Clear Sky Science · sv
Textmining‑stödd maskininlärningsprediktion och experimentell validering av emissionsvåglängder
Att förvandla vetenskaplig text till ljus
Varje år publicerar forskare tiotusentals artiklar om material som lyser — ämnen som används i mobilskärmar, medicinska skannrar och strålningsdetektorer. Djupt inne i dessa texter finns mätningar av exakt vilka färger olika material avger, men informationen är spridd, skriven på inkonsekventa sätt och svår för datorer att använda. Denna studie visar hur man automatiskt kan läsa litteraturen, omvandla den till en stor, pålitlig datamängd och sedan använda maskininlärning för att förutsäga vilken färg ljus nya material kommer att avge — vilket hjälper forskare att ta fram bättre fosforer mycket snabbare.
Varför lysande material spelar roll
Fosforer är material som absorberar energi och återutsänder den som synligt ljus. De ligger i centrum för tekniker som ultra‑högupplösta displayer, vita LED:ar, medicinsk avbildning och strålningsdetektion. Ingenjörer vill ha fosforer som lyser i mycket specifika färger, förblir ljusstarka vid höga temperaturer och slösar så lite energi som möjligt. Under de senaste två decennierna har forskningen om dessa material exploderat och fyllt den vetenskapliga litteraturen med detaljerade rapporter om kemiska recept och emissionsvåglängder. Ändå är dessa data mestadels låsta i ostrukturerad text — fraser i stycken, bildtexter och experimentsektioner skrivna för människor, inte för datorer. 
Att lära datorer läsa materialartiklar
Författarna byggde en specialiserad textmining‑pipeline anpassad för fosforlitteratur. I stället för att använda generiska språkverktyg skapade de regler som förstår hur kemister faktiskt skriver formler, särskilt för »doppade« material där en liten mängd av ett grundämne läggs till en värdmassa. Systemet kan korrekt känna igen komplexa namn som en värdstruktur följd av flera dopjoner och deras koncentrationer, och kan koppla dessa namn till närliggande siffror som representerar emissionsvåglängder. Det hanterar också knepigt språk, som meningar som säger »det avger vid 630 nm« utan att upprepa materialets namn, eller stycken där flera material och flera våglängder nämns tillsammans. Genom att klassificera varje mening efter hur många material och egenskaper den innehåller, och sedan välja en matchande algoritm för den situationen, minskar pipelinen kraftigt förväxlingar om vilken siffra som hör till vilket material.
Att bygga en ren karta från sammansättning till färg
När de tillämpade denna pipeline på 16 659 vetenskapliga artiklar extraherade teamet cirka 6 400 pålitliga »material–emission«‑par: en fosfors formel, dess emissionspeak‑våglängd, enheten och artikelns digitala identifierare. Noga tester visade hög noggrannhet både i att känna igen fullständiga fosforformler och i att koppla dem till rätt emissionsvärden. Med denna strukturerade datamängd i handen fokuserade forskarna på en särskilt viktig familj: material doperade med europiumjoner (Eu2+), vilka kan avge ljus över ett stort område av det synliga spektrumet beroende på den omgivande kristallen. De beräknade fysikaliskt meningsfulla deskriptorer för varje värd — såsom kristallstrukturdetaljer, bindningslängder och elektroniskt bandgap — och använde sedan funktionsurval för att krympa dessa till de få som spelar störst roll för färgprediktion.
Låta maskininlärning förutsäga glöden
Därefter tränade och jämförde författarna flera maskininlärningsmodeller för att förutsäga emissionsvåglängd från dessa deskriptorer. En algoritm kallad XGBoost presterade bäst och nådde en determinationskoefficient (R²) på omkring 0,91 på osedda testdata — starkt bevis för att modellen fångar de viktigaste sambanden mellan struktur och färg. För att se om tillvägagångssättet fungerar i verkligheten använde de modellen för att föreslå lovande nya Eu2+‑doperade sulfid‑ och nitridfossforer, syntetiserade fyra kandidater i labbet och mätte deras emission. De observerade våglängderna avvek från prediktionerna med bara cirka 10 nanometer, vilket betyder att modellens »gissningar« låg mycket nära experimentell verklighet. 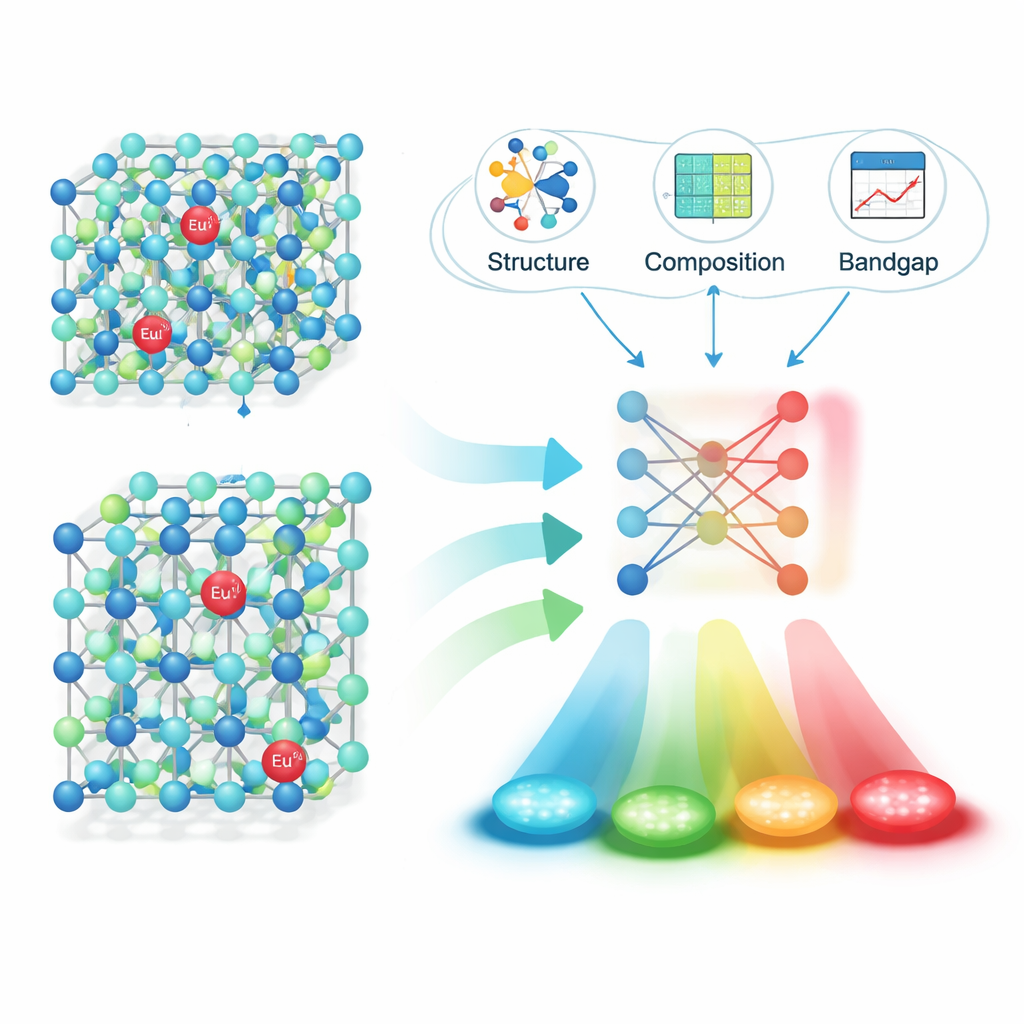
Från artiklar till praktiska designer
För icke‑specialister är huvudbudskapet att detta arbete förvandlar spridda, människoskrivna artiklar till en sammanhängande, sökbar karta som kopplar »vad ett material består av« till »vilken färg det lyser«. Genom att automatisera läsning, organisering och inlärningssteg — och sedan bekräfta prediktioner genom verkliga experiment — beskriver studien en sluten loop: text → data → modell → nytt material. Denna ram kan utvidgas till andra egenskaper som ljusstyrka och stabilitet, och till och med till andra klasser av funktionella material. I förlängningen pekar den mot en framtid där forskare i stället för trial‑and‑error‑arbete i labbet snabbt kan rikta in sig på de mest lovande recepten, vilket påskyndar utvecklingen av bättre belysning, displayer och sensortekniker.
Citering: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Nyckelord: luminescerande material, textmining, maskininlärning, fosforer, prediktion av emissionsvåglängd