Clear Sky Science · sv
Rekonstruktion av extrema havsnivåer längs Kinas kust med flera djupinlärningsmodeller
Varför kustvattennivåer spelar roll i vardagen
Kinas långa kustlinje hyser hundratals miljoner människor, stora hamnar och växande städer. När kraftiga stormar pressar havet in över land kan de höga vattennivåerna översvämma bostadsområden, skada infrastruktur och förorenar dricksvatten med salt. Ändå är detaljerade register över sådana extrema kustvattennivåer förvånansvärt sällsynta och splittrade. Denna studie fyller det tomrummet genom att rekonstruera femtio år av dagliga högvattennivåer längs stora delar av Kinas kust, med moderna verktyg för artificiell intelligens som omvandlar fläckvisa observationer och väderreanalysdata till en konsekvent, offentligt tillgänglig dataset.
Följa havets upp- och nedgång
Kustvattennivåer drivs av två huvudingredienser: det regelbundna samspel mellan Månen och Solen som skapar tidvatten, och stormfloder, som är tillfälliga vattenbulor som pressas iland av låg lufttryck och starka vindar under cykloner och andra vädersystem. I Kina kommer tropiska cykloner och andra stormar ofta på redan höga tidvatten, vilket skapar särskilt farliga förhållanden. Men många tidvattenstationer som mäter havsnivå har endast korta eller intermittenta tidsserier, och vissa är inte öppet tillgängliga. Det gör det svårt för forskare och planerare att förstå hur extrema havsnivåer varierar från plats till plats och från decennium till decennium längs denna hårt utsatta kust.
Använda smarta modeller för att fylla i luckorna
Författarna angrep problemet genom att kombinera moderna djupinlärningstekniker med traditionell tidvattenanalys. De fokuserade på 23 tidvattenstationer utspridda längs Kinas kust och samlade detaljerad väderinformation från ERA5 global reanalys, inklusive lufttryck och vind nära ytan över en 10x10-graders ruta runt varje station. Dessa vädermönster användes för att lära flera typer av neurala nätverk hur dagliga maximala stormfloder förhåller sig till atmosfären runtomkring. Samtidigt använde teamet ett verktyg kallat UTide för att extrahera de förutsägbara tidvattenkomponenterna ur historiska havnivåserier, vilket gjorde det möjligt att skilja den regelbundna tidvattenrörelsen från den mer oförutsägbara flodkomponenten.
Testa olika varianter av djupinlärning
I stället för att förlita sig på en enda algoritm jämförde studien systematiskt fyra djupinlärningsmodeller: ett Long Short-Term Memory (LSTM)-nätverk, ett hybrid CNN-LSTM som först läser rumsliga mönster, ett ConvLSTM som hanterar rum och tid tillsammans, och en Informer-modell baserad på Transformer-arkitekturen som blivit populär inom språkbehandling. För att hålla modellerna effektiva komprimerade forskarna de stora väderfälten med huvudkomponentanalys innan träning. De gav också varje modell en 24-timmars historia av atmosfäriska förhållanden och använde uppmärksamhetsmekanismer så nätverket kunde fokusera på de viktigaste ögonblicken. För varje station reserverade de cirka 20 % av tidsserien som en oberoende testperiod och valde den modell som presterade bäst där för den slutliga rekonstruktionen.
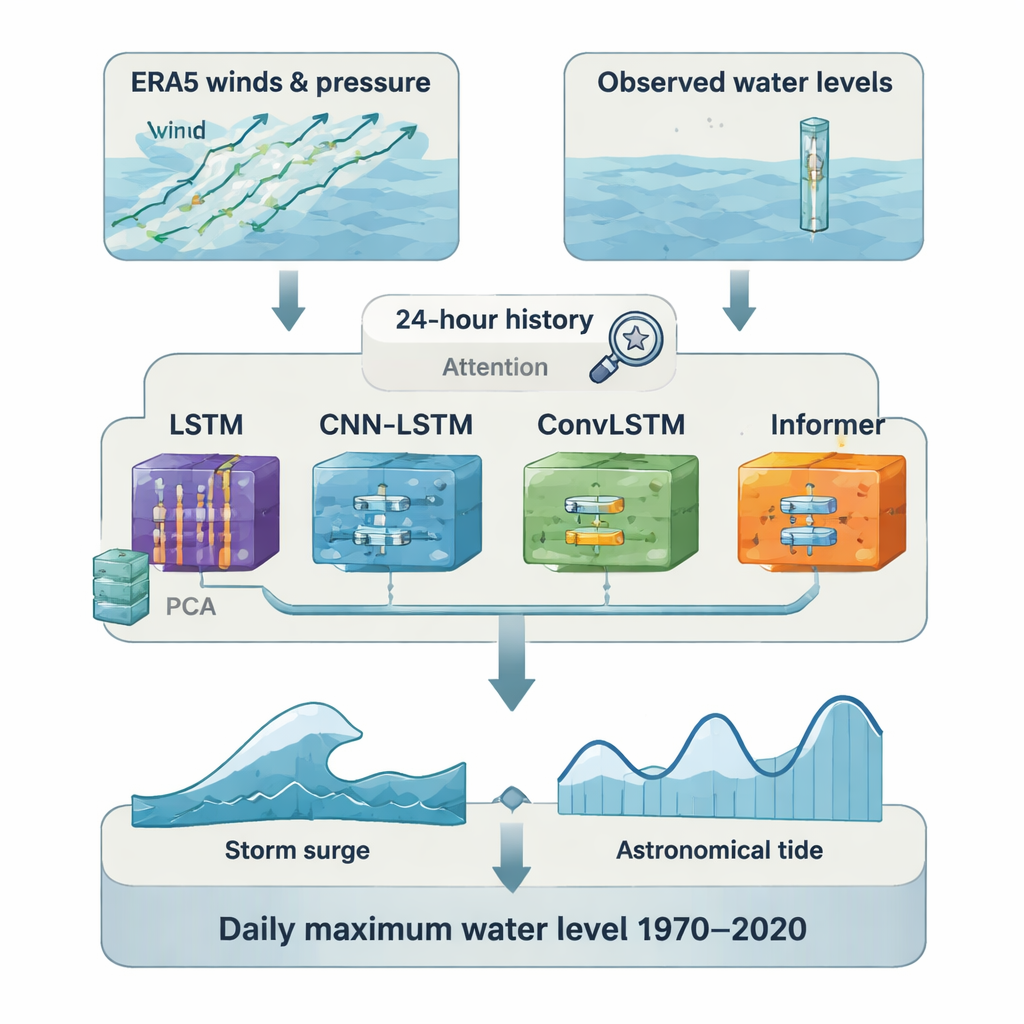
Återuppbygga femtio år av högvatten
När de var tränade användes den bäst presterande modellen vid varje plats för att rekonstruera dagliga maximala stormfloder för hela perioden 1970–2020. Dessa flodestimat lades sedan till motsvarande astronomiska tidvatten från UTide för att producera dagliga maximala totala vattennivåer. Eftersom det högsta tidvattnet och den högsta stormfloden på en given dag vanligtvis inträffar vid något olika tidpunkter utgör denna enkla addition en övre gräns för vad som faktiskt hände; tester med timvisa data tyder på att denna överskattning i genomsnitt är cirka 15 centimeter, eller ungefär 15 %. Även med denna konservativa skevhet matchar de rekonstruerade serierna väl observerade data där sådana finns: i genomsnitt är korrelationen mellan rekonstruerade och observerade dagliga maxima cirka 0,9, och felen ligger i storleksordningen några tiotals centimeter, även för mycket höga vattennivåer över 95:e percentilen.
Vad detta betyder för kuster och samhällen
För forskare, ingenjörer och kustplanerare ger den nya datasetet en detaljerad, konsekvent bild av hur extrema havsnivåer har uppträtt längs Kinas kust under det senaste halvseklet. Den överträffar flera allmänt använda globala produkter, särskilt under tyfoner och andra extrema händelser, och levereras med full metadata, kod och prestandamått så att andra kan återanvända och granska den. För allmänheten innebär detta att bedömningar av översvämningsrisk, konstruktion av skyddsvallar, evakueringsplanering och långsiktig anpassning nu kan bygga på långt rikare information än tidigare. I enkla termer, genom att lära datorer att ”spela upp” årtionden av stormdrivna högvatten erbjuder studien en starkare vetenskaplig grund för att skydda kustsamhällen från dagens faror och förbereda dem för morgondagens stigande hav.
Citering: Fang, J., Huang, J., Bian, W. et al. Reconstruction of Extreme Sea Levels in coastal China using Multiple Deep Learning models. Sci Data 13, 268 (2026). https://doi.org/10.1038/s41597-026-06593-w
Nyckelord: stormflod, extrem havsnivå, kustöversvämning, djupinlärning, Kinas kustlinje