Clear Sky Science · sv
Molekylkartering i DNA‑PAINT via modifierad Gaussisk blandningsmodell
Att se molekylernas osynliga värld
Modern biologi förlitar sig i allt högre grad på mikroskop som kan se inte bara celler utan även enskilda molekyler inuti dem. Att förvandla det svaga, flämtande ljuset från dessa molekyler till en pålitlig "karta" över var var och en befinner sig är ändå förvånansvärt svårt. Denna studie presenterar en ny beräkningsmetod, kallad G5M, som gör dessa molekylkartor avsevärt mer exakta och detaljerade, och hjälper forskare att förstå hur proteiner är ordnade och grupperade i verkliga celler, ända ner till några få miljarderdels meter.
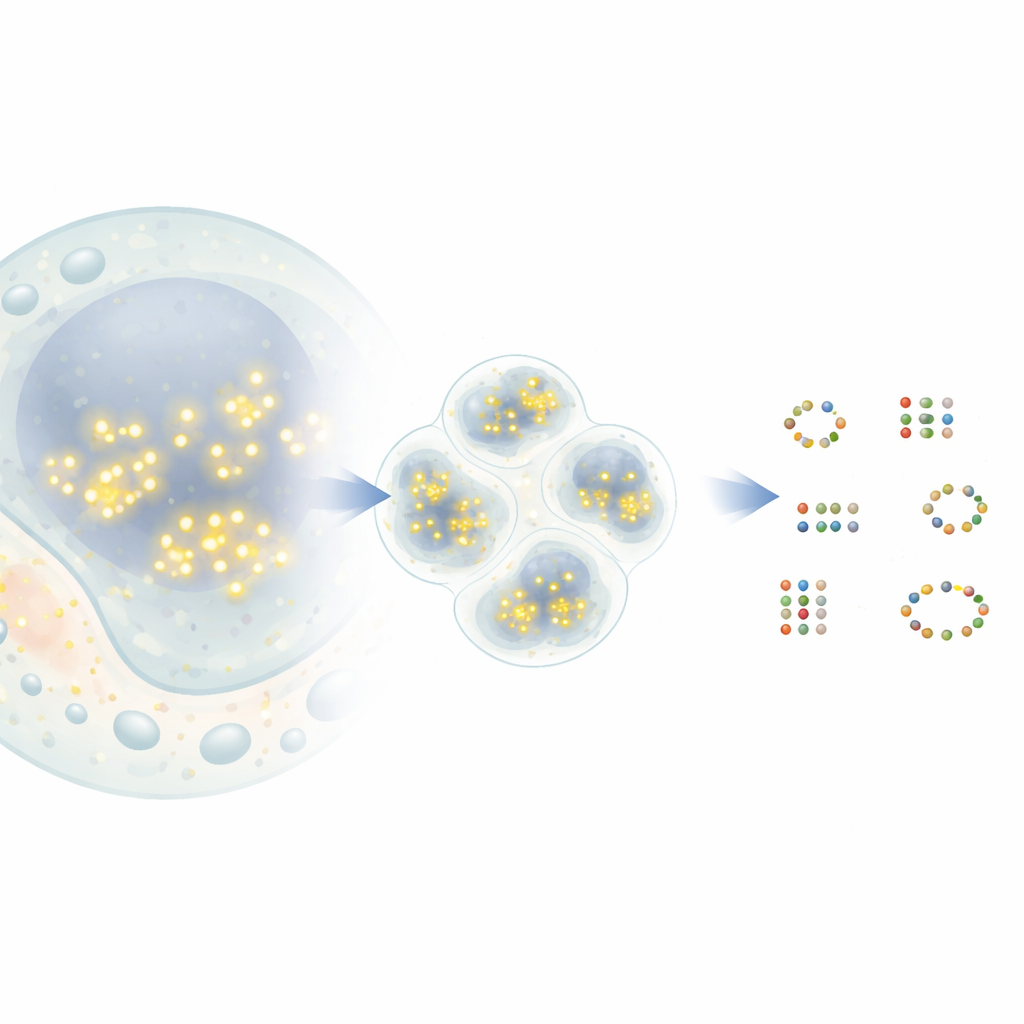
Från blinkande prickar till molekylkartor
I en populär superupplösningsteknik kallad DNA‑PAINT binder och släpper korta DNA‑strängar som bär fluorescerande färgämnen till matchande DNA‑taggar kopplade till målproteiner. Varje gång ett färgämne binder syns det som en ljus prick i mikroskopet innan det försvinner igen. Med tiden skapar många sådana händelser ett moln av prickar runt varje protein. I princip markerar centrumet av varje moln den sanna positionen för ett protein med nanometerprecision. I praktiken kan prickar från närliggande proteiner dock överlappa, och vissa prickar kommer från slumpmässiga bakgrundssignaler. Befintliga analysverktyg slår ofta ihop nära grannar till ett enda protein eller, omvänt, hittar proteiner som inte finns, vilket begränsar hur mycket biologisk insikt som kan utvinnas.
Ett smartare sätt att hitta verkliga molekyler
Den nya metoden, G5M, behandlar svärmen av prickar som en blandning av enkla, klockformade moln, där varje moln motsvarar en verklig molekyl. Istället för att bara gruppera närliggande prickar efter täthet använder G5M en probabilistisk modell som införlivar vad som redan är känt om experimentet: hur exakt positioner kan mätas, hur snabbt DNA‑strängar binder och släpper, och hur mikroskopet suddar ljus i två eller tre dimensioner. Den testar sedan olika möjliga förklaringar—olika antal och former av moln—och väljer automatiskt den som bäst balanserar passform och enkelhet. Ytterligare säkerhetskontroller förkastar misstänkta lösningar, såsom moln som är för smala, för breda, baserade på för få prickar eller inte tydligt separerade från varandra.
Bevisad styrka i simuleringar och DNA‑nanostrukturer
För att testa G5M använde författarna först realistiska datorsimuleringar av enkla scener: par av molekyler och små rutnät av tolv molekyler med avstånd på endast några nanometer. Jämfört med den nuvarande ledande metoden, känd som Gradient Ascent, hittade G5M många fler av de molekyler som borde vara synliga vid den teoretiska upplösningsgränsen, samtidigt som den nästan aldrig rapporterade molekyler som inte fanns. I nyckelfall återvann den nära liggande par 27 gånger oftare än den äldre metoden och förbättrade den effektiva upplösningen med mer än hälften. Teamet bekräftade sedan dessa vinster experimentellt med DNA‑origami‑strukturer—artificiella DNA‑former med dockningsställen placerade på noggrant kända positioner—vilket visade att G5M kunde räkna och lokalisera nästan alla förväntade platser under en rad bildvillkor.
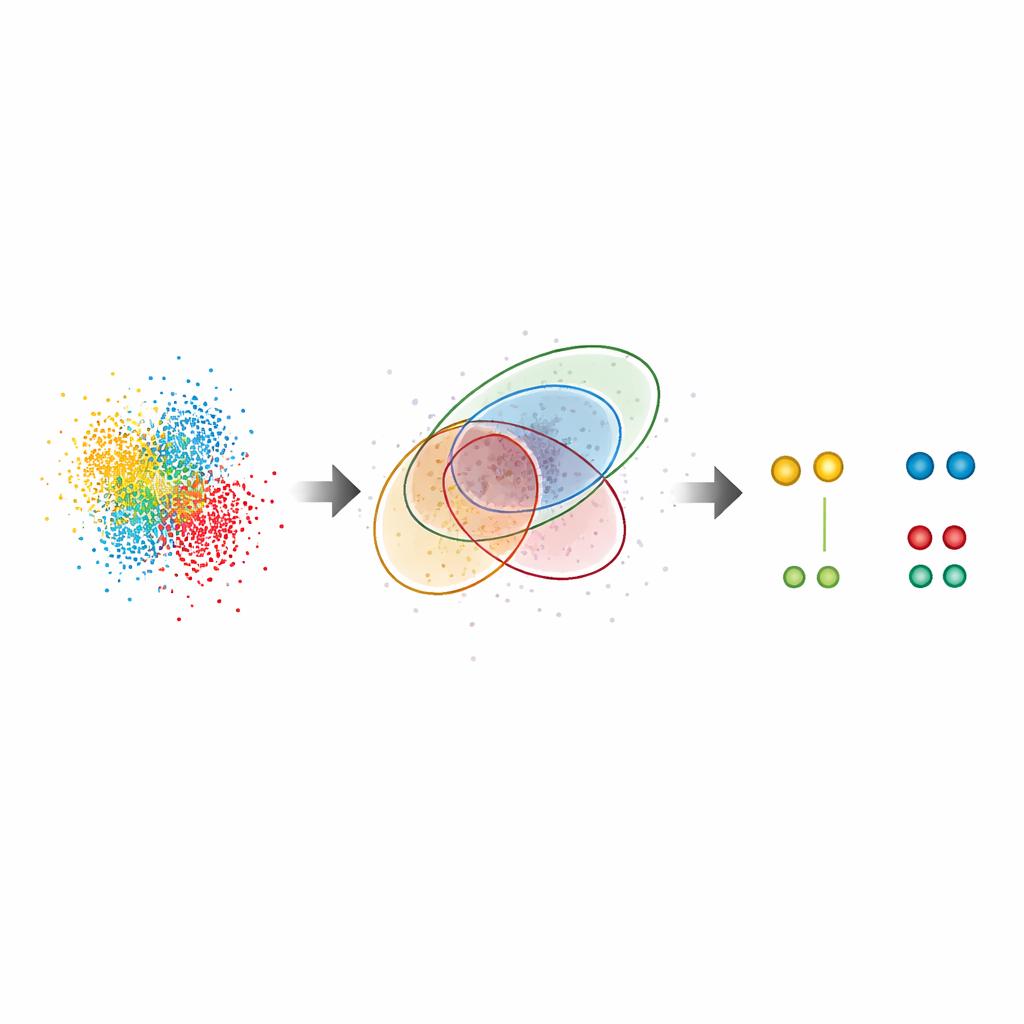
Avslöjar dolda mönster i verkliga celler
Utöver testsampel tillämpades G5M på komplexa biologiska system. I nukleära porekomplex, de stora portarna i cellkärnan, återfann metoden den kända ringliknande ordningen av ett nyckelprotein, Nup96, även där partner var separerade med endast omkring tio nanometer. Den hittade nästan dubbelt så många proteinpar som standardmetoden och reproducerade oberoende uppskattningar av märkningseffektivitet, vilket tyder på att den varken missar många molekyler eller lägger till felaktiga. Författarna undersökte också CD20, en ytreceptor involverad i blodcancer och ett mål för terapeutiska antikroppar. Här avslöjade G5M avsevärt fler små kluster (dimerer, trimerer och tetramerer) av CD20 på cellmembranet, vilket klargjorde hur en anti‑cancerantikropp och relaterade läkemedelsformat omorganiserar dessa receptorer. Den förbättrade till och med prestandan hos ett ultra‑högupplöst tillvägagångssätt kallat RESI, som förlitar sig på att separera signaler över flera bildomgångar.
Vad detta betyder för framtidens mikroskopi
Genom att pressa fram mer tillförlitlig information ur befintliga DNA‑PAINT‑data visar G5M att bättre mjukvara ensam kan låsa upp nya biologiska detaljer, utan att byta mikroskop eller färgämnen. Algoritmen håller falska detektioner extremt låga samtidigt som den kan lösa molekyler som nästan rör vid varandra, vilket är avgörande när man vill veta hur många proteiner som sitter i ett komplex, hur de är placerade eller hur ett läkemedel förändrar deras ordning. Integrerad i den öppna källkodsplattformen Picasso och robust mot typiska inställningar är G5M väl positionerad att bli ett standardverktyg för att förvandla blinkande fluorescens till pålitliga molekylkartor och hjälpa forskare att kartlägga livets nanoskaliga organisering i celler.
Citering: Kowalewski, R., Reinhardt, S.C.M., Pachmayr, I. et al. Molecular mapping in DNA-PAINT via modified Gaussian Mixture Modeling. Nat Commun 17, 2315 (2026). https://doi.org/10.1038/s41467-026-70198-5
Nyckelord: superupplösningsmikroskopi, DNA‑PAINT, molekylkartering, proteinoligomerisering, bildanalysalgoritmer