Clear Sky Science · sv
DNA-diamant formulerar en dekomponerbar kompositbokstavskonstellationsmodell för DNA-datalagring
Varför framtida data kan leva i DNA
Våra telefoner, företag och vetenskapliga instrument genererar data mycket snabbare än vad hårddiskar och magnetband kan expandera. DNA—samma molekyl som bär genetisk information i levande organismer—kan också användas för att lagra digitala filer i en oerhört kompakt och långlivad form. Denna artikel introducerar ett nytt sätt att packa ännu mer information i syntetiska DNA-strängar samtidigt som det hålls praktiskt och tillförlitligt att läsa tillbaka, vilket potentiellt kan göra DNA-lagring billigare och mer skalbar.
Från fyra DNA-bokstäver till rikare blandningar
Traditionell DNA-lagring använder de fyra naturliga DNA-baserna—A, T, G och C—för att representera digitala bitar, ungefär som nollor och ettor på en disk. I det systemet kan varje position i en DNA-sträng bära högst två bitar information, eftersom den är begränsad till ett av fyra val. Författarna bygger vidare på en framväxande idé: i stället för att placera en ensam bas vid varje position skapar de noggrant kontrollerade blandningar av baser, kallade kompositbokstäver. Till exempel kan en position bestå av en 50:50-blandning av A och T, eller en 25:25:25:25-blandning av alla fyra baser. När många kopior av varje sträng syntetiseras avslöjar sekvensering av dessa blandningar basproportionerna och i sin tur en digital symbol som kan representera mer än två bitar.
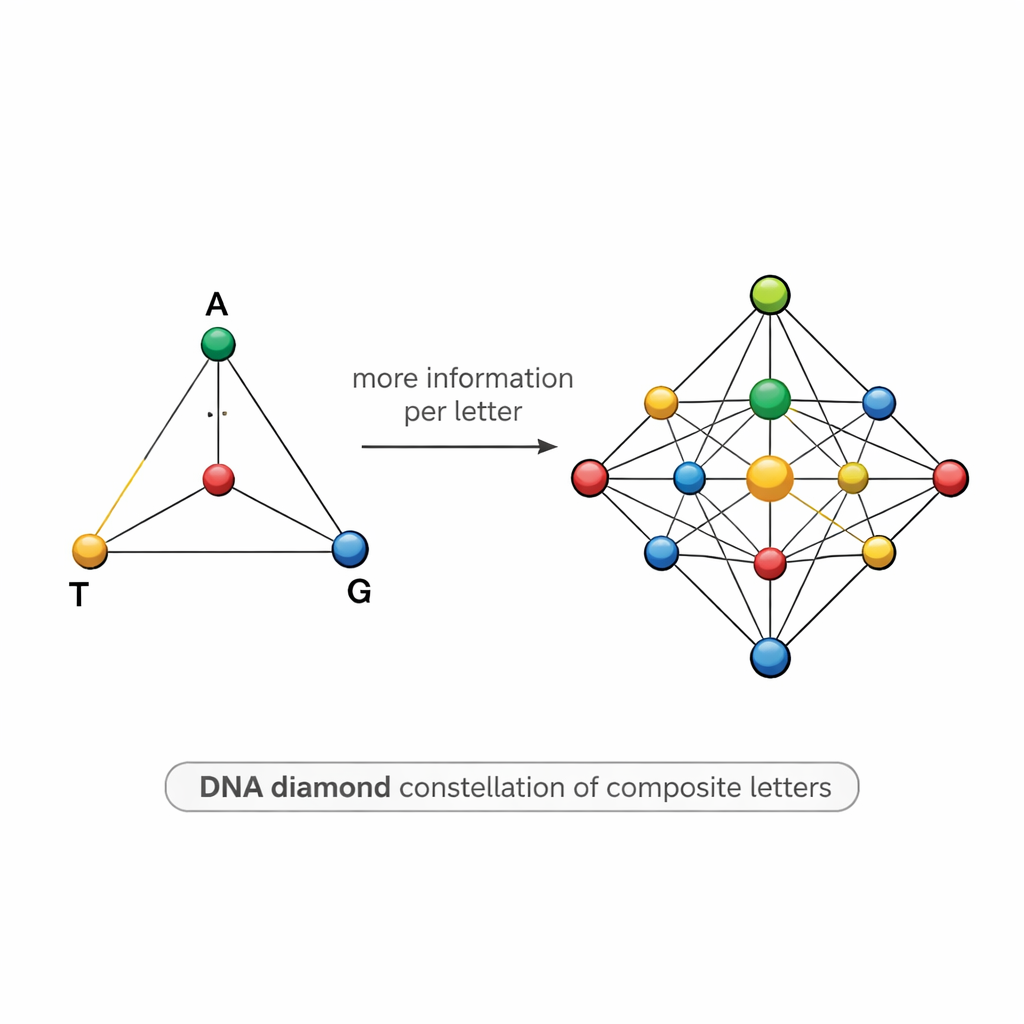
En diamantformad karta över DNA-symboler
Att utforma sådana blandningar är svårt. Om två symboler är för lika—till exempel om en är 50 % A och 50 % T och en annan är 55 % A och 45 % T—kan sekvenseringsbrus sudda ut dem, orsaka fel och tvinga forskare att sekvensera långt fler kopior än de vill. För att tackla detta föreslår teamet en strukturerad "DNA-diamant"-modell: en uppsättning om 15 kompositbokstäver ordnade som punkter på en tetraeder vars hörn är A, T, G och C. Uppsättningen inkluderar rena baser i hörnen, lika blandningar av två baser längs kanterna, blandningar av tre baser på varje yta, och en perfekt jämn blandning av alla fyra baser i mitten. Denna noggrant utvalda konstellation höjer den teoretiska informationen per position till cirka 3,9 bitar, samtidigt som symbolerna hålls tillräckligt distinkta för att kunna särskiljas i praktiken.
Smartare avkodning med entropi och indexering
Att läsa tillbaka data från DNA innebär att härleda vilken kompositbokstav som avsågs vid varje position utifrån brusiga mätningar av basfrekvenser. Författarna lånar en strategi från telekommunikation som kallas setpartitionering. Först ser de hur "blandad" en position verkar vara, med hjälp av en mängd som kallas entropi som är låg för rena baser och högre för komplexa blandningar. Detta tilldelar snabbt varje position till en av fyra grupper: rena baser, tvåbasblandningar, trebasblandningar eller fyrabasblandningen. Därefter, inom den valda gruppen, väljer en mer precis sannolikhetsberäkning den mest troliga bokstaven. Detta tvåstegsangrepp minskar förväxling mellan symboler och kortar beräkningstiden jämfört med tidigare metoder. För att ytterligare förhindra att strängar förväxlas bär varje DNA-bit felskyddade indexsekvenser i båda ändar, och läsningar av fel längd—ofta orsakade av insättnings- eller borttagningsfel—filtreras bort innan avkodning.
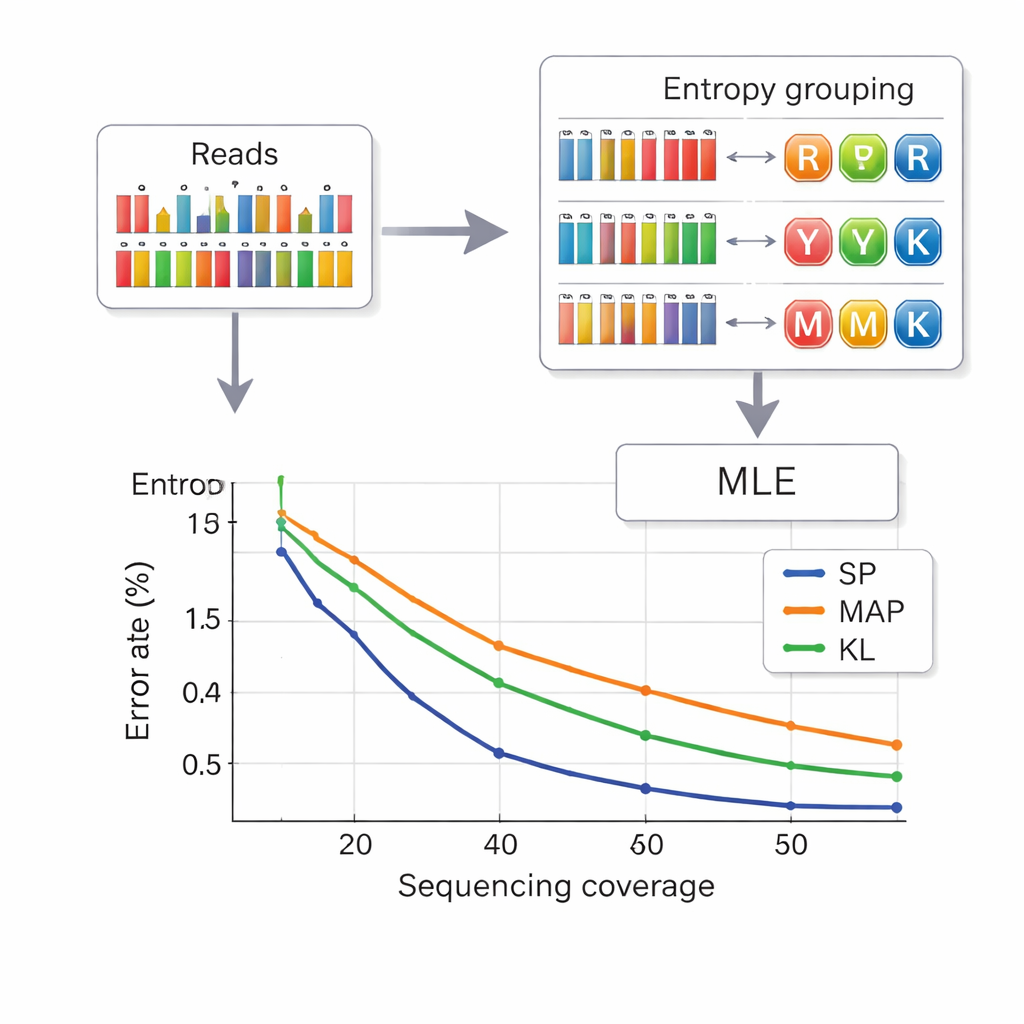
Packa mer data med färre läsningar
Forskarna testade sitt system i både små och stora DNA-pooler, med kommersiella syntesplattformar. Med ett åttabokstavsalphabet nådde de en nyttolasttäthet på 2,5 bitar per DNA-position och kunde återställa filer perfekt med i genomsnitt 14 sekvenseringsläsningar per sträng—bättre densitet än tidigare sexbokstavsscheman samtidigt som färre läsningar behövdes. Med hela 15-bokstavs DNA-diamantalfabetet uppnådde de 3,125 bitar per position för huvuddata och återställde fortfarande allt utan fel vid 33-faldig täckning. Simuleringar och experiment visade också att deras entropibaserade metod presterar nästan lika bra som den mest exakta, men långsammare, avkodningsmetoden, och klart bättre än äldre tekniker, särskilt vid lägre sekvenseringsdjup.
Vad detta betyder för framtidens minne
För en lekman är huvudbudskapet att författarna har hittat ett sätt att lära DNA "nya trick" utan att uppfinna ny kemi: genom att skickligt blanda de befintliga fyra baserna och avkoda dem mer intelligent kan de lagra fler bitar data per molekyl samtidigt som kostnaderna hålls under kontroll. Deras diamantformade alfabet, kombinerat med robust indexering och felskydd, visar att högkapacitets DNA-datalagring är möjlig med relativt måttliga sekvenseringsinsatser. När DNA-syntes och sekvensering fortsätter bli billigare kan sådana designer hjälpa till att förvandla DNA från ett laboratoriecuriosum till ett realistiskt medium för att arkivera världens digitala minnen.
Citering: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Nyckelord: DNA-datalagring, kompositbokstäver, informationsdensitet, felskydd, digital arkivering