Clear Sky Science · sv
Nanoporfbaserad massivt parallell detektion för peptidprofilering och proteinidentifiering
Läsa proteiner en molekyl i taget
Proteiner är cellernas arbetsmaskineri, och att veta exakt vilka som finns, hur de är modifierade och hur de interagerar är centralt för att förstå hälsa och sjukdom. Dagens standardverktyg för att studera proteiner är kraftfulla men ofta långsamma, dyra och svåra att skala upp. Denna studie beskriver ett nytt sätt att lyssna på enskilda proteinfragment när de passerar genom ett pyttelitet hål i ett membran, med hjälp av artificiell intelligens för att omvandla signalerna till detaljerade fingeravtryck. Metoden skulle kunna öppna dörren för snabbare och billigare tester för att följa sjukdomsmarkörer och kontrollera hur väl forsknings- och diagnostiska antikroppar faktiskt fungerar.
Göra proteiner till läsbara bitar
Forskarna bygger vidare på nanoporfsteknik, ursprungligen utvecklad för DNA-sekvensering. I deras system klipps naturliga proteiner först i kortare fragment, kallade peptider, och modifieras varsamt så att varje bit kan länkas i båda ändar till korta DNA-strängar. Detta skapar en "Oligo–Peptid–Oligo"-struktur som beter sig väl i nanoporfapparater ursprungligen designade för DNA. Teamet använder ett specifikt klyvningsenzym som tenderar att lämna en viss aminosyra, lysin, i slutet av varje fragment, vilket gör kemin mer förutsägbar och kompatibel med många olika proteiner. Slutresultatet är ett renat bibliotek av många sådana peptid–DNA-konstruktioner framställt på bara några timmar.
Lyssna med många nanoporer samtidigt
För att faktiskt detektera dessa peptidfragment använder författarna en matris av biologiska nanoporer—pyttesmå, proteinbaserade hål i ett membran kopplade till elektroder. När en spänning appliceras dras DNA–peptid–DNA-strukturerna, en i taget, genom varje por av en molekylär motor. När peptiden passerar genom den smalaste delen blockerar den delvis jonflödet och ändrar den elektriska strömmen. Eftersom plattformen använder 256 porer parallellt och kan samla in över 100 000 sådana händelser från ett enda bibliotek inom två timmar, genererar den en massiv ström av enkelmolekylsignaler som fångar hur varje specifik peptid interagerar med poren. 
Från brusiga signaler till distinkta fingeravtryck
Vid första anblicken ser dessa strömspår brusiga och varierande ut; samma peptid kan gå in i poren i olika orienteringar och anta olika former. Traditionella sammanfattande mått som medelström och händelseduration överlappar ofta mellan liknande peptider. Den viktiga framgången i detta arbete är en tvåstegs artificiell intelligens-pipeline. Först tränas ett djupt konvolutionellt neuralt nätverk på stora mängder spår för att klassificera vilken peptid som gav upphov till vilket mönster. Sedan skapar teamet "täthetsmatriser" som summerar hur signalen tenderar att variera under varje händelse, i praktiken genom att omvandla moln av brusiga spår till stabila 2D-fingeravtryck. Endast läsningar vars detaljerade tidsmönster matchar dessa fingeravtryck behålls. Denna CNN-plus-fingeravtrycksstrategi höjer noggrannheten till runt 99% för testpeptider och kan pålitligt skilja åt fragment som skiljer sig med en enda aminosyra, vissa isomerer och många vanliga kemiska modifieringar som proteiner får i celler.
Kontrollera antikroppar och identifiera hela proteiner
Eftersom antikroppar känner igen korta sekvenser i proteiner använder författarna sin plattform för att kartlägga vilka fragment olika kommersiella antikroppar verkligen binder. Genom att blanda överlappande peptidbitar från en hormonprekursor, berika de de som binds av varje antikropp och sedan läsa dem med nanoporfssystemet kan de precisera föredragna bindningsregioner och visa när leverantörsrekommenderade antikroppspar faktiskt känner igen samma site och är dåligt matchade för sandwich-assays. I ett annat test undersöker de en välkänd taggsekvens och fyra nästan identiska varianter, och visar att det relativa antalet nanoporf-läsningar för varje peptid nära följer antikroppsbindningsstyrkan, i linje med mer arbetsintensiva ytbundna mätningar. Slutligen demonstrerar de proteinidentifiering: de tränar systemet på peptidfingeravtryck från tre humana proteiner, klyver sedan blint hela proteiner och visar att det kombinerade mönstret av klassificerade peptider räcker för att korrekt avgöra vilket protein som är vilket, även vid vissa tvetydiga eller saknade fragment. 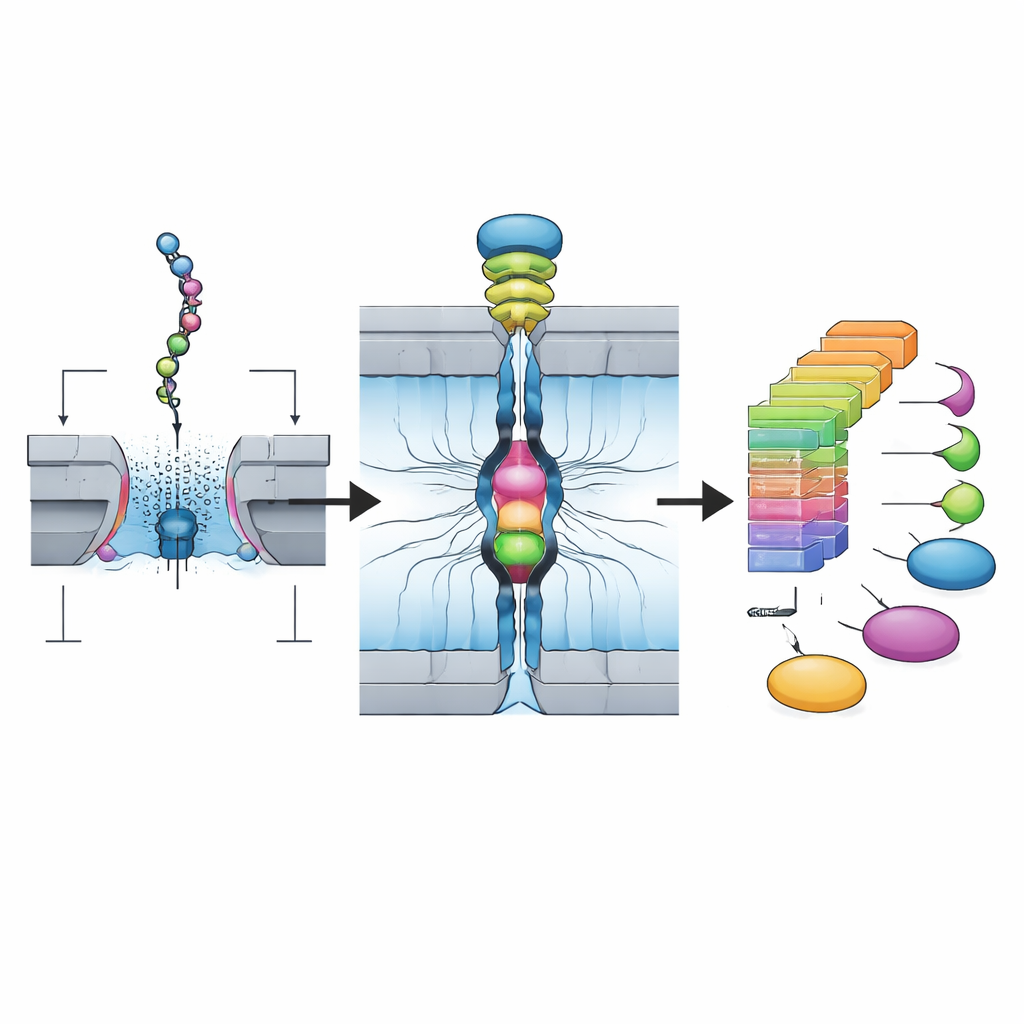
Varför detta är viktigt för framtida tester
Enkelt uttryckt visar studien att en DNA-liknande nanoporfsekvenserare, ihopkopplad med smart kemi och AI, kan fungera som ett högparallellt "stetoskop" för proteinfragment. Istället för att behöva läsa varje aminosyra i ordning förlitar sig systemet på rika, statistiska fingeravtryck från tusentals enkelmolekylhändelser för att urskilja subtila skillnader i laddning, storlek och modifiering. Detta möjliggör snabba, lågbudgetkontroller av antikroppskvalitet och banar väg för att känna igen hela proteiner utifrån deras peptidmönster. Även om det fortfarande finns begränsningar—såsom svårigheter med vissa peptidtyper och behovet av bra träningsdata—lägger arbetet fram en helhetspipeline som kan hjälpa till att föra rutinmässig, höggenomströmmande proteinanalyser närmare vanliga forskningslaboratorier och så småningom klinisk diagnostik.
Citering: Wang, J., Chen, J., Pan, H. et al. Nanopore-based massively parallel sensing for peptide profiling and protein identification. Nat Commun 17, 3058 (2026). https://doi.org/10.1038/s41467-026-69628-1
Nyckelord: nanoporfdetektion, proteomik, peptidfingeravtryck, antikroppsvalidering, proteinidentifiering