Clear Sky Science · sv
Avtäckande av nyckeltoppegenskaper för autentisering av olivolja med hjälp av Raman-spektroskopi och kemometri
Varför berättelsen om olivoljebedrägeri är viktig
När du betalar extra för en flaska olivolja förväntar du dig äkta vara, inte en blandning tyst utspädd med billigare fröoljor. Eftersom olivolja är värdefull och världshandeln är komplex är dock bedrägeri och felmärkning vanliga problem. Denna studie presenterar ett snabbt, icke‑destruktivt sätt att avslöja sådana trick genom att belysa oljor med laserljus och låta smarta datorprogram läsa de dolda kemiska fingeravtrycken. Metoden syftar till att hjälpa konsumenter, ärliga producenter och tillsynsmyndigheter genom att göra det enklare att kontrollera om innehållet i flaskan stämmer med etiketten.
Belysa för att läsa oljornas fingeravtryck
Forskarnas metod var Raman‑spektroskopi, som går ut på att rikta en fokuserad ljusstråle mot ett prov och mäta hur ljuset sprids tillbaka. Olika molekyler vibrerar på sitt sätt och lämnar ett mönster av toppar i det resulterande spektret, ungefär som en streckkod. Olivolja och vanliga förfalskningsoljor som solros-, raps‑ och majsolja har olika sammansättningar av fettsyror och naturliga pigment, så deras spektra är inte identiska. Genom att studera dessa mönster i rena oljor och noggrant förberedda blandningar kunde teamet identifiera ett litet antal ”nyckeltoppar” vars form och styrka förändrades pålitligt beroende på hur mycket olivolja som fanns i en blandning.
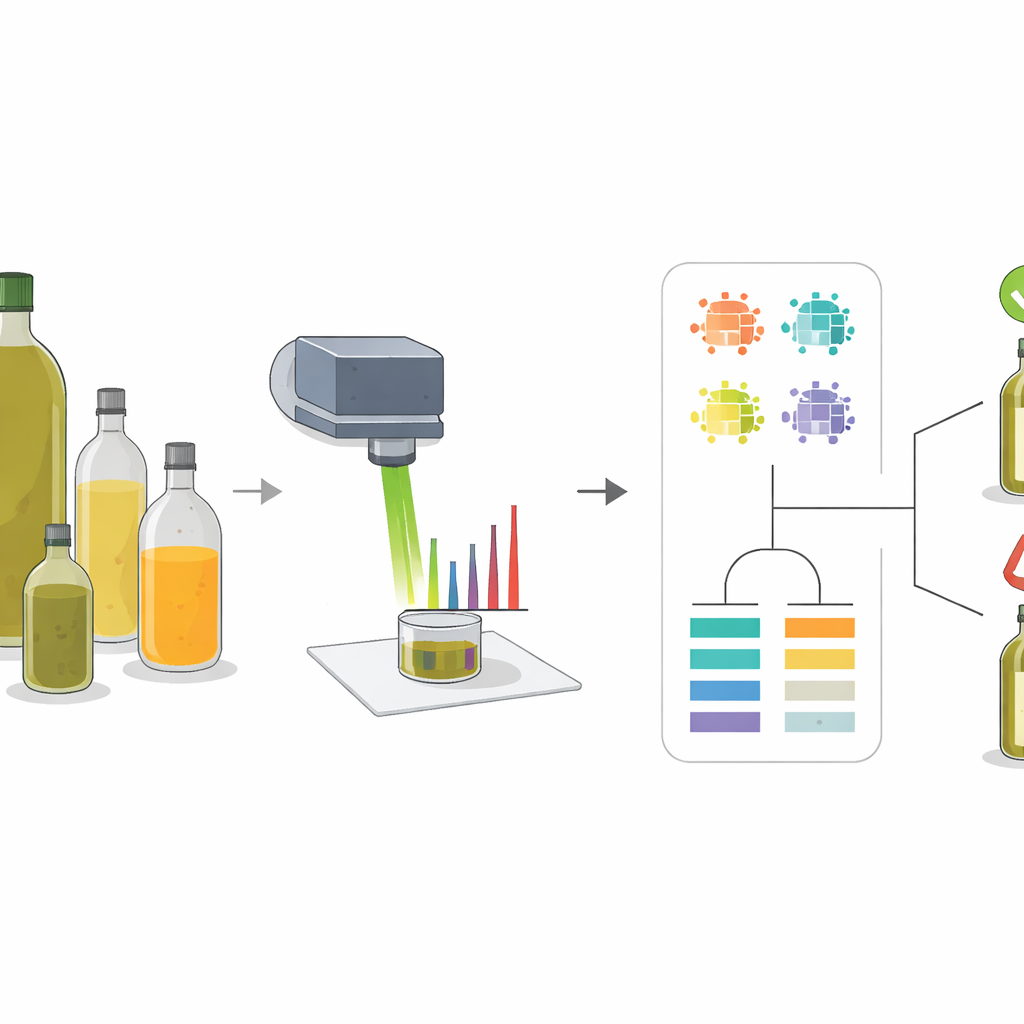
Hitta de mest avslöjande signalerna
I stället för att luta sig mot en enda mätning extraherade teamet flera beskrivare från varje viktig topp: hur hög den var (intensitet), hur stor area den täckte, hur bred den var halvvägs upp och hur dess area jämförde sig med andra toppars. De använde sedan klustring och korrelationskartor för att se hur dessa beskrivare grupperade olika oljor och hur de försköts när olivoljeinnehållet ökade. Toppar kopplade till färgämnen såsom beta‑karoten och till särskilda typer av omättade fetter visade sig vara särskilt informativa. Till exempel blev vissa toppar starkare när andelen olivolja ökade, medan andra minskade eftersom de var kopplade till linolsyra, som är vanligare i solrosolja. Denna mångsidiga analys fångade subtila skillnader som skulle ha missats om man bara använt en enda intensitetsvärde.
Låt algoritmer sortera äkta från förfalskat
För att omvandla dessa spektrala fingeravtryck till praktiska beslut tränade författarna flera maskininlärningsmodeller. Först fick modellerna klassificera tio oljetyper, inklusive fyra rena oljor och sex typer av binära och ternära blandningar. Träd‑baserade metoder — slumpmässiga skogar och gradient‑boostade träd — presterade bäst och tilldelade nästan alla prover rätt kategori när de gavs det fulla uppsättningen toppfunktioner. Därefter användes samma typ av modeller för numerisk prediktion: att uppskatta den faktiska andelen olivolja i två‑ och tre‑oljeblandningar. Återigen överträffade trädmetoderna mer traditionella metoder och följde noggrant olivoljeinnehållet även när signaler från olika oljor överlappade kraftigt i spektret.
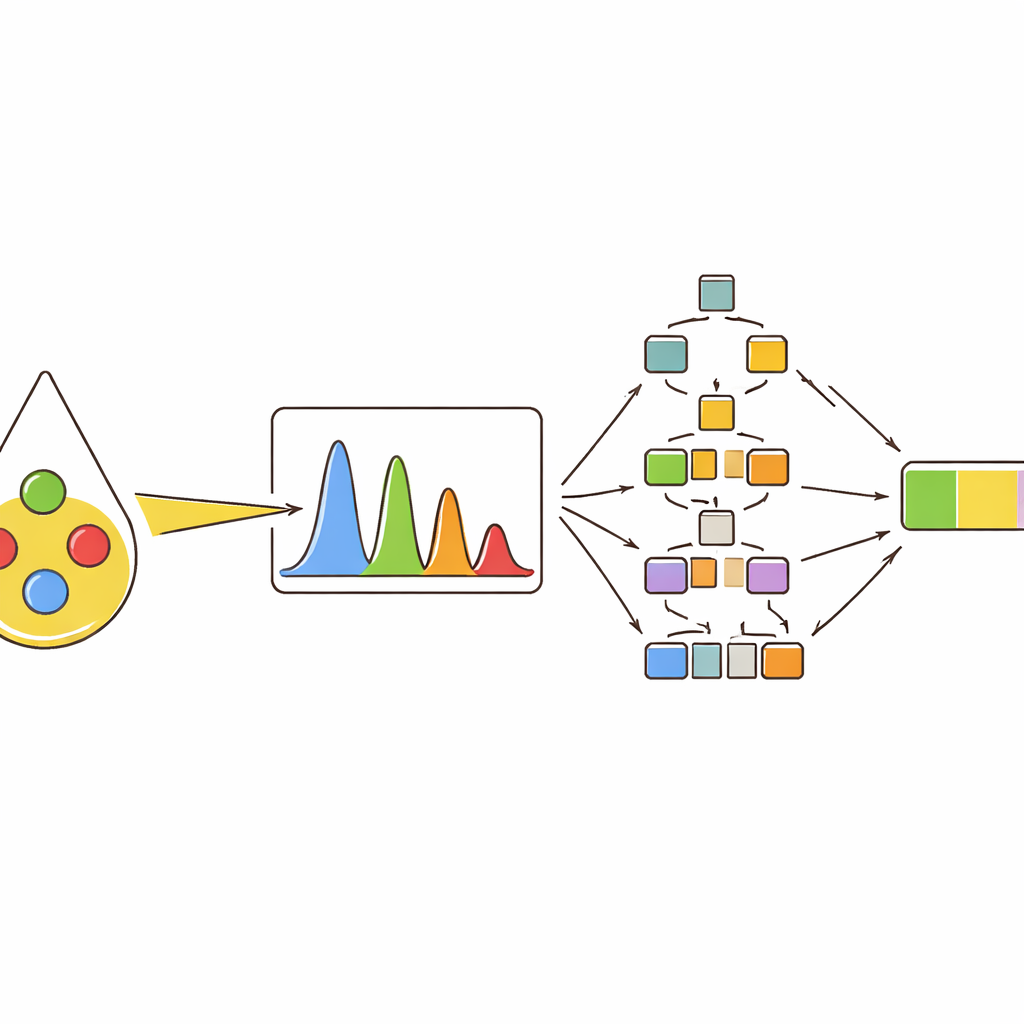
Öppna den svarta lådan hos smarta modeller
Många kraftfulla maskininlärningsverktyg är svåra att tolka; de kan fungera bra men ger lite insikt i varför de fattade ett visst beslut. För att tackla detta använde studien en förklaringsmetod som tilldelar varje indatafunktion ett bidrag till slutgiltig prediktion. Det visade att ett fåtal specifika toppar dominerade modellernas bedömningar och konsekvent drev den predicerade olivoljeandelen uppåt eller nedåt beroende på deras värden. Samma toppar fortsatte att framträda som viktigast över olika blandningstyper och i tester på kommersiella butiksoljor, som innehöll endast en liten mängd olivolja. För dessa verkliga prov uppskattade de bästa modellerna olivoljeinnehållet mycket nära det verkliga värdet, vilket stöder både tillförlitligheten och transparensen i tillvägagångssättet.
Vad detta betyder för din flaska hemma
I praktiska termer visar arbetet att en snabb ljusskanning, tolkad av välutformade och förklarbara datormodeller, kan avslöja om en ”olivolja” är ren, kraftigt utspädd eller någonstans mittemellan. Genom att fokusera på ett fåtal robusta spektrala egenskaper och kombinera dem i avancerade men tolkningsbara algoritmer byggde forskarna ett verktyg som skulle kunna integreras i rutinmässiga kvalitetskontroller, potentiellt även i bärbara enheter. Även om bredare testning över fler regioner, sorter och typer av bedrägerier fortfarande behövs, pekar detta ramverk mot en framtid där verifiering av högvärdiga livsmedels äkthet, som olivolja, blir snabbare, enklare och mer pålitlig för alla.
Citering: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Nyckelord: autentisering av olivolja, upptäckt av livsmedelsbedrägeri, Raman‑spektroskopi, maskininlärning, kvalitet på ätliga oljor