Clear Sky Science · sv
En datamängd över elektroniska produkters koldioxidavtryck för fråge- och svarssystem
Varför dina prylares koldioxidkostnad spelar roll
Varje laptop, surfplatta eller stationär dator du använder bär på en dold klimatnota. Långt innan du trycker på strömbrytaren har energi och material redan förbrukats för att bryta metaller, tillverka chip och montera enheter. Företag publicerar nu rapporter som uppskattar dessa ”förkroppsligade” koldioxidutsläpp, men de är utspridda över tusentals svårtolkade PDF-filer. Den här artikeln introducerar en ny datamängd som omvandlar dessa röriga rapporter till sökbar, jämförbar information, vilket gör det lättare för forskare, beslutsfattare och så småningom konsumenter att förstå och minska elektronikens klimatpåverkan.
Att omvandla spridda rapporter till användbar data
Stora datorleverantörer som HP, Dell, Lenovo och Acer publicerar produktkoldioxidrapporter som beskriver hur mycket växthusgas som släpps ut över en enhets livstid och hur mycket som kommer från olika delar som skärm, batteri eller kretskort. Tyvärr formaterar varje företag dessa dokument olika: siffror kan finnas i löptext, tabeller eller diagram, och nyckeltal är ofta uppdelade över flera sidor. Författarna samlar 1 735 sådana rapporter för ett brett produktsortiment och konverterar sedan PDF-filerna till råtext. Med hjälp av specialskriven kod och mönstermatchningsregler plockar de ut centrala fakta som total koldioxidpåverkan, hur mycket som beror på tillverkning och procentandelarna från varje större komponent.
Att lära datorer att besvara koldioxidfrågor
Att bara rada upp siffror räcker inte; målet är att datorprogram ska kunna svara på praktiska frågor om utsläpp. För att uppnå detta bygger teamet en fråge–svarsdatamängd kallad PCF‑QA. För varje produkt skapar de naturligt formulerade frågor som ”Vilken komponent har det största tillverkningsavtrycket?” eller ”Vad är koldioxidavtrycket för skärmen i denna laptop?” och parar ihop dem med korrekta svar härledda från den rensade datan. Frågorna delas in i fyra kategorier: ord-matchning (hämta ett nummer direkt från texten), max/min (hitta den största eller minsta bidragsgivaren), top-k (lista de tre eller fem främsta komponenterna) och beräkning (räkna exempelvis ut en delkomponents avtryck från procentandelar och totaler). Denna struktur låter moderna språkmodeller öva både läsförståelse och grundläggande numeriskt resonerande.
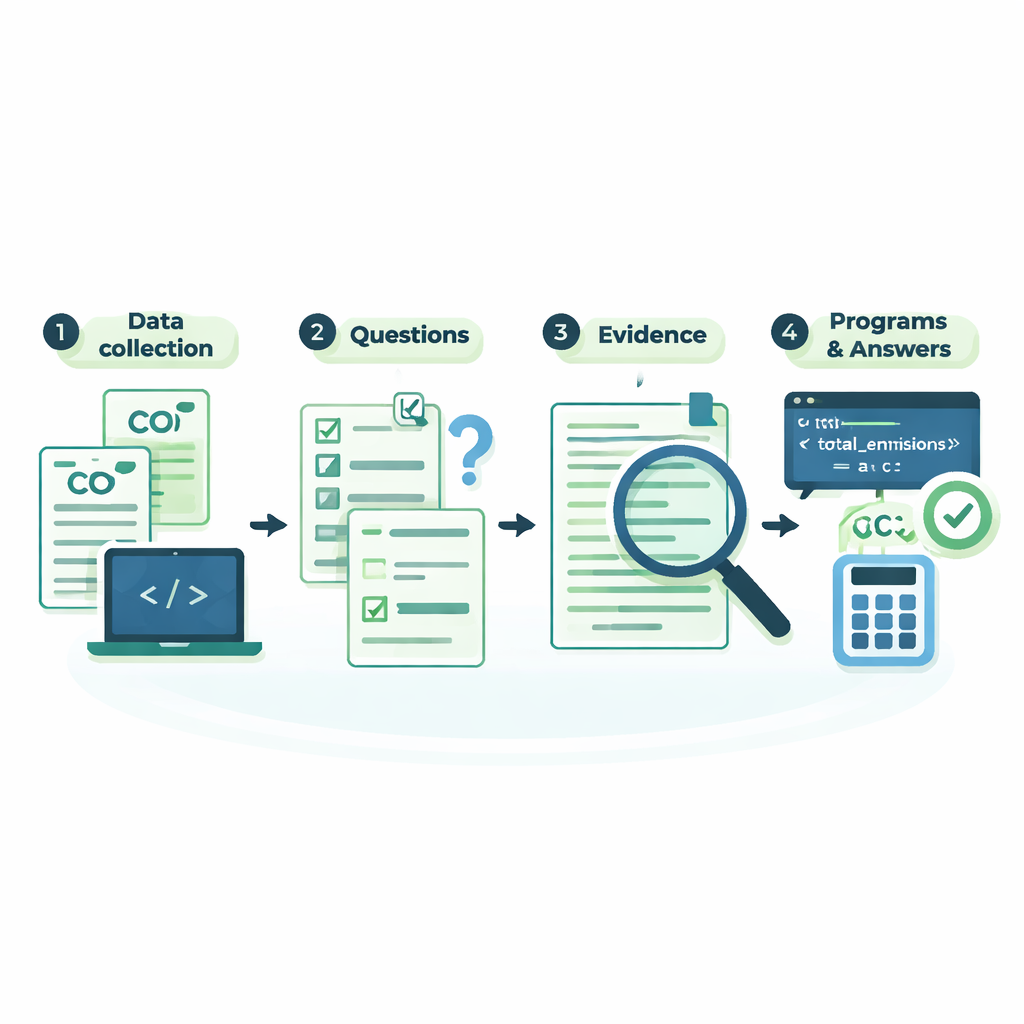
Hur den nya datamängden byggs och kontrolleras
Bakom kulisserna utformar författarna ett noggrant arbetsflöde så att den extraherade informationen kan litas på. Efter att ha laddat ner PDF-filerna och parsat dem till text använder de reguljära uttryck—precisa sökmönster—för att lokalisera komponentnamn, procenttal och totalavtryck, även när de är inbäddade i diagram. Misstänkta poster, såsom produkter vars siffror inte går ihop eller ligger långt utanför ett företags typiska spann, flaggas och kontrolleras manuellt mot originalfilerna. För varje fråga registrerar datamängden också de exakta teckenpositionerna för den stödjande texten i rapporten, tillsammans med ett kort datorprogram som återberäknar svaret steg för steg. Att köra dessa små program och jämföra deras utdata med lagrade svar ger ett extra valideringslager.
Vad siffrorna avslöjar om enheter
Eftersom datamängden spårar många olika märken och produkttyper ger den en första bred bild av hur elektronikens koldkostnad är fördelad. Tyngre maskiner som arbetsstationer, stationära datorer och servrar har i allmänhet mycket högre avtryck än surfplattor, som är mindre och innehåller färre delar. Inom en enskild enhet dominerar vissa komponenter konsekvent: skärmar, huvudkretskort och nätaggregat ansvarar vanligtvis för de största delarna av tillverkningsutsläppen, medan förpackning och batterier bidrar relativt lite. Datamängden noterar också vilken koldioxidberäkningsmetod varje företag använder, vilket belyser att de flesta produkter förlitar sig på en enda, delvis ogenomskinlig modell vars antaganden kan vara föråldrade—en viktig reservation vid jämförelser mellan märken.
Vad detta innebär för framtidens klimatsmarta teknik
För icke-experter är huvudbudskapet att elektronikens klimatpåverkan nu kan studeras på ett mer systematiskt sätt. Genom att omvandla ostrukturerade koldioxidrapporter till en standardiserad fråge–svarsresurs lägger detta arbete grunden för verktyg som automatiskt kan jämföra produkter, peka ut de smutsigaste komponenterna och utforska ”tänk om”-scenarier för grönare konstruktioner. När tillverkare utökar sin rapportering till att omfatta andra miljöskador kan liknande metoder hjälpa samhället att konkret se hur designval för våra telefoner och datorer översätts till påfrestningar på planeten—och var de största möjligheterna till förbättring finns.
Citering: Zhao, K., Koyatan Chathoth, A., Balaji, B. et al. An electronic product carbon footprint dataset for question answering. Sci Data 13, 228 (2026). https://doi.org/10.1038/s41597-026-06544-5
Nyckelord: koldioxidavtryck, elektronik, hållbarhetsdata, livscykelanalys, fråge- och svarsbedömning