Clear Sky Science · sv
Återkopplade kopplingar underlättar igenkänning av ockluderade objekt genom förklaring
Hur hjärnan ser det som inte finns där
I vardagen känner vi utan ansträngning igen föremål som delvis är dolda—en katt bakom ett draperi, en bil bakom ett träd. Denna artikel frågar hur hjärnor, och hjärnliknande artificiella nätverk, klarar detta. Författarna visar att kretsar med återkopplingsslingor kan använda information om det som blockerar för att mentalt "fylla i" vad som finns bakom, vilket avslöjar ett viktigt knep vårt visuella system kan förlita sig på när världen är rörig och ofullständig.
Varför dolda objekt är ett svårt problem
När ett objekt är ockluderat saknas eller förvrängs många av dess vanliga visuella kännetecken. Ett enkelt feedforward-visuellt system, där information flödar rakt från ögonen till igenkänningscentra, måste gissa det dolda objektet enbart utifrån de synliga fragmenten. Biologiska hjärnor är däremot fulla av rekurrenta kopplingar—slingor där högre områden talar tillbaka till tidigare. Dessa slingor har länge antagits hjälpa till med svåra uppgifter som att känna igen ockluderade objekt, men det har varit oklart exakt vilken fördel de ger eller hur de förändrar de interna representationerna av vad vi ser.
Att utsätta hjärnliknande nätverk för testet
Författarna byggde ett stort antal djupa konvolutionsnätverk som efterliknar stadier av visuell bearbetning. Några var rent feedforward, medan andra hade rekurrenta slingor eller ytterligare top-down-återkoppling. De tränade dessa modeller på egna bildset där ett modeföremål delvis täckte ett annat. Nätverken skulle identifiera både det främre (ockluderande) och det bakre (ockluderade) objektet under olika uppgiftsupplägg. Prestandan berodde mer på dess "beräkningsdjup"—hur många sekventiella bearbetningssteg en insignal passerade igenom—än på om nätverket var rekurrent eller feedforward. Djupa feedforward-modeller kunde matcha eller överträffa rekurrenta modeller i den enklare igenkänninguppgiften, vilket visar att rekurrens inte är magiskt överlägset i sig.
Ett särskilt knep: att förklara bort ockluderaren
Även om djupet var viktigast för rå noggrannhet, visade rekurrenta nätverk en särskiljande fördel i hur de använde kontext. När dessa nätverk först ombads identifiera det främre objektet och först därefter det dolda, förbättrades deras prestation på det dolda objektet jämfört med när de klassificerade det ensam. Detta mönster framträdde inte i vanliga feedforward-nätverk som gav båda etiketterna samtidigt. Författarna tolkar detta som "förklarande bort": när systemet väl har känt igen ockluderaren kan det betrakta de udda, saknade dragen i bilden som orsakade av just den ockluderaren, snarare än som bevis för något märkligt nytt objekt. I mer realistiska 3D-scener och i en primatinspirerad modell (CORnet) gav samma ordning—främre objekt före dolt objekt—också en förbättring i igenkänning.
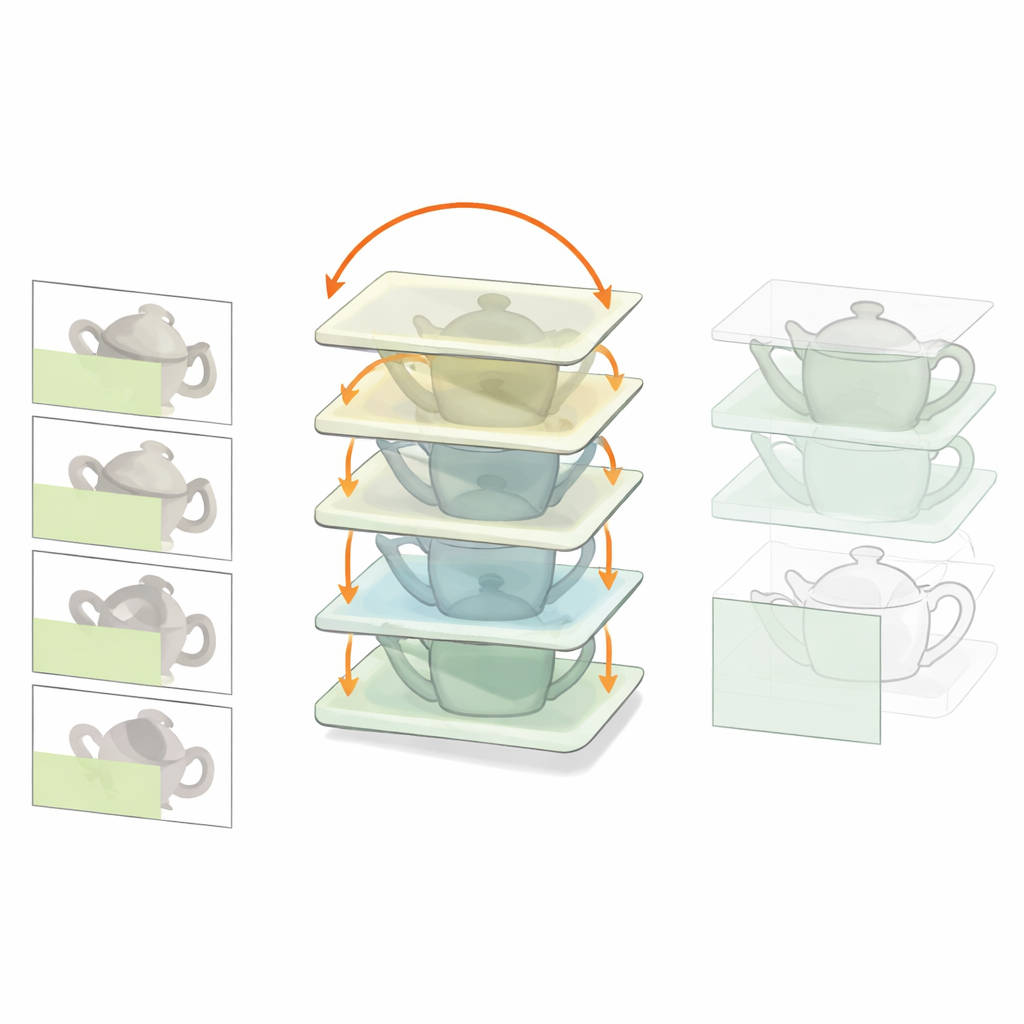
Samma effekt hos människor
För att undersöka om människor använder en liknande strategi genomförde forskarna ett onlineexperiment. Deltagarna såg kort ett enskilt objekt, sedan en scen där ett objekt ockluderade ett annat, och slutligen skulle de välja vilket av två alternativ som varit det dolda objektet. I vissa försök var det inledande enskilda objektet samma som den senare ockluderaren; i andra var det orelaterat. När människor precis hade sett den faktiska ockluderaren identifierade de det dolda objektet mer korrekt och svarade snabbare, över en rad ocklusionsnivåer. Det tyder på att våra hjärnor, likt de rekurrenta nätverken, gynnas av att först bearbeta det blockerande föremålet och sedan använda den kunskapen för att tolka det partiella beviset för vad som ligger bakom.
Återskapa dolda bilder inifrån
För att gräva djupare i mekanismen designade författarna en mer biologiskt inspirerad modell, Recon-Net, löst baserad på interaktioner mellan visuell cortex och prefrontala cortex. Recon-Net tar emot en bild som innehåller ett ockluderat objekt plus en separat vy av ockluderaren och omvandlar iterativt en intern representation tills den matchar hur en oockluderad version av det dolda objektet borde se ut. Slående nog kan klassificerare tränade endast på rena, oockluderade bilder känna igen Recon-Nets utdata nästan lika bra som om de hade tränats direkt på ockluderade exempel. Det betyder att den rekurrenta bearbetningen effektivt "återskapar" en ren intern bild av det dolda objektet, även om pixlarna saknas.
Vad detta betyder för hjärnor och maskiner
Sammantaget visar studien att återkopplingsslingor inte bara handlar om rå prestanda, utan om ett kvalitativt annorlunda sätt att använda kontext. Rekurrenta kopplingar understöder naturligt förklarande bort: de låter det visuella systemet ta hänsyn till hur en ockluderare förvränger vad vi ser och återställa en stabil intern representation av det dolda objektet. Samtidigt finner författarna att träning på kraftigt ockluderade bilder kan lämna svaren på klara bilder i stort sett oförändrade, vilket potentiellt underlättar inlärning i verkliga hjärnor genom att undvika ständig omkoppling. Dessa insikter pekar mot en gemensam princip för både neurovetenskap och artificiell intelligens: när världen döljer information, tittar smarta system inte bara hårdare—de sluter slutsatser om varför den saknas.
Citering: Kang, B., Midler, B., Chen, F. et al. Recurrent connections facilitate occluded object recognition by explaining-away. Nat Commun 17, 2225 (2026). https://doi.org/10.1038/s41467-026-68806-5
Nyckelord: igenkänning av ockluderade objekt, rekurrenta neurala nätverk, visuell perception, förklarande bort, beräkningsneuroscience