Clear Sky Science · sv
Sammanställa vetenskaplig litteratur med återhämtningsförstärkta språkmodeller
Varför det är så svårt att hänga med i vetenskapen
Varje år publiceras miljontals nya vetenskapliga artiklar online. Ingen mänsklig forskare kan rimligen läsa dem allihop, samtidigt som viktiga medicinska behandlingar, klimatinsikter och tekniska genombrott kan vara dolda i denna informationsström. Den här artikeln undersöker om avancerade AI-system kan hjälpa forskare att söka i detta hav av studier och väva dem till tydliga, trovärdiga sammanfattningar—utan att hitta på saker.
En ny typ av forskningsassistent
Författarna presenterar OpenScholar, ett artificiellt intelligenssystem byggt specifikt för att läsa och syntetisera vetenskaplig litteratur. Till skillnad från generella chattbottar är OpenScholar tätt kopplat till en jättelik öppen databas med cirka 45 miljoner forskningsartiklar, kallad OpenScholar DataStore. När en forskare ställer en fråga—till exempel hur man kyler leviterade nanopartiklar eller vilka metoder som fungerar bäst för hjärnavbildning—söker systemet först igenom databasen efter relevanta utdrag och utformar sedan ett svar med inlinereferenser, ungefär som en mänskligt författad översiktsartikel. Det upprepar denna process flera gånger, kritiserar och förfinar egna utkast för att förbättra klarhet, fullständighet och citeringskvalitet.
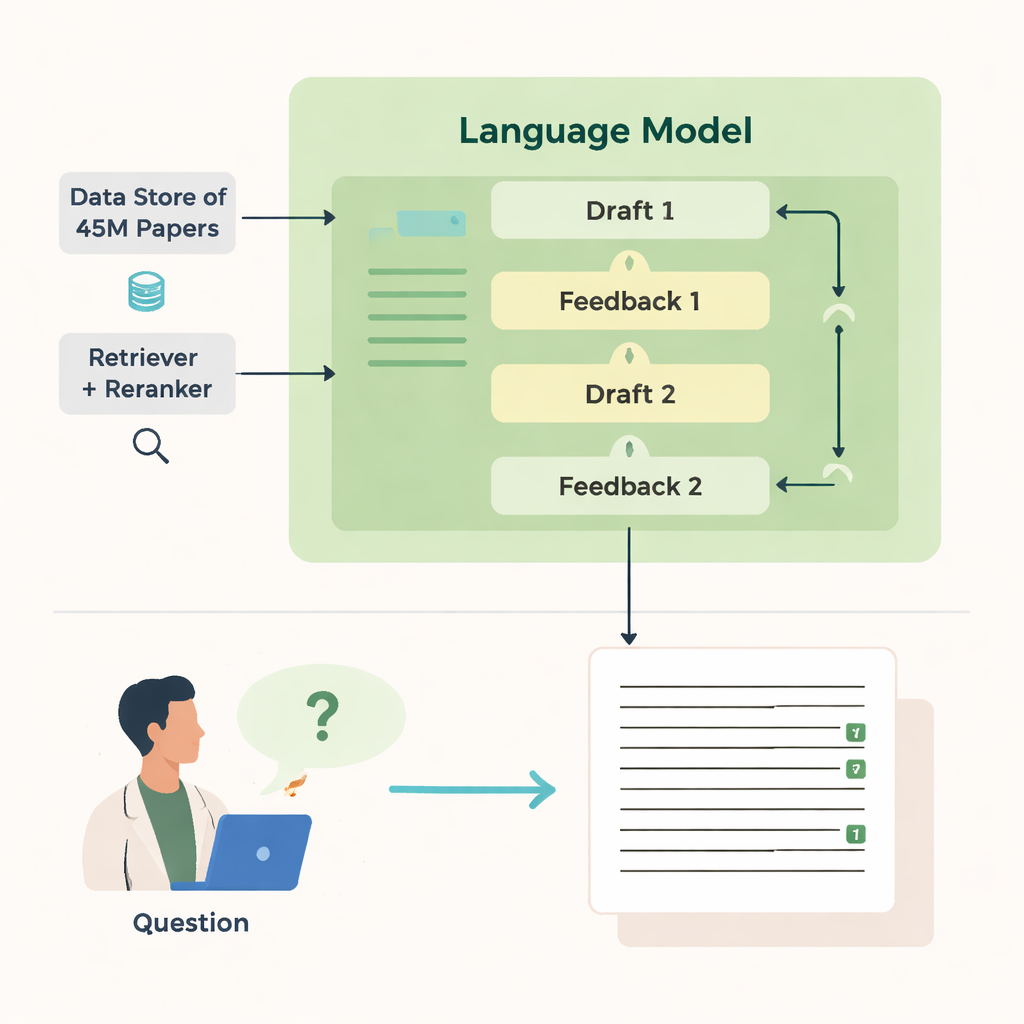
Hur det söker och skriver
OpenScholars styrka kommer från flera samordnade delar. En ”retriever”-modul genomsöker förberäknade textinbäddningar från miljontals artiklar för att hitta lovande utdrag, medan en ”reranker” omordnar dessa utdrag för att fokusera på de mest relevanta. Språkmodellen använder sedan dessa bevis för att producera ett utförligt svar med numrerade referenser. Efter första utkastet genererar modellen feedback till sig själv—pekar ut saknade perspektiv, svag struktur eller tunt stöd—och sätter vid behov igång mer riktade sökningar. Den skriver sedan om svaret, väver in nya artiklar och justerar citeringar. En slutlig kontroll säkerställer att påståenden som behöver stöd backas upp av minst en hämtad källa.
Sätta påståenden och citat på prov
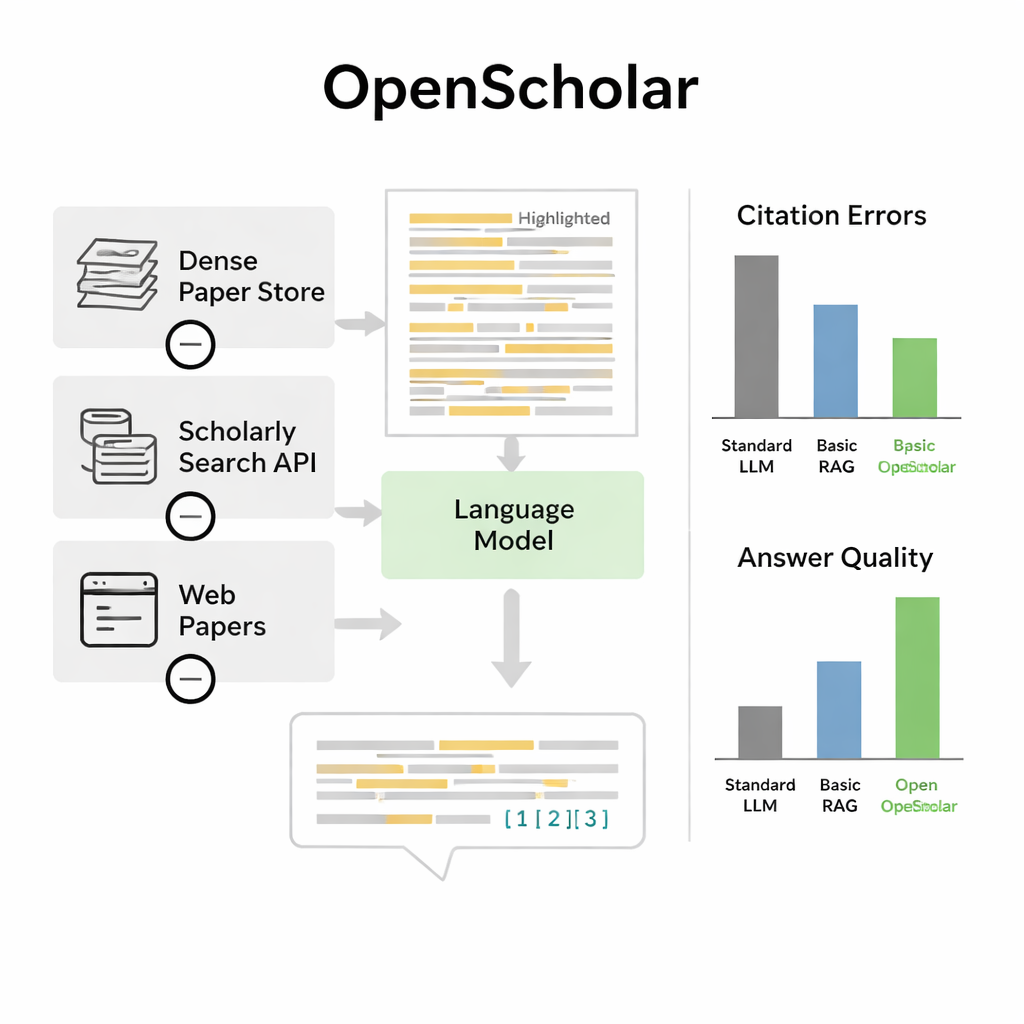
För att avgöra om OpenScholar faktiskt hjälper skapade författarna ScholarQABench, en stor benchmark designad för att efterlikna verkliga litteraturöversiktsfrågor. Den innehåller nästan 3 000 expertformulerade frågor och hundratals långa svar inom datavetenskap, fysik, neurovetenskap och biomedicin. Viktigt är att dessa frågor vanligtvis kräver läsning av flera artiklar, inte bara ett abstract. Teamet utvärderade systemen längs flera axlar: faktuell korrekthet, hur väl svaren täckte nyckelpunkter, skrivklarhet och hur noggrant citeringar återspeglade de underliggande artiklarna. De kombinerade automatiska kontroller med detaljerade bedömningar från doktorsnivåexperter som jämförde AI-genererade svar med mänskligt skrivna.
Slår starka chattbottar och matchar experter
På denna benchmark presterade OpenScholar bättre än både standard-språkmodeller och tidigare verktyg som enkelt kopplat återvinning till en generell chattbot. En kompakt åtta-miljard-parametersversion, helt tränad på öppna data, klarade en krävande syntesuppgift över flera artiklar bättre än GPT-4o och ett konkurrerande system kallat PaperQA2, trots att dessa förlitade sig på större proprietära modeller. En anmärkningsvärd upptäckt var hur ofta vanliga chattbottar hallucinerade referenser: i 78–90 procent av fallen innehöll deras citeringslistor artiklar som inte existerade eller som inte stödde påståendena. Däremot stod OpenScholars citeringsnoggrannhet i paritet med mänskliga experter. När experter jämförde svar direkt föredrog de OpenScholar-8B framför expert-skrivna svar ungefär hälften av gångerna, och en OpenScholar-pipelined som byggde på GPT-4o omkring 70 procent av gångerna, huvudsakligen eftersom AI:n täckte fler relevanta studier och organiserade dem tydligt.
Begränsningar och framtida förbättringar
Trots dessa framsteg betonar författarna att OpenScholar inte är en ersättning för forskare. Systemet kan fortfarande missa de mest representativa artiklarna, överbetona mindre viktiga arbeten eller introducera faktiska felaktigheter, särskilt i mer kompakta modeller. Själva benchmarket har också begränsningar: det fokuserar främst på datavetenskap, biomedicin och fysik, och de noggrant annoterade frågorna är fortfarande relativt få eftersom expertiden är dyrbar. Utvärderingar har också svårt att fullt ut fånga mer subtila kvaliteter, som huruvida citeringar lyfter fram verkligt banbrytande arbete eller om ett svar faktiskt skulle guida ett nytt experiment.
Vad detta betyder för vardaglig vetenskap
För icke-specialister är huvudslutsatsen att noggrant utformade AI-verktyg redan kan hjälpa forskare att navigera vetenskaplig litteratur mer effektivt, förutsatt att de är kopplade till verkliga data och hålls till strikta standarder för bevis och transparens. OpenScholar visar att när ett AI-system byggs från grunden för att hämta, kontrollera och citera verkliga artiklar—och när dess prestanda prövas mot mänskliga experter—kan det producera litteratursammanfattningar som inte bara är läsbara utan också verifierbara. I praktiken kan sådana verktyg frigöra forskare att i större utsträckning fokusera på att utforma experiment och tolka resultat, samtidigt som människan fortsatt har sista ordet i bedömningen av vad som är sant och viktigt.
Citering: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Nyckelord: översikt av vetenskaplig litteratur, återhämtningsförstärkta språkmodeller, OpenScholar, citeringsnoggrannhet, AI-verktyg för forskning