Clear Sky Science · sv
Tillförlitlighet hos stora språkmodeller som medicinska assistenter för allmänheten: en randomiserad förregistrerad studie
Varför din telefon kanske inte är den bästa första läkaren
Fler och fler vänder sig till AI-chattbotar för hjälp när de mår dåligt, i hopp om snabba svar på om de bör oroa sig, vad deras symtom kan betyda och om de behöver söka sjukhusvård. Denna studie ställer en enkel men brådskande fråga: om vanliga människor använder kraftfulla språkmodeller som medicinska hjälpmedel hemma, fattar de verkligen bättre beslut om sin hälsa — eller kan tekniken ge en falsk känsla av trygghet?
Test av smarta maskiner i verklighetsnära fall
För att ta reda på det designade forskare i Storbritannien tio realistiska medicinska berättelser, till exempel plötslig svår huvudvärk eller andningssvårigheter, baserade på vanliga tillstånd som många av oss kan möta. Ett team av erfarna läkare enades om det bästa ”nästa steget” för varje fall — från att stanna hemma och ta hand om sig själv till att ringa ambulans — och listade de huvudsakliga tillstånd som en noggrann person bör överväga. Därefter tilldelades 1 298 vuxna från hela Storbritannien slumpmässigt ett av fyra alternativ: använda en av tre ledande AI-chattbotar, eller använda det de normalt skulle förlita sig på hemma, såsom webbsökning eller personlig erfarenhet.
Hur människor och maskiner presterade — var för sig och tillsammans
När språkmodellerna testades på egen hand, genom att ge dem fullständiga fallbeskrivningar och be om en diagnos och rekommenderad åtgärd, presterade de imponerande väl. Över de tre systemen föreslog de korrekt minst ett relevant medicinskt tillstånd i ungefär 95 % av fallen och valde rätt allvarlighetsnivå mer än hälften av gångerna — avsevärt bättre än slumpen. På pappret såg dessa system ut som starka kandidater för att vägleda oroade patienter.
När AI-råd möter verkliga människor
Men när vardagsanvändare kom in i bilden förändrades bilden. Deltagare som använde AI var inte mer exakta än kontrollgruppen när det gällde att välja vad man skulle göra härnäst, och de var faktiskt sämre på att namnge relevanta bakomliggande tillstånd. Personer i icke-AI-gruppen var ungefär 1,8 gånger mer benägna att identifiera ett korrekt tillstånd än de som använde chattbotar. De flesta deltagare i alla grupper underskattade hur allvarlig situationen var. Med andra ord hjälpte inte tillgång till en avancerad språkmodell människor att bättre förstå sina symtom, och det drev dem inte tydligt mot säkrare val.
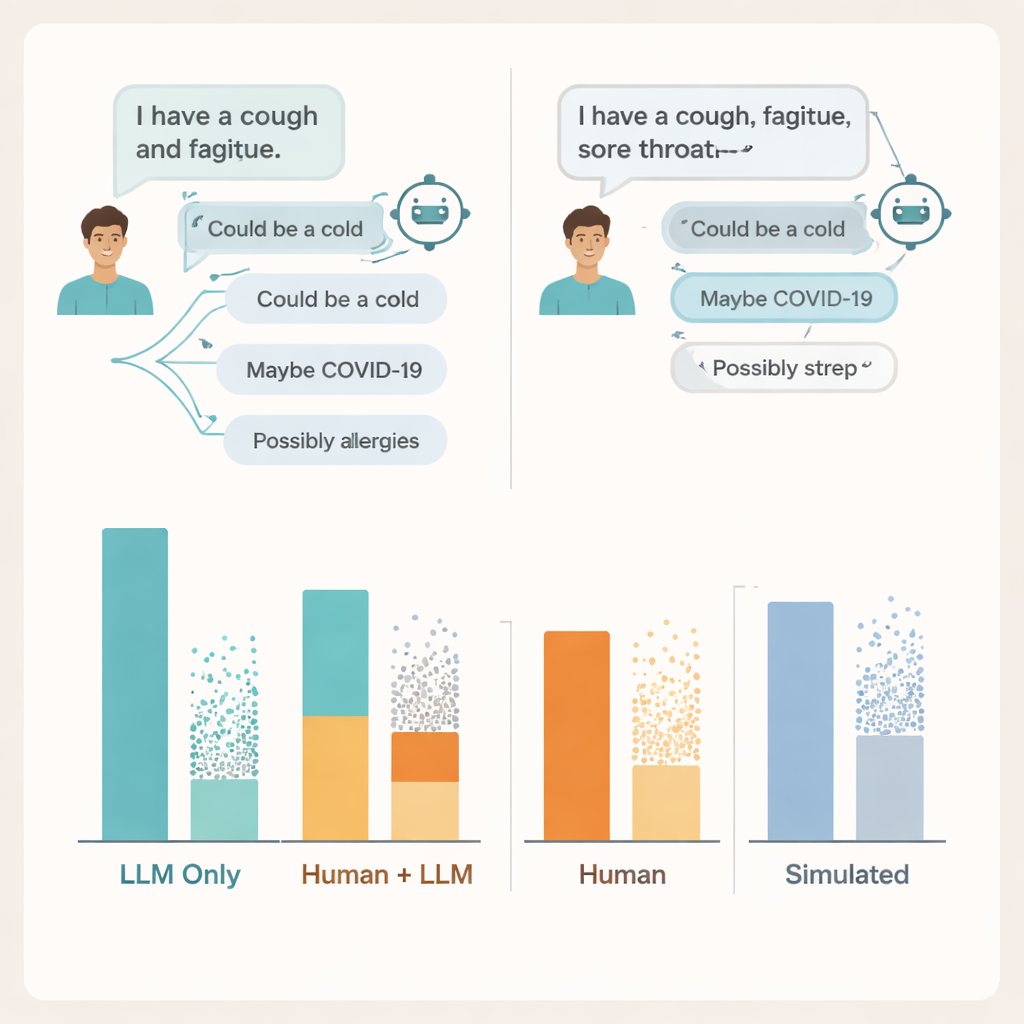
Var samtalet bryter ihop
För att förstå varför grävde forskarna i de faktiska chatttranskripten. De fann problem på båda sidor av samtalet. Många användare delade inte tillräckligt med detaljer om sina symtom för att AI:n skulle kunna ge välgrundade råd — precis som patienter ibland utelämnar viktig information när de talar med en läkare. Själva modellerna nämnde ofta åtminstone ett relevant tillstånd, men de lade också till flera felaktiga eller distraherande möjligheter, och användarna hade svårt att avgöra vilka förslag som var viktiga. I vissa fall ledde nästan identiska symtombeskrivningar till mycket olika råd från samma modell, vilket gjorde det svårt för människor att få en klar uppfattning om när de kunde lita på vad de såg på skärmen.
Varför standardtester missar de verkliga riskerna
Teamet jämförde också dessa resultat med två populära sätt att bedöma medicinska AI: flervalsfrågor från prov och helt simulerade ”patient”-samtal som kördes mellan två modeller. På båda såg systemen igen starka ut, nådde eller överträffade typiska godkända poäng på provliknande frågor och fungerade bättre med simulerade patienter än med verkliga. Ändå stämde inte höga provpoäng och polerade simulerade samtal överens med hur väl verkliga människor klarade sig när de använde samma verktyg. Benchmarktester som prövar kunskap isolerat, menar författarna, missar den röriga, sköra naturen i verkliga mänskliga–AI-interaktioner.
Vad detta betyder för patienter och vårdsystem
För tillfället, sluter studien, är nuvarande allmänna språkmodeller inte redo att fungera som osupervisade frontlinjerådgivare för allmänheten. De rymmer tydligt en stor mängd medicinsk kunskap, men den kunskapen översätts inte automatiskt till säkrare val när oroliga människor skriver in ofullständiga, förvirrade frågor hemifrån. Att göra AI verkligt hjälpsam i höginsatsmiljöer som sjukvård kräver mer än bättre provresultat — det kräver omsorgsfull utformning, testning med mångfaldiga verkliga användare och strängare kontroller över hur information samlas in, förklaras och betros i samtalets fram- och åter.
Citering: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Nyckelord: medicinska chattbotar, självdiagnos, AI inom sjukvård, patienters beslutsfattande, stora språkmodeller