Clear Sky Science · sv
Språkmodellsstyrd förutsägelse och upptäckt av däggdjursmetaboliter
Den dolda kemin i våra kroppar
Varje droppe blod eller urin innehåller tusentals små molekyler som speglar vad vi äter, hur vi lever och om vi blir sjuka. För de flesta av dessa molekyler känner forskare dock inte till deras namn eller funktioner. Denna artikel presenterar DeepMet, ett artificiellt intelligenssystem som läser molekylernas ”språk” och förutser vilka som saknas i våra nuvarande kartor över mänsklig och animalisk kemi. Genom att styra experiment mot de mest lovande kandidaterna hjälper DeepMet forskare att avslöja denna kemiska mörka materia och förstå bättre hur våra kroppar fungerar.
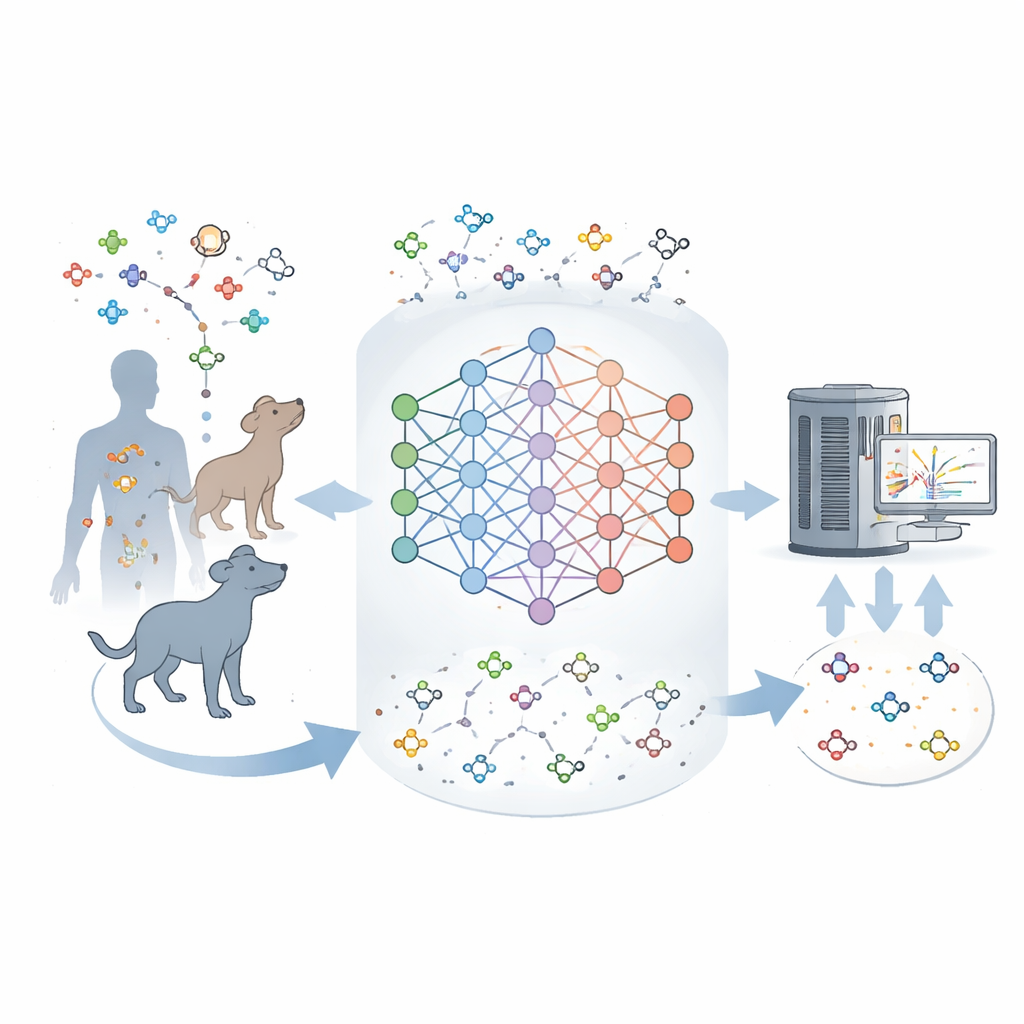
Varför så många molekyler förblir okända
Moderna instrument kan väga och delvis fingeravtrycka tusentals molekyler i ett vävnadsprov samtidigt. Men att omvandla dessa fingeravtryck till exakta strukturer är svårt. Befintliga databaser listar många kända metaboliter, ändå matchar de flesta signaler som ses i verkliga prover ingenting i dessa kataloger. Denna lucka antyder att nuvarande kartor över metabolismen är ofullständiga och att många naturliga molekyler hos däggdjur aldrig har beskrivits. Författarna satte ut för att bygga ett verktyg som kan lära sig från kända metaboliter och sedan föreställa sig de mest sannolika saknade, på ungefär samma sätt som språkmodeller förutser sannolika ord i en mening.
Att lära en maskin metabolismens grammatik
Gruppen tränade ett neuralt nätverk kallat DeepMet på omkring 2 000 väl etablerade mänskliga metaboliter, kodande varje som en kort sträng som beskriver dess struktur. Efter initial träning på läkemedelslika molekyler för att lära sig allmänna kemiska regler, finslipades DeepMet på denna uppsättning metaboliter. När modellen ombads generera nya strukturer producerade den molekyler som befann sig i samma regioner av kemiskt rum som verkliga metaboliter och återgav till och med många kända typer av enzymreaktioner, trots att den aldrig uttryckligen fick dessa regler. Med andra ord verkade DeepMet internalisera den oskrivna grammatiken som länkar grundläggande byggstenar såsom socker och aminosyror till biologiskt realistiska småmolekyler.
Att förutsäga vilka nya molekyler sannolikt existerar
Forskarna provade därefter en miljard kandidat‑molekyler från DeepMet och räknade hur ofta varje unik struktur uppträdde. Ofta upprepade strukturer såg ut att likna kända metaboliter, dela vanliga kemiska kärnor med dem och stämma överens med plausibla enzymtransformationer. För att testa om dessa högfrekventa kandidater motsvarar verkliga molekyler jämförde teamet DeepMets förutsägelser med metaboliter som lades till Human Metabolome Database efter att modellens träningsdata stängts. DeepMet hade redan genererat de flesta av dessa senare upptäckter och rankat många av dem bland sina mest sannolika kandidater. Av de tusentals topp‑rankade strukturer som saknades i databasen köpte eller syntetiserade författarna 80 och kontrollerade verkliga mänskliga prover med masspektrometri. De bekräftade närvaron av flera tidigare oigenkända metaboliter, några av vilka hade förbises trots att de förekommer i befintlig litteratur.
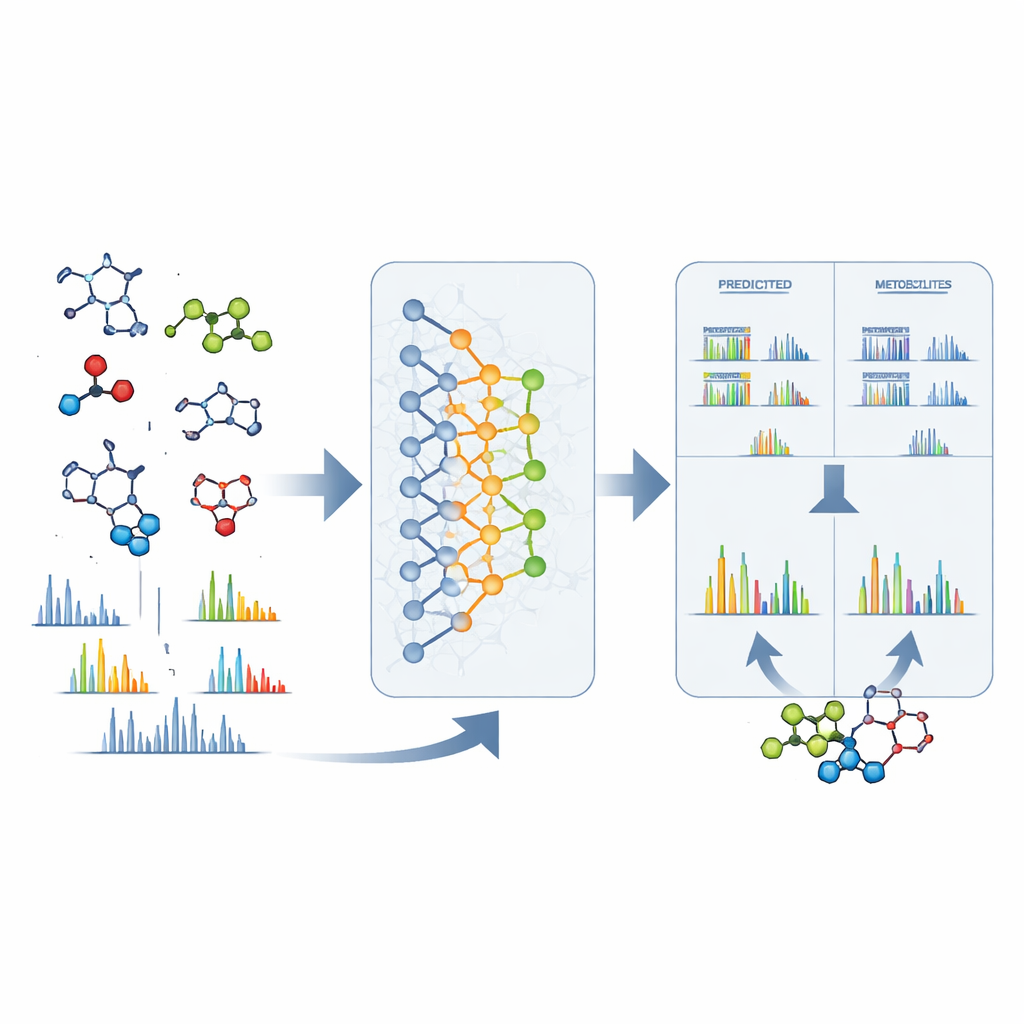
Från råa signaler till konkreta strukturer
DeepMet är också användbart när en okänd topp har observerats i en masspektrometer. Givet endast den exakta massan av en mystisk molekyl kan modellen lista många strukturer som skulle väga lika mycket och rangordna dem efter hur metabolit‑lika de verkar. I nästan en tredjedel av testfallen hamnade den korrekta strukturen i topposition; i många fler fanns den bland endast ett fåtal högt rankade kandidater och var vanligtvis mycket lik modellens favoriter i form. För att ytterligare begränsa alternativen kombinerade författarna DeepMet med separat programvara som förutspår hur varje kandidat skulle brytas isär i en masspektrometer. Att matcha dessa förutsagda mönster med verkliga experimentella spektra fördubblade ungefär identifieringsnoggrannheten. Sökning i stora offentliga dataset med denna kombinerade metod gav tentativa strukturer för många tidigare anonyma signaler och pekade ut metaboliter som skiljer sig mellan sjukdomar, kost och tarmmikrobiomets tillstånd.
Att belysa livets kemiska mörka materia
Genom att förena kemisk intuition lärd från data med kraftfull mönsterigenkänning mot masspektra ger DeepMet en färdplan för att upptäcka nya metaboliter på ett riktat, praktiskt sätt. Den kan ännu inte avslöja varje okänd molekyl—vissa strukturer ligger för långt från dem den sett, och vissa isomerer förblir omöjliga att särskilja utan specialiserade metoder. Men studien visar att verktyg i stil med språkmodeller inte bara kan uppfinna realistiska molekyler, de kan också förutse verkliga föreningar som biologer senare bekräftar i djur och människor. För en lekmannaläsare är slutsatsen att AI nu kan hjälpa kemister att systematiskt avslöja dold kemi i våra kroppar, potentiellt avslöjande nya biomarkörer, spåra diet–mikrob–värd‑kopplingar och successivt omvandla dagens metaboliska mörka materia till morgondagens välkartlagda biologi.
Citering: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Nyckelord: metabolomik, kemiska språkmodeller, DeepMet, masspektrometri, metaboliskt mörk materia