Clear Sky Science · sv
Semantisk anpassning av den tyska Human Genome-Phenome Archive-metadatamodellen inom Europas genomikfält
Varför delning av genomdata kräver mer än bara filer
Modern medicin förlitar sig i allt högre grad på att läsa vår DNA för att ställa diagnoser och anpassa behandlingar. Men den verkliga styrkan i genomik uppstår när data från många sjukhus och länder kan kombineras. Det fungerar bara om varje dataset beskrivs på ett tydligt och kompatibelt sätt och om integritetslagar som Europas GDPR efterlevs strikt. Den här artikeln förklarar hur German Human Genome-Phenome Archive (GHGA) bygger ett detaljerat "beskrivningssystem" för genomiska studier så att värdefulla data kan hittas, förstås och delas säkert över hela Europa.
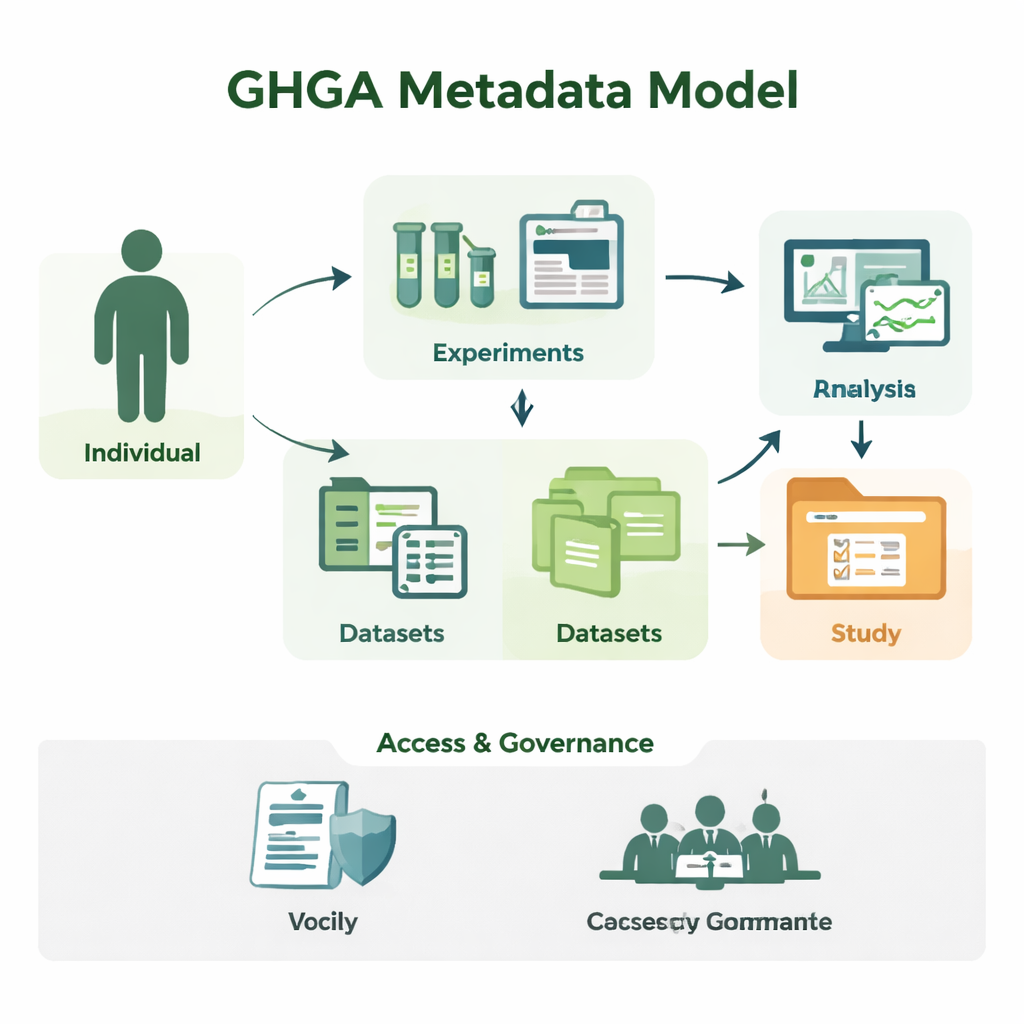
Från råa sekvenser till begripliga studier
Genomisk forskning genererar enorma mängder sekvensdata, men i sig är en fil med DNA-bokstäver meningslös. Forskare behöver veta vem provet kom från, vilken vävnad som användes, hur experimentet utfördes och under vilka villkor datan får återanvändas. GHGA fångar denna omgivande information som metadata. Dess modell organiserar metadata i 16 byggstenar, såsom den person som deltar i studien ("Individ"), det prov som togs, experimentet och analysen som utfördes, de datafiler som skapades samt de dataset och studier som binder ihop dem. Genom att separera vetenskapliga detaljer från administrativa sådana, som åtkomstvillkor, speglar modellen hur ett verkligt laboratorium och dataportal fungerar, men på ett sätt som datorer kan bearbeta tillförlitligt.
Behålla användbarhet utan att göra personer identifierbara
Eftersom GHGA hanterar känsliga mänskliga hälsodata var teamet tvunget att utforma modellen så att den är vetenskapligt rik utan att göra det enkelt att identifiera någon person bakom datan. Europeiska GDPR-regler säger att information som rimligen skulle kunna kopplas tillbaka till en individ räknas som personuppgift, även om namn tagits bort. Artikeln beskriver en noggrann integritetsanalys som visade hur kombinationer av detaljer som ålder, postnummer och sällsynta diagnoser kan avslöja identiteter. Som svar undviker GHGA:s publika portal detaljerad platsinformation, grupperar åldrar i breda intervall istället för exakta årtal och slår ihop detaljerade diagnoskoder till grövre kategorier. På så sätt kan forskare fortfarande avgöra om ett dataset kan vara relevant för deras arbete, medan insatsen att peka ut en enskild person blir orealistisk.
Kontrollera kompatibilitet med Europas genomik-ekosystem
För att vara verkligen användbar måste GHGA:s metadata passa in i ett bredare europeiskt nätverk av genomarkiv och verktyg. Författarna jämförde därför sin modell, post för post, med fyra andra vida använda ramverk: två versioner av European Genome-phenome Archive (EGA), ISA-tab-standarden och FAIR Genomes-modellen från nederländsk vård. De genomförde en detaljerad "crosswalk" som frågade, för varje GHGA-fält, om det fanns en motsvarighet i de andra modellerna och vice versa. De fann att de flesta av GHGA:s nyckelegenskaper har tydliga motsvarigheter annorstädes, särskilt för att beskriva studier, prover, experiment, analyser och filformat. Det innebär att GHGA-dataset kan förstås och integreras tillsammans med data som lagras i andra europeiska system.
Hitta gemensam grund – och vad som fortfarande saknas
Utifrån denna jämförelse extraherade teamet 25 "konsensus"-metadatafält som förekommer i minst tre av de fem modellerna. Dessa täcker grundläggande uppgifter såsom deltagarnas kön och hälsostatus, använd vävnad, typ av sekvensering och instrument, analysmetod, filformat samt grundläggande studiebeskrivningar och kontaktuppgifter. Dessa delade fält stämmer överens med befintliga minimirapporteringsriktlinjer och kan fungera som en kärnchecklista för den som utformar nya portaler för genomiska data. Samtidigt avslöjade analysen information som vissa modeller samlar in men som GHGA för närvarande utelämnar eller endast accepterar i flexibel fritextform, såsom exakta datum för provtagning och sekvensering, uteslutna diagnoser och detaljerade kontaktpersonnamn. Många av dessa utelämnanden är medvetna avvägningar till förmån för integritet och anonymitet.
Vad detta betyder för framtida hälsovetenskaplig forskning
Sammanfattningsvis visar studien att GHGA:s metadatamodell är detaljerad, flexibel och väl anpassad till internationell praxis, samtidigt som den håller sig inom strikta europeiska integritetsregler. Den täcker redan alla fält som andra arkiv betraktar som obligatoriska och kan utvidgas för nya tekniker som single-cell och spatial omics. Genom att erbjuda ett tydligt sätt att beskriva vem och vad en genomisk studie involverar, hur datan producerades och under vilka villkor den kan återanvändas, hjälper GHGA till att förvandla isolerade datasiloer till en sammankopplad forskningsresurs. För patienter ökar detta chansen att deras data, när de väl donerats, säkert kan bidra till upptäckter och bättre behandlingar över gränserna under många år framöver.
Citering: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Nyckelord: dela genomiska data, metadatastandarder, integritet och GDPR, GHGA, personlig medicin