Clear Sky Science · sv
Databas för lipidnanopartiklar för struktur-funktionsmodellering och datadriven design för leverans av nukleinsyror
Varför små fettbubblor spelar roll för framtidens mediciner
Lipidnanopartiklar är mikroskopiska fettbaserade bubblor som tryggt transporterar genetiska instruktioner—som mRNA-vacciner—in i våra celler. De bidrog till genombrottet med COVID-19-vacciner, men forskare förstår fortfarande inte fullt ut hur deras detaljerade kemiska sammansättning styr hur väl de fungerar. Den här artikeln beskriver en ny online-resurs, Lipid Nanoparticle Database (LNPDB), skapad för att samla utspridda data på ett ställe så att forskare systematiskt kan designa bättre och säkrare genleveransläkemedel.
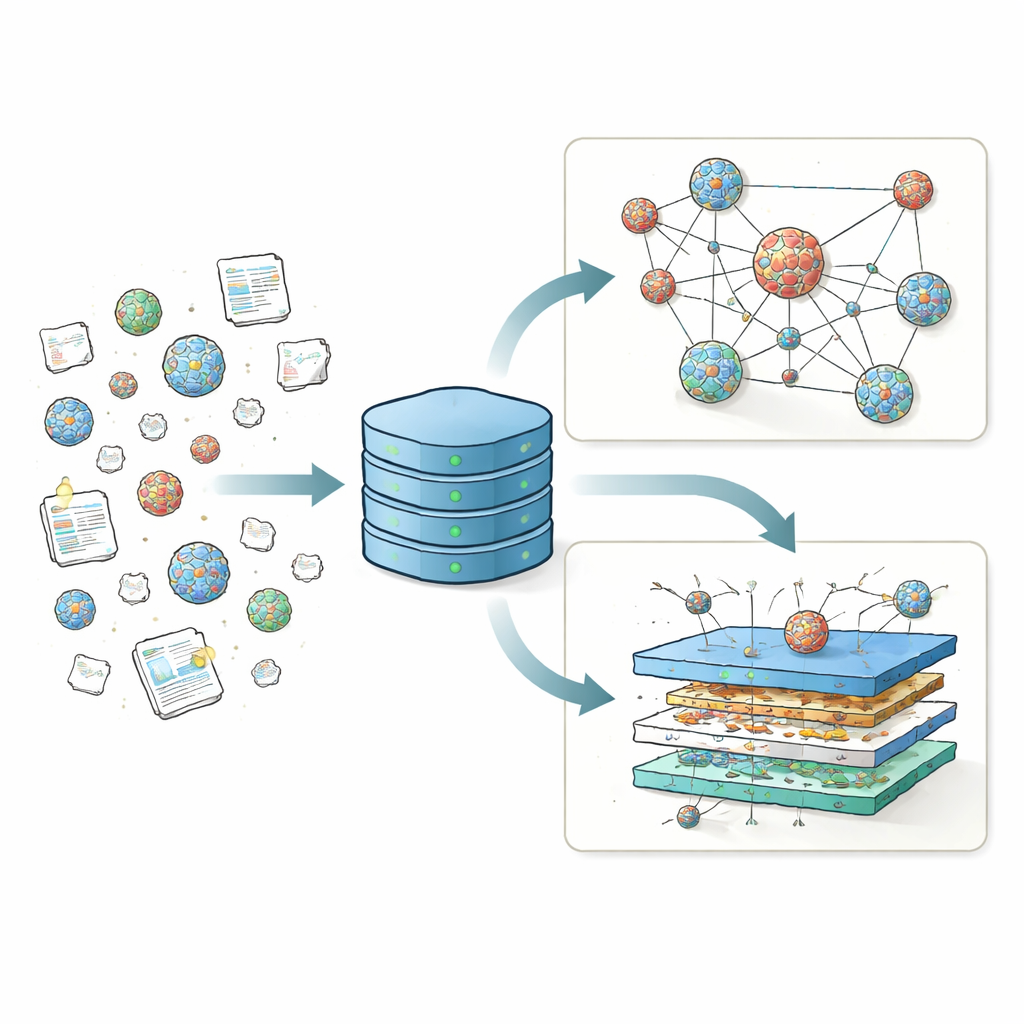
Att samla utspridda resultat på ett ställe
I åratal har olika laboratorier testat tusentals recept för lipidnanopartiklar (LNP), där de varierat den huvudsakliga laddade lipiden, hjälpande lipider, kolesterol och skyddande beläggningslipider för att se vilka kombinationer som levererar genetiskt material mest effektivt. Men dessa resultat rapporterades i många olika format över dussintals artiklar, vilket gjorde det svårt att jämföra studier eller urskilja övergripande trender. Till skillnad från proteinvetenskapen, som stöds av en central Protein Data Bank som möjliggjort verktyg som AlphaFold, saknade LNP-fältet ett enhetligt arkiv för struktur- och prestandadata. LNPDB fyller detta gap genom att samla detaljerad information för 19 528 LNP-formuleringar hämtade från 42 studier och en kommersiell leverantör, samt genom att standardisera hur varje partikels ingredienser, testförhållanden och utfall kodas.
Vad som finns i den nya databasen
Varje LNP-post i LNPDB beskrivs utifrån tre huvudaxlar: sammansättning, experiment och simulering. Fälten för sammansättning anger vilka lipider som användes, hur många kväveatomer den huvudsakliga laddade lipiden innehåller och de exakta blandningskvoterna mellan de fyra kärnkomponenterna: joniserbar lipid, hjälpande lipid, kolesterol och ett polyethylene glycol (PEG)-lipid. Experimentfälten fångar vilken typ av genetiskt last som levererades—oftast mRNA som kodar för ett rapportprotein—vart det skickades (till exempel celler i skål, lever, lunga eller muskel), hur partiklarna bereddes och hur framgång mättes. Slutligen erbjuder simuleringsfälten färdiga filer som beskriver det fysiska beteendet hos varje lipidmolekyl i tillräcklig detalj för att köra atomnivå-simuleringar av lipidmembran. Tillsammans förvandlar dessa standardiserade beskrivningar ett lapptäcke av enskilda tester till ett sammanhängande landskap som kan sökas, filtreras och utökas av forskarsamhället.
Att lära datorer att hitta bättre leveransrecept
Ett omedelbart användningsområde för LNPDB är att förbättra maskininlärningsmodeller som förutspår vilka formuleringar som levererar genetiskt material mest effektivt. Författarna tränade om sin befintliga djupinlärningsmodell, kallad LiON, med den utökade LNPDB-datasetet, vilket mer än fördubblade antalet exempel modellen tidigare sett. LiON lär sig mönster som kopplar de joniserbara lipidernas kemiska strukturer, blandningen av hjälpkomponenter och testkontexten till hur väl varje formulering presterade. Med de rikare data blev LiONs förutsägelser bättre överensstämmande med experimentella resultat för de flesta testuppsättningar och överträffade en konkurrerande modell kallad AGILE på flera oberoende dataset. Detta tyder på att en bred, diversifierad och kontinuerligt växande träningsmängd är avgörande för att bygga allmänt användbara designverktyg för framtida LNP-läkemedel.
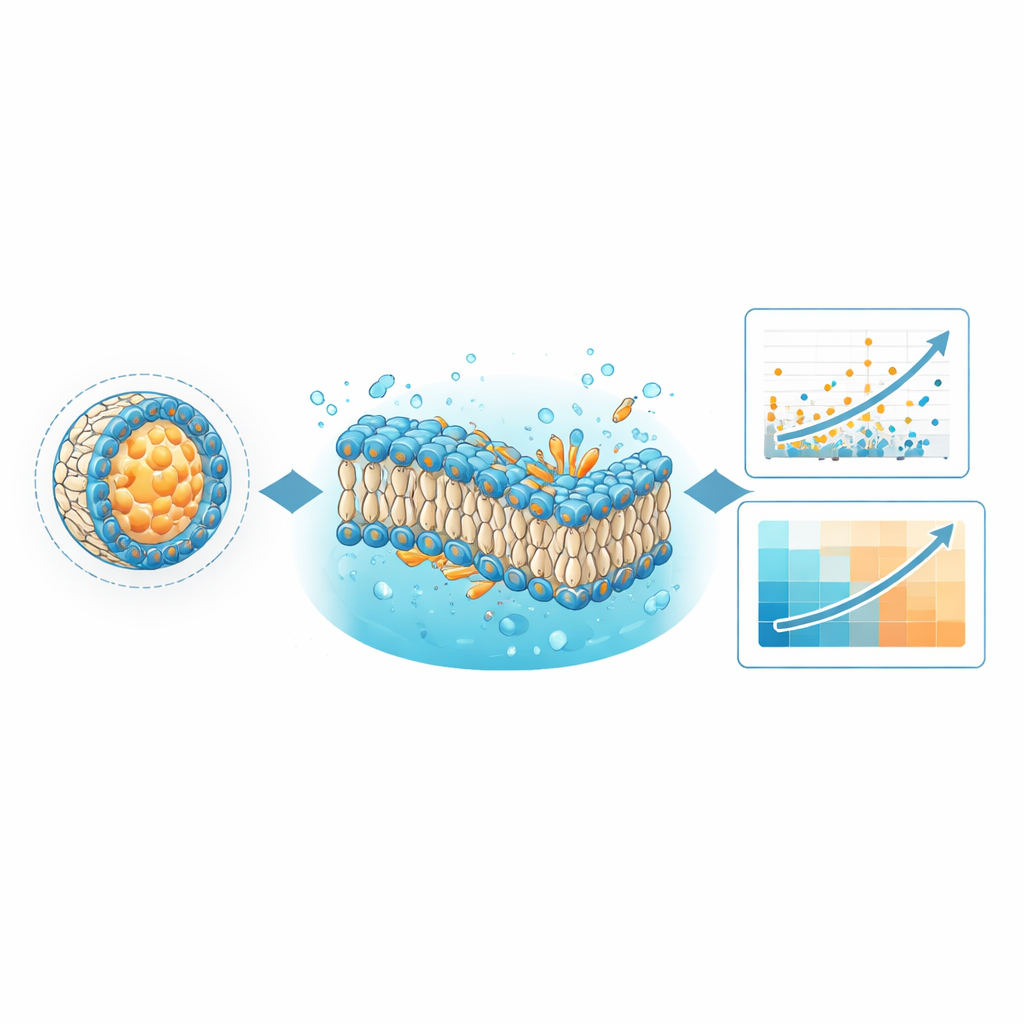
Att observera modellmembran för att avslöja dolda regler
Databasen är också utformad för en helt annan typ av beräkning: fysikbaserade molekylära dynamiksimuleringar. Med hjälp av de simuleringsfiler som medföljer LNPDB byggde teamet förenklade membraner som representerar utvalda LNP-formuleringar och observerade deras beteende över mikrosekunder av simulerad tid. De ställde två frågor: håller de modellerade lipidbilagrena ihop, och vilken övergripande form antar nyckellipiderna i membranet? Simulationerna visade att formuleringar vars membraner förblev stabila hade större sannolikhet att lyckas experimentellt. De kvantifierade också en egenskap kallad ”kritisk packningsparameter”, som speglar om en lipid är mer konformad som en kon eller omvänd kon i membranet. I flera testade bibliotek visade lipider vars form gynnade negativ krökning—tänkt att underlätta partiklars fusion med och störning av endosomala membran—starkare leverans, ibland med bättre korrelation till prestanda än djupinlärningsmodellen själv.
En ny grund för smartare nanomedicin
För en icke-specialist är kärnbudskapet att detta arbete bygger en delad, växande ”karta” över hur ingredienserna och strukturen hos små fettbubblor relaterar till deras förmåga att leverera genetiska terapier. Genom att samla tiotusentals tidigare experiment, möjliggöra kraftfulla prediktiva modeller och tillhandahålla verktyg för att simulera hur partiklar beter sig på molekylär nivå, lägger LNPDB grunden för mer rationell design istället för prövning-och-fel. Med tiden kan denna typ av datadrivet arbetssätt påskynda skapandet av mer effektiva vacciner, genterapier och andra nukleinsyra-baserade behandlingar, samtidigt som det hjälper forskare att förstå varför vissa nanopartikelrecept fungerar—och andra inte.
Citering: Collins, E., Ji, J., Kim, SG. et al. Lipid Nanoparticle Database towards structure-function modeling and data-driven design for nucleic acid delivery. Nat Commun 17, 2464 (2026). https://doi.org/10.1038/s41467-026-68818-1
Nyckelord: lipidnanopartiklar, mRNA-leverans, nanomedicin, maskininlärning, molekylär dynamik