Clear Sky Science · sv
SEA CDM: Study-Experiment-Assay Common Data Model och databaser för tvärdomänsdataintegration och analys
Varför organisering av laboratoriedata är viktig för oss alla
Modern medicin drivs av enorma mängder experimentella data — från vaccinprövningar och infektionsstudier till cancergenomik. Dessa data är dock ofta inlåsta i inkompatibla format, vilket försvårar för forskare att kombinera resultat och upptäcka viktiga mönster, till exempel vem som svarar bäst på ett vaccin eller varför vissa får fler biverkningar. Den här artikeln beskriver ett nytt sätt att organisera och koppla samman olika biomedicinska experiment så att forskare kan ställa rikare frågor och få snabbare, mer tillförlitliga svar som i slutändan påverkar hur vi förebygger och behandlar sjukdom.
Ett gemensamt språk för experiment
Olika forskargrupper och databaser tenderar att beskriva sina studier på sitt eget sätt, även när de ägnar sig åt mycket lika arbeten. En databas kan fokusera på vaccinprövningar, en annan på genaktivitet i enskilda celler och en tredje på kliniska utfall — alla med olika etiketter och strukturer. Study–Experiment–Assay Common Data Model, eller SEA CDM, erbjuder en enkel gemensam ” grammatik ” för dessa insatser. Den delar upp varje biomedicinskt projekt i tre länkade steg: den övergripande studien som ställer en fråga, de experiment som utförs på människor eller djur, och assayerna — såsom blodprover eller mätningar av genuttryck — som genererar resultat. Runt dessa steg standardiserar modellen också nyckelelement som vem eller vad som studerades, vilka prover som togs, vilka behandlingar som applicerades och vilka analyser som gjordes. 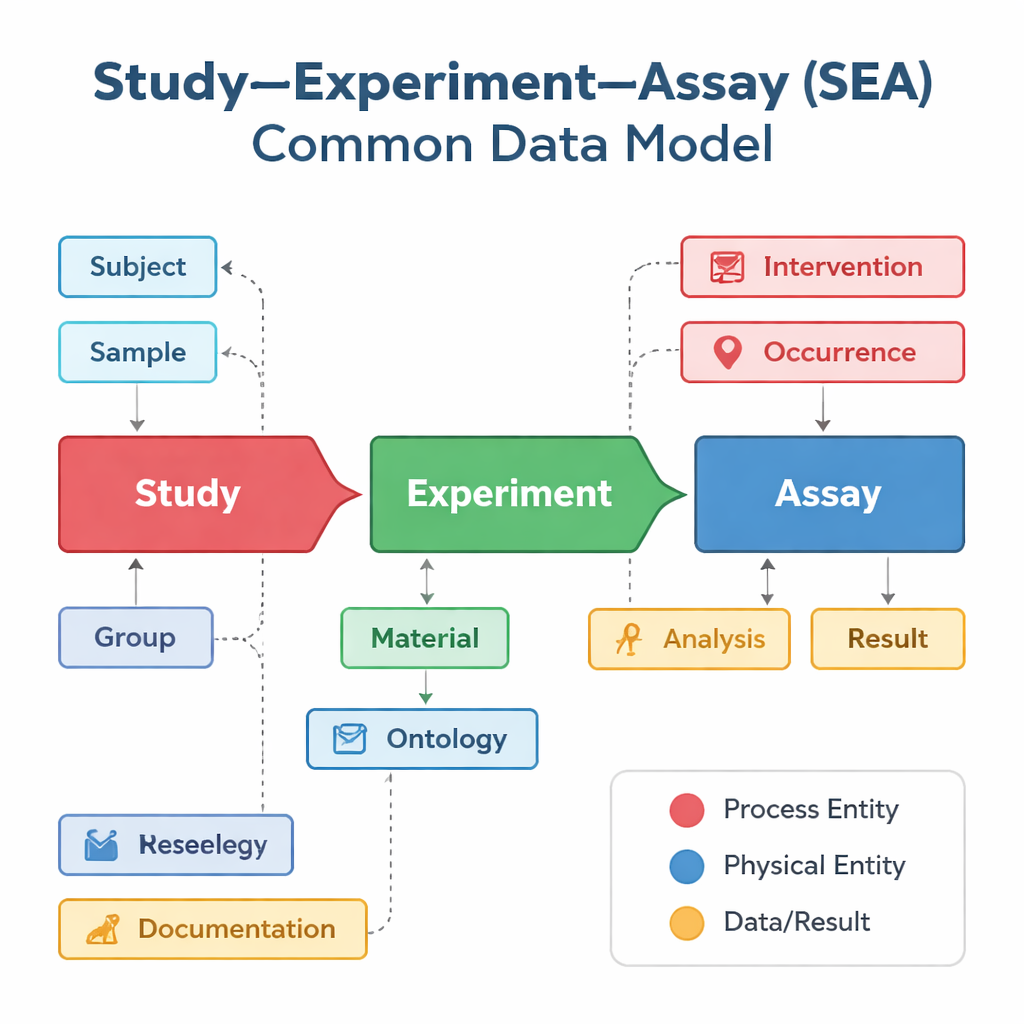
Ontologier: att förvandla etiketter till kunskap
Att bara rada upp kolumnrubriker räcker inte; samma begrepp kan heta olika på olika ställen. SEA CDM förlitar sig på kurerade vokabulärer, så kallade ontologier, för att säkerställa att ”influensavaccin”, ”trivalent inaktiverat influensavaccin” och ett märkesnamn som ”Fluzone” alla erkänns som besläktade begrepp. Dessa ontologier är strukturerade som släktträd av medicinska och biologiska termer. Eftersom SEA CDM fäster en officiell identifierare från en ontologi vid varje variabel — såsom en sjukdom, celltyp eller ett vaccin — kan datorer automatiskt följa dessa träd, hitta alla relevanta poster och till och med härleda relationer. Till exempel kan en kort fråga plocka ut varje studie som använde något trivalent influensavaccin ur hundratals namngivna produkter, vilket möjliggör kraftfulla semantiska sökningar som går långt bortom enkel nyckelordsmatchning. 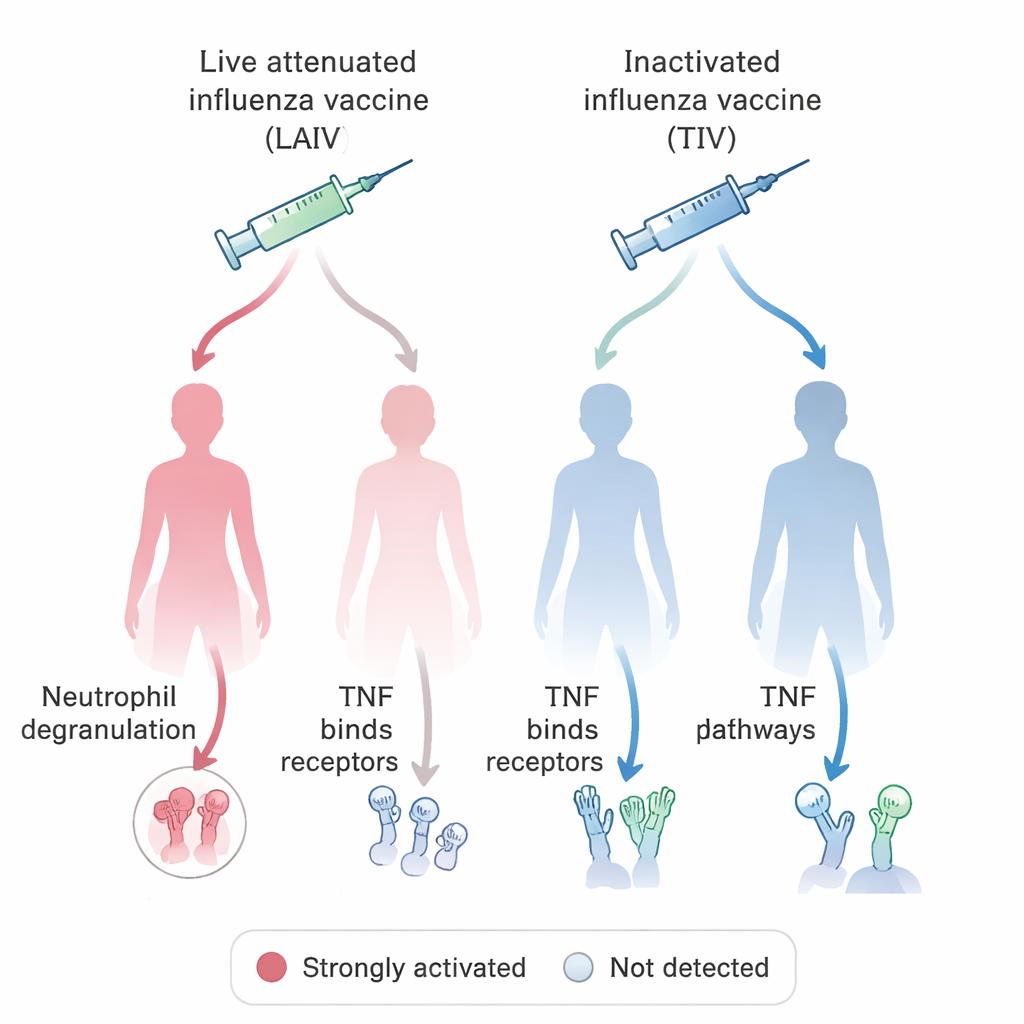
Från utspridda filer till ihopkopplade databaser
För att testa sin modell i verkligheten byggde författarna en familj av databaser och verktyg under paraplynamnet OSEAN. De konverterade tre stora offentliga resurser till SEA CDM-strukturen: ImmPort, som värd för metadata från immunresponsstudier; VIGET, som länkar vaccinstudier till genaktivitetsdata; och CELLxGENE, som fokuserar på enskilda cellmätningar. Med hjälp av specialbyggda pipelines översatte de dussintals ursprungliga tabeller och filformat till en konsekvent uppsättning SEA CDM-tabeller eller grafnoder. Detta gjorde det möjligt att lagra mer än tusen immunrelaterade studier, över två miljoner prover och många beskrivningar av vacciner, sjukdomar och laboratoriemetoder i en sammanhängande struktur som kan sökas med samma programvara.
Vad enhetlig data kan avslöja om vacciner och könsskillnader
Med detta enhetliga system på plats ställde teamet en biologisk fråga med direkt medicinsk relevans: hur stimulerar olika influensavacciner immunsystemet hos kvinnor och män? Genom att fråga den VIGET-baserade OSEAN-databasen och tillämpa enkla regler för vad som räknas som en ”stimulerad” gen identifierade de hundratals gener vars aktivitet ökade efter vaccination med antingen levande försvagade influensavacciner (som innehåller försvagat virus) eller inaktiverade, ”dödade” vaccin. De jämförde sedan de vägar dessa gener deltar i och separerade data efter kön. Ett slående mönster involverade neutrofiler, en typ av vita blodkroppar som angriper mikrober genom att släppa ut giftiga granula, och signalering via TNF, ett centralt inflammatoriskt molekyl. I de flesta grupper kopplades influensavaccination till tecken på neutrofildegranulering, men denna signatur saknades hos kvinnor som fått det levande försvagade vaccinet. Däremot var TNF-relaterad signalering särskilt framträdande hos dessa kvinnor men inte i parallella manliga grupper. Dessa fynd återgår till djurstudier som antyder att neutrofilbeteende och vaccinsvar systematiskt kan skilja sig mellan män och kvinnor.
Att bygga ett ekosystem för framtida upptäckter
Författarna menar att den verkliga styrkan i SEA CDM ligger i att göra biomedicinska data mer FAIR — sökbara, tillgängliga, interoperabla och återanvändbara. Genom att ge experiment en gemensam struktur och förankra varje viktig etikett till en väl definierad ontologi-term gör deras system det mycket enklare att kombinera data från olika källor, spåra hur prover hanterats och reproducera analyser. Influensafallet visar att även relativt enkla frågor, körda över en harmoniserad databas, kan avslöja subtila, könsspecifika mönster i vaccinsvar som kan påverka dosering eller val av vaccin. När fler resurser antar denna gemensamma modell och de medföljande verktygen kommer forskare vara bättre rustade att koppla ledtrådar över sjukdomar, teknologier och populationer och förvandla fragmenterade dataset till ett verkligt integrativt biodataekosystem.
Citering: Huffman, A., Yeh, FY., Hur, J. et al. SEA CDM: Study-Experiment-Assay Common Data Model and Databases for Cross-Domain Data Integration and Analysis. Sci Data 13, 238 (2026). https://doi.org/10.1038/s41597-026-06558-z
Nyckelord: dataintegration, biomedicinsk ontologi, vaccinsvar, könsskillnader, kunskapsgraf