Clear Sky Science · sv
Upptäckande av Cas9 PAM-mångfald genom metagenomisk gruvdrift och maskininlärning
Varför detta är viktigt för framtida genredigering
CRISPR har blivit en symbol för modern genredigering, men en tyst regel begränsar fortfarande vad tekniken kan göra: varje klipp i DNA måste sitta intill en kort ”tillståndssedel”. Dessa korta mönster, kallade PAMs, avgör var det populära enzymet Cas9 kan och inte kan verka. I denna studie visar forskarna hur man genom att sålla i enorma mängder mikrobiellt DNA, i kombination med avancerad maskininlärning, kan avslöja en enorm dold variation av dessa tillståndssedlar. Den nya kartan kan öppna upp många fler platser i det mänskliga genomet för precisa och säkrare terapier.
Dolda regler som styr CRISPR-klipp
Cas9 och närliggande enzymer är en del av ett naturligt immunsystem som finns i bakterier och arkéer. För att undvika att klippa sitt eget DNA letar dessa mikrober efter en PAM—en mycket kort sekvens—nära målet. Endast när den PAM:n är närvarande kommer Cas9 att rulla upp DNA:t och låta dess guide-RNA kontrollera om det finns en matchning, vilket utlöser ett klipp om allt stämmer. Problemet för medicinen är att vanliga laborationsverktyg, såsom standard-Cas9 från Streptococcus pyogenes, bara känner igen snäva PAM-mönster. Om en sjukdomsframkallande mutation saknar rätt närliggande sekvens kan dagens verktyg helt enkelt inte nå den utan att offra precision.
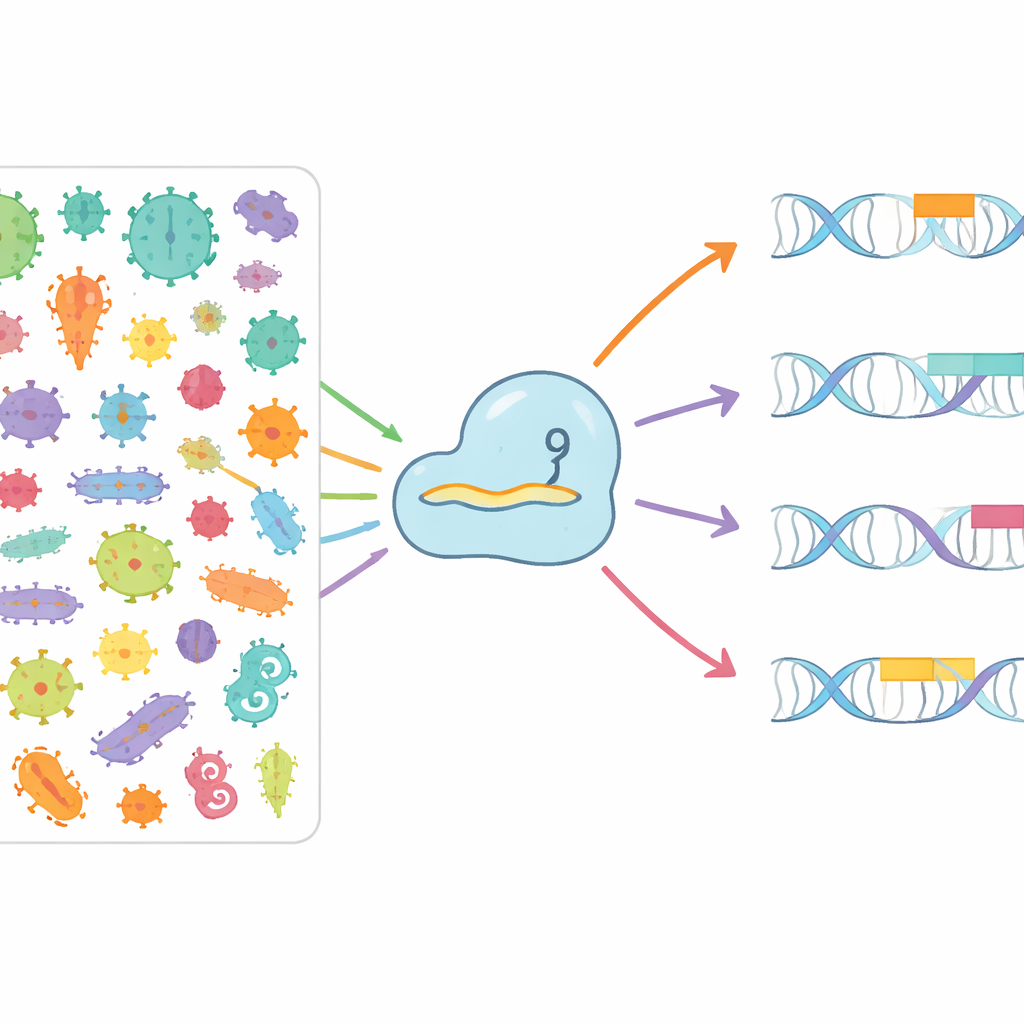
Gruvdrift i mikrobiella världen efter nya alternativ
Författarna gav sig i kast med att systematiskt kartlägga hur olika Cas9-proteiner känner igen olika PAMs i naturen. De sökte igenom mer än 3,8 miljoner bakteriella och arkeala genom och över 7,4 miljoner virus- och plasmidsekvenser som infekterar eller rör sig mellan mikrober. Genom att identifiera CRISPR-arrayer, koppla dem till närliggande Cas9-gener och sedan matcha de lagrade ”minnes”‑spacers mot angripande virus och plasmider kunde de se vilka korta DNA-mönster som tenderade att flanka verkliga mål. Av detta byggde de CRISPR-PAMdb, en offentlig katalog som innehåller 8003 Cas9-grupper, var och en kopplad till en konsensus PAM-profil, och organiserade dem i ett evolutionärt träd som framhäver hur nära besläktade Cas9‑enzymer tenderar att dela liknande PAM-preferenser samtidigt som de visar en slående övergripande mångfald.
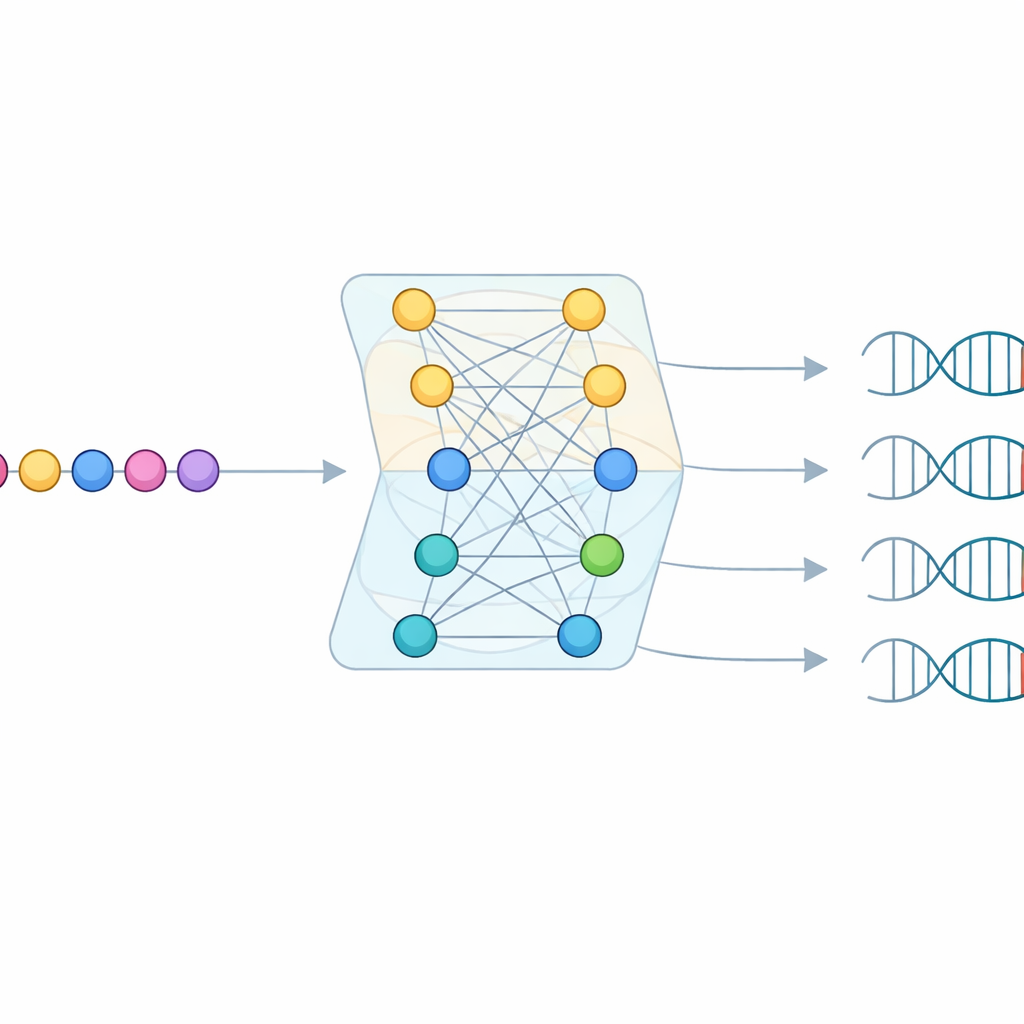
När data tar slut, låt modellen lära sig
Även med denna enorma undersökning saknade de flesta identifierade Cas9-proteiner tillräckligt många matchande virala mål för att läsa av en PAM direkt. För att fylla i luckorna byggde teamet en maskininlärningsmodell kallad CICERO. CICERO använder en kraftfull protein‑”språkmodell” som har lärt sig generella mönster i aminosyrasekvenser och finjusterar den för att förutse, för varje given Cas9-protein, hur sannolikt varje DNA‑bokstav är att förekomma på varje av tio positioner i PAM. Modellen tränades på PAM‑profiler från CRISPR‑PAMdb och testades sedan både med korsvalidering och på 79 Cas9‑enzymer vars PAMs mätts experimentellt, vilket visade en stark överensstämmelse mellan förutsägelse och verklighet.
Att veta hur säker man kan vara
En nyckelfunktion i CICERO är att den inte bara gissar en PAM—den uppskattar också hur pålitlig varje gissning är. Efter att ha lärt sig att förutsäga PAM‑mönster tränade forskarna ett andra, lättviktigt nätverk som tar samma Cas9‑sekvens och lär sig att förutsäga hur exakt PAM‑förutsägelsen kommer att vara. Högre konfidenspoäng korrelerade starkt med högre verklig noggrannhet. Med detta konfidensfilter utökade teamet PAM‑annoteringar till mer än 50 000 ytterligare Cas9‑proteiner, med över 17 000 förutsägelser klassificerade som högkonfidens. Detta vidgar avsevärt menyn av Cas9‑varianter med rimligt välförstådda riktlinjer för målinriktning.
Vad detta betyder för behandling av genetiska sjukdomar
För att visa varför dessa nya resurser spelar roll undersökte författarna tiotusentals sjukdomsrelaterade enkelbokstavs‑mutationer i ClinVar‑databasen som i princip skulle kunna korrigeras med basredigerare—verktyg som ändrar en DNA‑bokstav utan att klippa båda strängarna. De fann att standard‑Cas9‑enzymet bara kan nå ungefär hälften av sådana platser på grund av sina strikta PAM‑krav. När de tillät Cas9‑släktingar från CRISPR‑PAMdb och högkonfidenta CICERO‑förutsägelser som känner igen ett bredare men fortfarande specifikt set av närliggande sekvenser, blev nästan alla dessa mutationer teoretiskt tillgängliga utan att man behövde luckra upp selektiviteten så att precision skulle gå förlorad.
Ett större verktygslåda för precis DNA‑kirurgi
Enkelt uttryckt bygger detta arbete två saker: en gigantisk, offentlig karta som länkar tusentals naturliga Cas9‑proteiner till de korta DNA‑mönster de föredrar, och en AI‑guide som kan förutsäga dessa preferenser för många fler enzymer enbart från deras sekvenser. Tillsammans förvandlar de den mikrobiella världen till ett rikt reservdelsbibliotek för framtida genredigerare. När forskare förfinar och testar dessa Cas9‑varianter i labbet kan kliniker få säkrare, mer mångsidiga verktyg som kan nå sjukdomsframkallande mutationer som tidigare var utom räckhåll, vilket för genomförbar, precis genkirurgi ett steg närmare verkligheten.
Citering: Fang, T., Bogensperger, L., Feer, L. et al. Uncovering Cas9 PAM diversity through metagenomic mining and machine learning. Nat Commun 17, 2510 (2026). https://doi.org/10.1038/s41467-026-69098-5
Nyckelord: CRISPR-Cas9, PAM-mångfald, metagenomik, maskininlärning, genomredigering