Clear Sky Science · sv
Akademiska program i datavetenskap i för-ChatGPT-eran i Midvästra USA: en kurerad dataset
Varför detta är viktigt för studenter och samhällen
I hela USA verkar nya datainriktade examina dyka upp varje termin, men det kan vara svårt att avgöra vad ”Data Science”, ”Data Analytics” eller ett ”Interdisciplinary”-program faktiskt innebär. Denna artikel beskriver en omsorgsfullt uppbyggd dataset som kartlägger och organiserar varje datarelaterat akademiskt program i Mellanvästern i USA strax innan verktyg som ChatGPT blev allmänt spridda, och erbjuder en tydlig ögonblicksbild av hur högskolor utbildade nästa generation data‑specialister.
En ögonblicksbild tagen före AI‑vågen
Författarna ville fånga tillståndet för datavetenskapsutbildning år 2023, precis innan generativ artificiell intelligens började omforma undervisning och tekniskt arbete. De fokuserade på högre utbildningsinstitutioner i 12 delstater i Mellanvästern, från community colleges till stora universitet. När ett programs namn innehöll ordet ”data” granskades det noggrant: Var undervisningen gavs? Var det en huvudämneskurs, biämne eller ett certifikat? Riktade det sig till grundnivå eller forskarnivå? Vilka institutioner ansvarade och vilka ämnen täckte kursplanen? Genom att frysa detta ögonblick i tiden ger datasetet framtida forskare möjlighet att se hur utbildningserbjudanden förändras i takt med att AI‑verktyg sprids.
Att reda ut olika typer av dataprogram
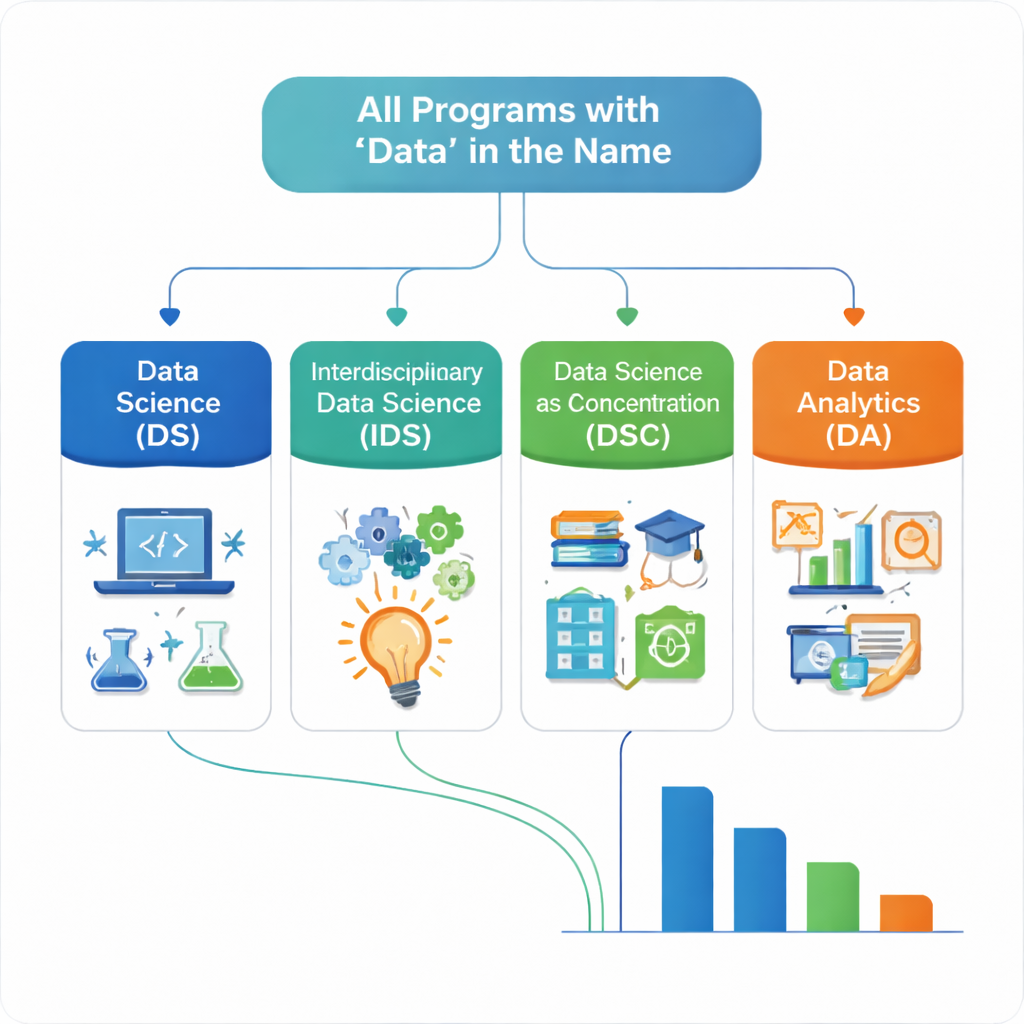
En av författarnas största utmaningar var att begreppet ”data science” används på många olika sätt. Två examina med nästan identiska namn kan utbilda studenter för mycket olika yrkesroller. För att skapa ordning i detta kaos utvecklade de ett reproducerbart klassificeringssystem med fyra huvudgrupper. Ett klassiskt Data Science‑program kombinerar omfattande matematik, statistik och datavetenskap och leds vanligtvis av dessa avdelningar. Interdisciplinary Data Science‑program delar den tekniska kärnan men styrs delvis av icke‑tekniska avdelningar eller kräver att studenter lägger till ett andra huvudämne eller biämne. Data Science as a Concentration beskriver fall där ”data” är ett spår inom en annan examen. Data Analytics‑program inkluderar erbjudanden som använder ordet ”data” men saknar den fulla kombinationen av matematik och datorteknik, eller styrs av avdelningar utanför de kvantitativa kärnområdena.
Hur informationen samlades in och kontrollerades
För att bygga datasetet använde teamet först College Boards sökverktyg för att sammanställa en lista över institutioner i Mellanvästern. De besökte sedan varje skolas webbplats manuellt, sökte efter program med ”data” i titeln och registrerade detaljer i ett strukturerat kalkylblad. För varje program dokumenterade de delstat, skola, stad, programnamn, om det erbjöds på campus eller online, dess nivå och typ, samt om det var ett huvudämne, biämne eller certifikat. De behandlade huvudämnen och biämnen som potentiellt separata erbjudanden och ägnade särskild uppmärksamhet åt vilka avdelningar som formellt ansvarade. När avdelningsansvaret var oklart använde de kurslistor och ämnestaggar för att dra slutsatsen om läroplanen verkligen kombinerade matematik och datorteknik. Efter det manuella arbetet använde de Python‑kod för att rensa data, ta bort dubbletter, upprätthålla konsekventa kategorier och flagga eventuella motsägelser eller saknad information.
Vad datasetet avslöjar om Mellanvästern
Den slutliga samlingen innehåller 404 unika program från 225 skolsystem. Mer än hälften klassificeras som Data Science, vilket tyder på att många institutioner i Mellanvästern har anammat den mer tekniska modell som betonar matematik och datorteknik. Ungefär en tredjedel faller under Data Analytics, ofta kopplat till affärs‑, informations‑ eller teknikavdelningar och tenderar att lägga mindre vikt vid både matematik och datavetenskap tillsammans. Interdisciplinary Data Science och Data Science as a Concentration utgör mindre men viktiga delar, vilket speglar ansträngningar att kombinera datakunskaper med områden som affärsverksamhet, teknik eller samhällsvetenskaper. Författarna grupperar också skolor efter typ—community colleges, tekniska och ingenjörsinriktade skolor, universitet och andra högskolor—och visar att universitet dominerar antalet erbjudanden, medan community colleges och tekniska skolor i större utsträckning lutar åt Data Analytics‑program.
Hur andra kan använda denna resurs
Datasetet, offentligt tillgängligt via Harvard Dataverse tillsammans med den kod som användes för att bearbeta och validera det, är avsett att återanvändas. Beslutsfattare kan undersöka hur datarelaterade program är fördelade över delstater och skoltyper när de planerar investeringar i arbetskraftsutveckling. Institutionchefer och kursplanerare kan jämföra sina egna program med andra i närheten eller av liknande typ. Utbildningsforskare kan spåra hur programnamn, strukturer och ledarskap förändras över tid, särskilt när AI‑verktyg blir mer integrerade i klassrum och arbetsplatser. Lärare kan till och med använda data i kursprojekt och låta studenter utforska den verkliga utbildningslandskapet de står inför.
Vad detta arbete säger oss, enkelt uttryckt
I grunden erbjuder denna artikel en välorganiserad karta över hur högskolor i Mellanvästern undervisade i datakunskaper strax före den generativa AI‑boomen. Genom att tydligt skilja mellan olika typer av ”dataprogram” och dokumentera vem som driver dem och vad de kräver, ger författarna en utgångspunkt för att förstå hur utbildning håller jämna steg med snabb teknologisk förändring. Om några år kommer denna ögonblicksbild att hjälpa till att visa om program blev mer tekniska, mer tvärvetenskapliga eller mer påverkade av AI—och vägleda skolor och samhällen när de bestämmer hur de bäst förbereder studenter för en datadriven värld.
Citering: Blackford, D., Maria Selvitella, A. Data science academic programs in the pre-ChatGPT erain the Midwestern United States: a curated dataset. Sci Data 13, 236 (2026). https://doi.org/10.1038/s41597-026-06553-4
Nyckelord: datavetenskaplig utbildning, akademiska program, universitet i Mellanvästern, examina i dataanalys, dataset för högre utbildning