Clear Sky Science · sv
En 7T fMRI-datamängd med syntetiska bilder för out-of-distribution‑modellering av syn
Varför detta är viktigt för att förstå syn och AI
Våra ögon tar in en vidsträckt variation av bilder varje dag, från skogar och ansikten till trafikskyltar och skärmbrus. Ändå bygger de flesta studier av hjärnan och artificiell intelligens på en smal del av denna visuella värld: fotografier av naturliga scener. Denna artikel introducerar en ny typ av hjärndatamängd som medvetet bryter sig ur den bekvämlighetszonen, och använder noggrant utformade syntetiska bilder för att pröva både våra teorier om mänsklig syn och de AI-modeller som inspirerats av den.
Att bygga ett nytt visuellt testbänk
Författarna utökar den inflytelserika Natural Scenes Dataset (NSD), som spelade in ultrahögupplöst hjärnaktivitet med 7-tesla MRI medan försökspersoner tittade på tiotusentals fotografier. Den ursprungliga datamängden har redan legat till grund för några av de mest precisa modellerna av hur visuell cortex svarar på bilder. Men eftersom alla dessa bilder är relativt vanliga foton är det svårt att veta om en modell som fungerar bra på NSD verkligen fångar generella principer för syn eller om den helt enkelt specialiserats på just den typen av bildmaterial. För att hantera detta skannade teamet om samma åtta frivilliga, denna gång medan de visades 284 ”syntetiska” bilder som med flit går utanför det vanliga fotovärldens gränser.
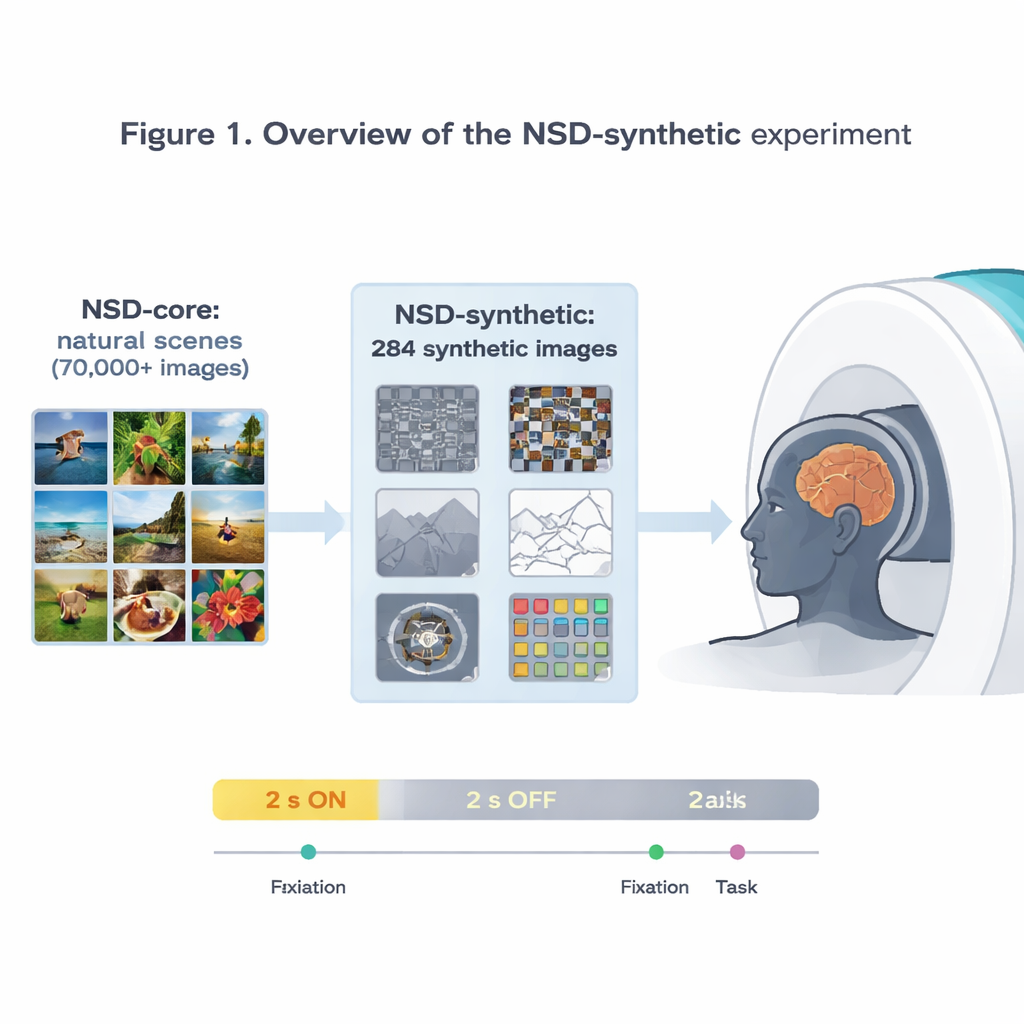
Udda bilder, tillförlitliga hjärnsvar
De syntetiska bilderna spänner över åtta familjer: olika typer av visuellt brus, enkla naturliga scener och deras förändrade versioner (som upp-och-ner eller linjeteckningar), scener med reducerad kontrast eller scramblead fas, enstaka ord placerade på olika positioner, spiralformade gitter som testar känslighet för fina mönster, och starkt färgade brusfläckar. Medan personerna antingen fokuserade på en liten flimrande punkt eller utförde en enkel bildjämförelse uppgift mättes hjärnaktiviteten var 1,6 sekund. De visar att dessa märkliga stimuli ändå ger upphov till starka, pålitliga signaler, särskilt i tidiga visuella områden som svarar på grundläggande egenskaper som kanter, kontrast och färg. Aktivitetens mönster över cortex matchar välkända preferenser hos specialiserade regioner, såsom ett ordselektivt område som reagerar starkast på centralt placerade ord och ett scenselektivt område som reagerar mest på bilder av miljöer.
Bevisa att datan verkligen är ”out of distribution”
För att denna nya datamängd ska kunna utmana modeller måste dess hjärnsvar vara genuint annorlunda än de som väcks av naturliga fotografier. Författarna komprimerar aktivitetsmönster från både den ursprungliga NSD och den syntetiska sessionen till en tvådimensionell karta som speglar hur lika svaren är över bilder. I det rummet klustrar svaren på syntetiska bilder separat från svaren på naturliga foton, även när man tar hänsyn till skillnader mellan skanningssessioner. Dessutom grupperar syntetiska bilder naturligt efter deras visuella typ—brus med brus, gitter med gitter och så vidare—vilket visar att hjärnan organiserar dessa stimuli utifrån deras underliggande struktur, inte bara deras yttre utseende.
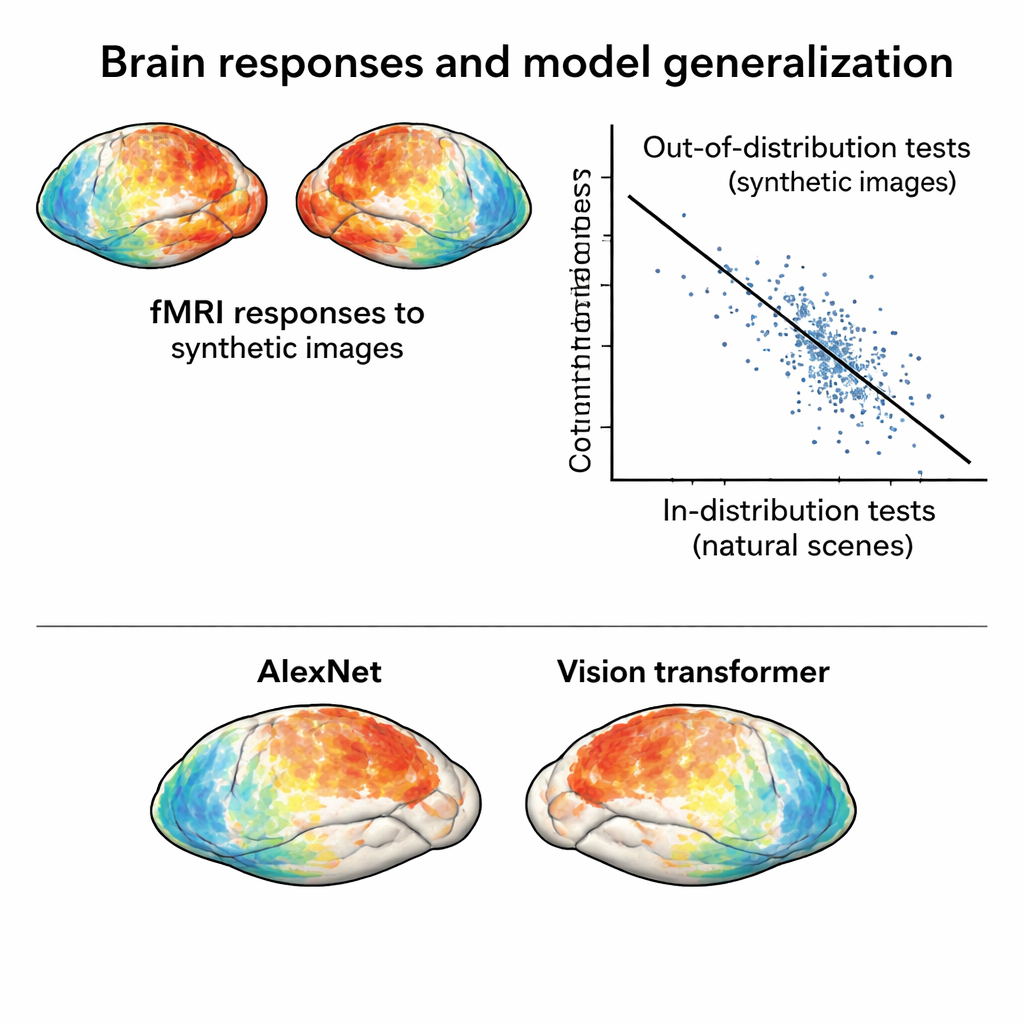
Sätta hjärn- och AI-modeller på ett tuffare prov
Med denna nya ”out-of-distribution” datamängd i handen tränar teamet standardiserade encoding-modeller: matematiska verktyg som förutspår hjärnsvar från bildfunktioner extraherade av djupa neurala nätverk. Modeller tränade enbart på de naturliga fotona presterar väl när de testas på liknande foton, men deras noggrannhet sjunker markant när de ska förutsäga svar på de syntetiska bilderna. Denna försämring beror inte på brusig data—de syntetiska svaren är faktiskt mycket rena—utan på verkliga modellfel. Särskilt visar jämförelser av olika nätverksarkitekturer under dessa hårdare förhållanden skillnader som knappt syns i in-distribution-tester. Till exempel överträffar en modern vision-transformer och ett självövervakat nätverk båda klassiska konvolutionella nätverk när de ställs inför syntetiska bilder, vilket antyder att hur en modell tränas starkt formar dess robusthet.
Hur långt från bekanta bilder kan modeller gå?
Författarna går längre och behandlar ”avståndet” från träningsdatan som ett kontinuum, inte en ja/nej‑etikett. De mäter hur långt varje bilds hjärnsvar ligger från molnet av svar på naturliga scener. Ju längre bort en syntetisk bild är i detta rum, desto sämre presterar modellerna ofta och desto mindre exakt kan de användas för att identifiera vilken bild en person såg baserat enbart på hjärnaktivitet. De visar också att även inom världen av vanliga fotografier kan skickligt valda testset bete sig som ”mildt out of distribution”: modeller presterar bäst på bilder hämtade från samma kluster som deras träningsset, sämre på avlägsna naturliga scener och sämst på de syntetiska stimuli. Denna graderade bild gör den nya datamängden till ett verktyg för att pröva exakt vilka typer av visuell struktur nuvarande modeller missar.
Vad detta betyder för framtida hjärn- och AI-forskning
För icke-specialister är huvudbudskapet att stark prestation på bekanta bilder inte garanterar att en hjärninspirerad AI-modell verkligen fångat hur vi ser. Genom att släppa NSD-synthetic tillsammans med den ursprungliga NSD erbjuder författarna en publik ”krocktestbana” för synmodeller: ett sätt att se var de brister när bilderna blir mer abstrakta, mer färgstarka eller mindre naturliga. Eftersom datamängden är öppet tillgänglig och tätt integrerad med en befintlig, vida använd resurs är det troligt att den blir en standardbenchmark för att testa och förbättra teorier om mänsklig syn och de artificiella nätverk som försöker efterlikna den.
Citering: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Nyckelord: visuell cortex, fMRI-datamängd, syntetiska bilder, out-of-distribution, djupa neurala nätverk