Clear Sky Science · sv
CNeuroMod-THINGS, en tätt uppmätt fMRI-datamängd för visuell neurovetenskap
Varför bildtittande kan avslöja hur våra sinnen fungerar
Varje dag tar våra ögon in tusentals bilder — från kaffekoppar och smarttelefoner till hundar, träd och fullsatta gator. I bakgrunden känner våra hjärnor snabbt igen det vi ser och kommer ofta ihåg det senare. CNeuroMod-THINGS-projektet syftade till att fånga denna dolda aktivitet i ovanlig detalj och skapade en av de mest djupt uppmätta hjärndatamängderna som någonsin samlats in när människor tittar på verklighetsnära bilder. Denna resurs är avsedd att driva nästa generations forskning om hjärnan och artificiell intelligens.
Att bygga ett rikt bibliotek av hjärnreaktioner
I stället för att skanna hundratals frivilliga en eller två gånger skannade teamet upprepade gånger endast fyra mycket engagerade deltagare. Varje person kom tillbaka vid 33 till 36 tillfällen, vilket tillsammans blev ungefär 200 timmars hjärnavbildning i det större CNeuroMod-projektet och dussintals timmar dedikerade enbart till bilder. Under dessa sessioner såg försökspersonerna upp till 4 320 distinkta fotografier hämtade från THINGS-bildsamlingen, som täcker 720 vardagliga objektkategorier såsom verktyg, djur, fordon och möbler. Detta omsorgsfulla urval av bilder säkerställer att många hörn av vår visuella värld representeras, inte bara några få populära objekt.

En minnesspelsupplevelse inne i MR-kameran
För att hålla deltagarna engagerade och för att undersöka minnet gjorde forskarna bildvisningen till ett kontinuerligt igenkänningsspel. Vid varje försök visades en enda bild i mitten av skärmen medan personen låg i en MR-kamera. Med en specialbyggd spelkontroll rapporterade deltagarna om de trodde att bilden var ny eller hade setts tidigare, och hur säkra de var på sitt omdöme. De flesta bilder visades tre gånger: en gång vid första mötet, en gång igen några minuter senare under samma besök och en gång till vid ett senare besök, ofta med cirka en veckas mellanrum. Denna design gjorde det möjligt för teamet att jämföra korttids- och långtidsminne för exakt samma bilder samtidigt som de följde motsvarande förändringar i hjärnaktivitet.
Att fånga detaljerade signaler från syn och minne
Datamängden sträcker sig långt bortom enkla "på/av"-mått på hjärnaktivitet. Författarna använde avancerade analysmetoder för att uppskatta ett separat svar för varje enskilt försök och varje bild i varje litet tredimensionellt pixel (voxel) i hjärnskanningen. De följde också var deltagarna tittade med ögonspårningskameror, övervakade andning och puls samt mätte huvudrörelser. Kvalitetskontroller visar att signalerna är anmärkningsvärt stabila: deltagarna svarade i nästan varje försök, höll blicken nära mitten av skärmen och rörde sig mycket lite. I centrala visuella områden — regioner kända för att reagera starkt på ansikten, kroppar eller scener — gav samma bild mycket konsekventa aktivitetsmönster varje gång den visades. Dessa mönster var så tydliga att när svaren plottades i en förenklad tvådimensionell karta, tenderade bilder med liknande betydelser (till exempel djur eller fordon) att klustra tillsammans.
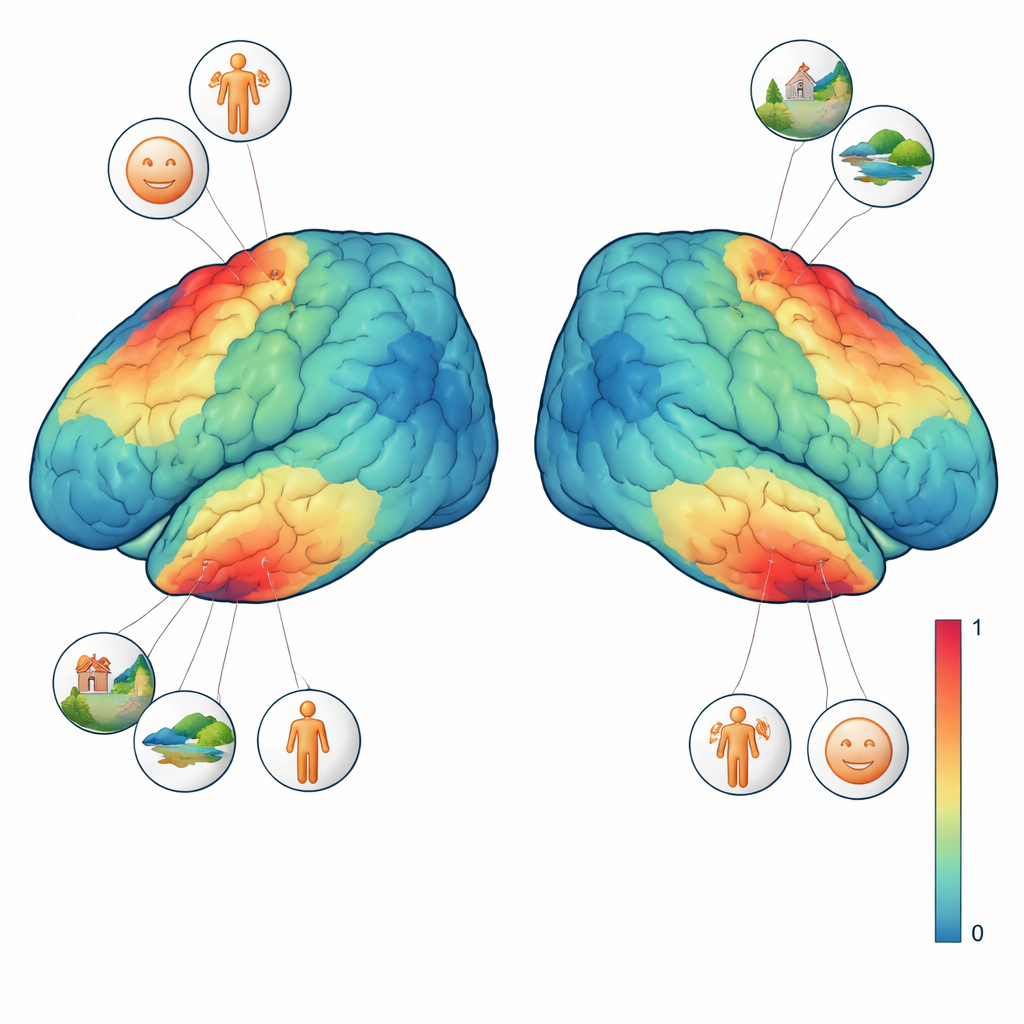
Kartläggning av vad olika hjärnregioner bryr sig om
För att bättre tolka dessa signaler genomförde tre av de fyra deltagarna ytterligare synstester. I ett test rörde svepande former sig över en texturerad bakgrund för att visa vilken del av synfältet varje hjärnregion "ser". I ett annat visades korta block med ansikten, platser, kroppsdelar, karaktärer och generiska objekt för att exakt lokalisera regioner som föredrar en viss typ av bild framför andra. Genom att kombinera dessa lokaliseringsuppgifter med huvudexperimentet kunde teamet ställa precisa frågor som: svarar en enskild voxel mer när ett ansikte är närvarande, eller när hela scenen syns? De fann att ansiktsselektiva regioner svarade starkast när helst någon form av ansikte dök upp, medan en scenselektiv region föredrog bilder med rika bakgrunder som rum, gator eller landskap, även när inga människor syntes. Dessa finkorniga preferenser framträdde på nivån för enskilda bilder och till och med för enskilda voxlar.
En grund för smartare modeller av syn
I grunden är CNeuroMod-THINGS en noga kuraterad offentlig resurs snarare än ett engångsresultat. Alla hjärndata, ögonspårning, beteenderespons, bildannoteringar och analyskod delas fritt under en öppen licens. Eftersom samma fyra personer skannades i många andra uppgifter — att titta på filmer, spela videospel, lyssna på berättelser — kan forskare nu bygga detaljerade, person-specifika modeller som länkar kontrollerade experiment med mer naturliga upplevelser. För icke-specialister är slutsatsen att vi nu har en högupplöst "uppslagstabell" som visar hur en verklig mänsklig hjärna svarar på tusentals vardagsbilder. Detta kommer att hjälpa forskare att testa idéer om visuell perception och minne och vägleda utformningen av artificiella synsystem som ser världen lite mer som vi gör.
Citering: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
Nyckelord: fMRI, visuell perception, objektigenkänning, hjärndata, minne