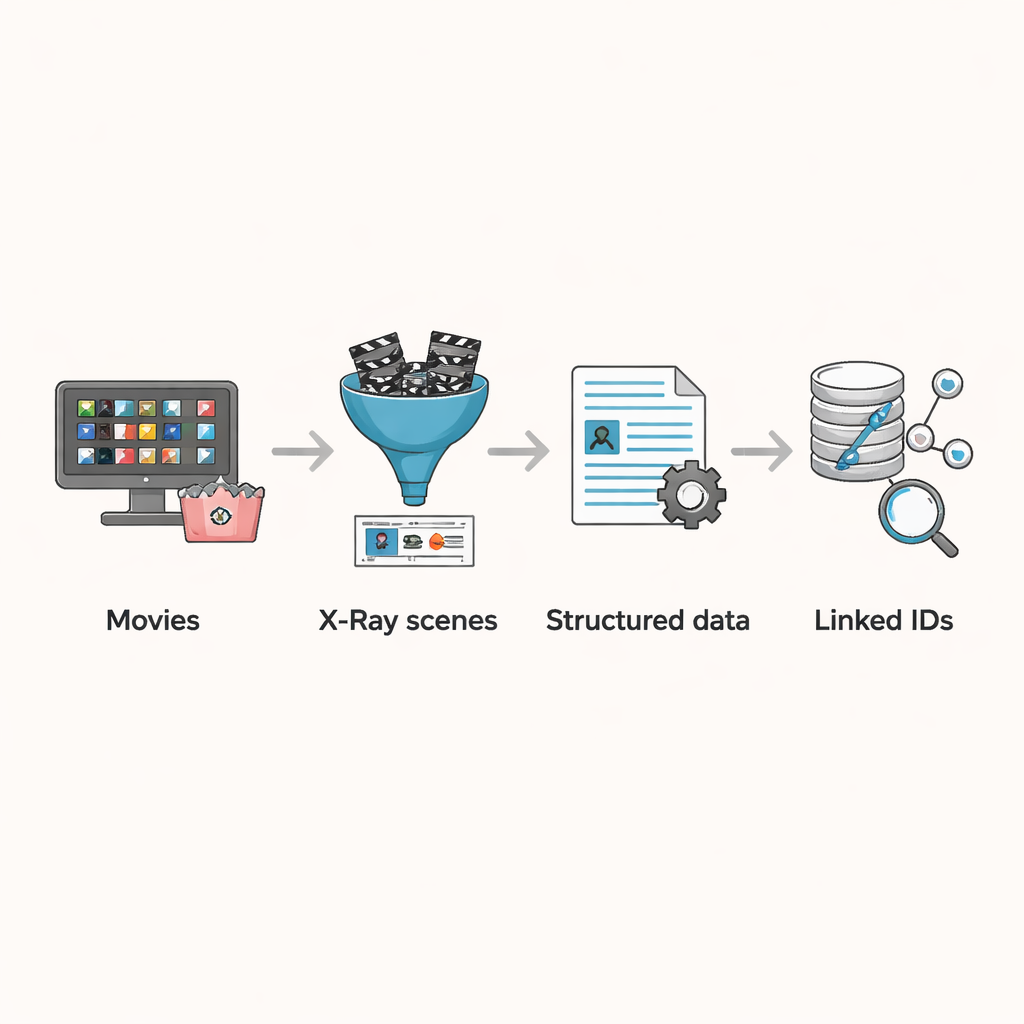
Amazons X-Ray-funktion erbjuder en väg runt dessa problem. När tittare pausar en film visar X-Ray vilka skådespelare och karaktärer som för tillfället finns på skärmen — information som är kuraterad och knuten direkt till den slutredigerade filmen. Författarna byggde en pipeline för att hämta dessa scennivådata för 3 265 filmer som fanns i den amerikanska Prime Video-katalogen i augusti 2023. De samlade först alla filmer som ingick i Prime, filtrerade bort de utan X-Ray-information och tog bort dubbletter orsakade av upprepade titlar eller alternativa versioner. För varje återstående film fångade de upp de dataströmmar som spelaren använder för att ladda X-Ray och undertextinformation och sparade resultaten i strukturerade filer som listar sceners avgränsningar, vilka karaktärer som är närvarande i varje scen och, för de flesta titlar, exakt tidpunkt för varje undertextsegment.
Knyta scener till den bredare filmvärlden
Datamängdens verkliga styrka kommer av att koppla dessa scenuppdelningar till extern information. Medan X-Ray redan länkar varje karaktär till en IMDb-profil inkluderar det inte ett IMDb-ID för själva filmen. Författarna utvecklade en matchningsalgoritm som utgår från en films titel, hämtar flera kandidatmatchningar från IMDb och sedan jämför IMDb:s främsta rollista med de skådespelare som listas i X-Ray-data. Om minst en större skådespelare överlappar behandlas filmen som en träff. Denna automatiserade process matchade korrekt majoriteten av filmerna, och teamet granskade sedan manuellt de återstående några hundra kantfallen, rättade felklassificeringar och tog bort poster som inte faktiskt var narrativa filmer, såsom standup-specialer. Slutresultatet är en noggrant rensad uppsättning filmer där varje scen, karaktär och undertext kan länkas till rik metadata såsom årtal, land och rollbesättningsdemografi.
Vad forskare kan göra med dessa filmer
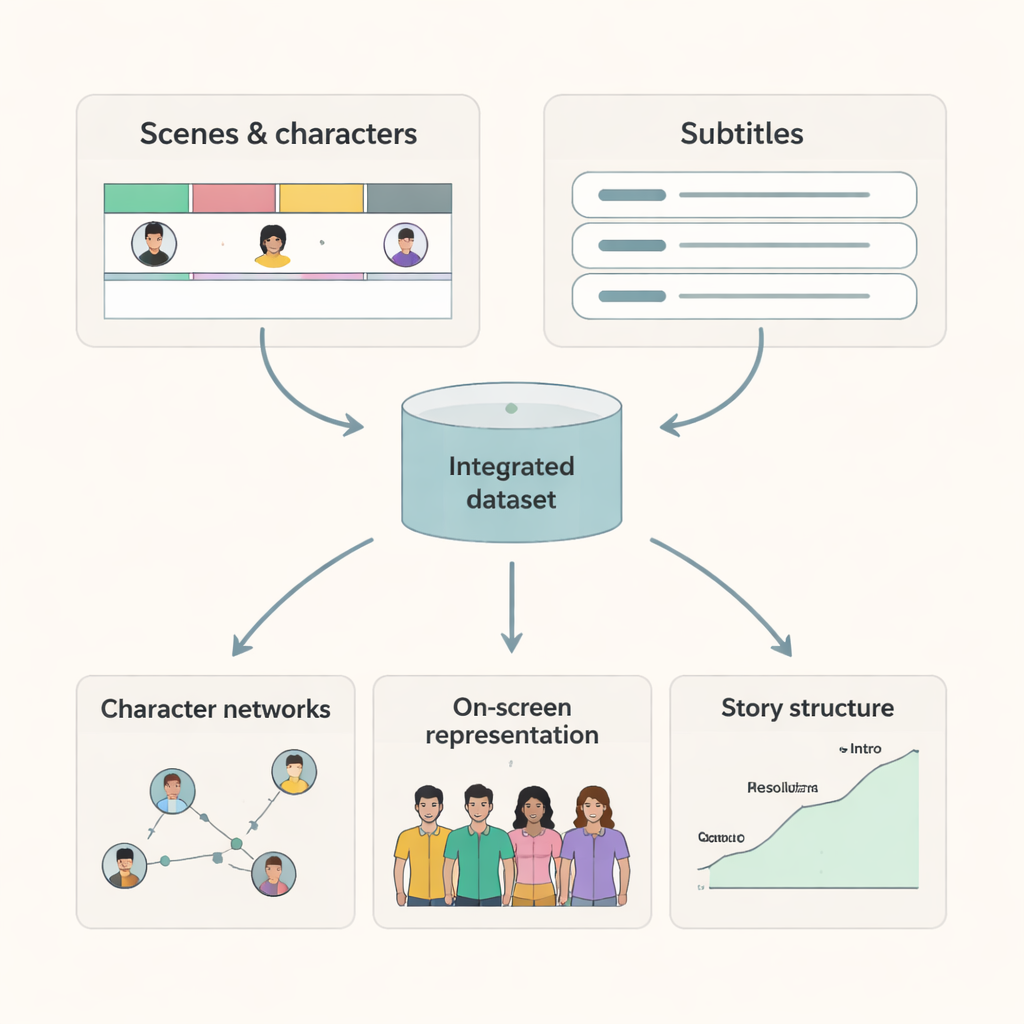
Där varje scen har tydliga start- och sluttider och en lista över vilka som förekommer kan forskare nu bygga precisa kartor över karaktärsinteraktioner och skärmtid. Undertexter som är linjerade med scener gör det möjligt att studera hur språket skiljer sig mellan karaktärer och kontexter, eller hur vissa teman utvecklas genom dialogen. Genom att kombinera denna datamängd med ytterligare information från IMDb och andra källor kan forskare undersöka frågor som: Hur har jämvikten mellan könen på skärmen förändrats över decennier? Får karaktärer från olika bakgrunder lika mycket narrativt utrymme? Hur skiljer sig interaktionsmönster mellan genrer eller länder? Datamängden erbjuder också en högkvalitativ referens för AI-modeller som syftar till att förstå videoinnehåll, eftersom den ger grundfakta om vem som syns och när.
En ny lins på vardagsfilmer
Enkelt uttryckt gör detta arbete tusentals filmer sökbara som en scen-för-scen-katalog över vem som dyker upp, vem som pratar och hur berättelserna är strukturerade. Samlingen är visserligen begränsad till titlar som finns på amerikanska Prime Video och bygger på Amazons interna X-Ray-processer, men täcker ändå filmer över många decennier och genrer, inte bara berömda prisvinnare. Denna bredd gör det möjligt för forskare att studera vardagsfilmer, inte bara de klassiker som överlever i minnet. Allt eftersom datamängden uppdateras och utökas lovar den att fördjupa vår förståelse av hur filmer speglar samhället — och att ge både samhällsvetare och teknologer en mer trogen bild av vad som faktiskt händer på skärmen.
Citering: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Nyckelord: filmdatamängder, scennivåanalys, Amazon X-Ray, IMDb-metadata, på-skärmen-representation