Clear Sky Science · sv
Utvärdering av single-cell ATAC-seq‑atlastekniker med sekvens-till-funktion‑modellering
Att läsa cellens instruktionshandbok
Varje cell i din kropp läser samma DNA, ändå beter sig nervceller, muskelceller och immunceller mycket olika. Denna artikel tar sig an en central gåta bakom den mångfalden: hur korta DNA‑sekvenser kallade enhancers fungerar som strömbrytare som slår på och av gener i specifika celltyper. Författarna visar att ny, billigare laboratorieteknik kan generera de massiva datamängder som behövs för att träna moderna djuplärningsmodeller som läser DNA‑sekvenser och förutspår vilka enhancers som är aktiva i vilka celler, vilket för oss närmare en verklig avkodning av genomets regulatoriska ”grammatik”.
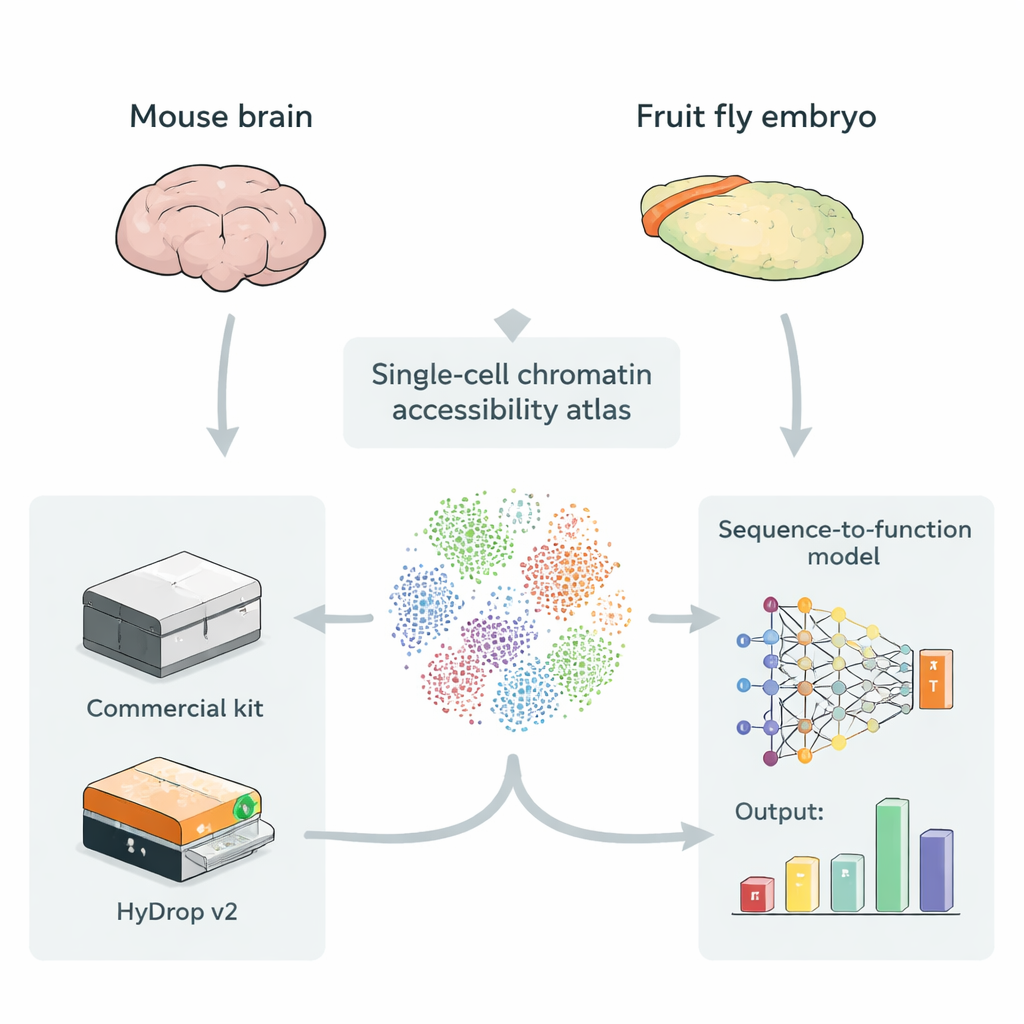
Att göra kartor över öppet DNA i enskilda celler
Enhancers ligger ofta i DNA‑regioner som är mer öppna och åtkomliga, vilket gör det lättare för reglerande proteiner att binda. En teknik som kallas single‑cell ATAC‑seq mäter vilka delar av genomet som är öppna i tusentals till hundratusentals enskilda celler samtidigt och skapar en ”atlas” över åtkomligt DNA över många celltyper. Dessa atlaser är idealiskt bränsle för djuplärningsmodeller som tar rå DNA‑sekvens som indata och lär sig förutsäga hur starkt varje liten region fungerar som enhancer i varje celltyp. Hittills har dock de flesta sådana atlaser förlitat sig på dyra kommersiella instrument, vilket väckt frågan om lågkostnads, öppen källkod‑metoder kan ge träningsdata av motsvarande värde för dessa modeller.
En öppen källkods‑alternativ till kommersiella plattformar
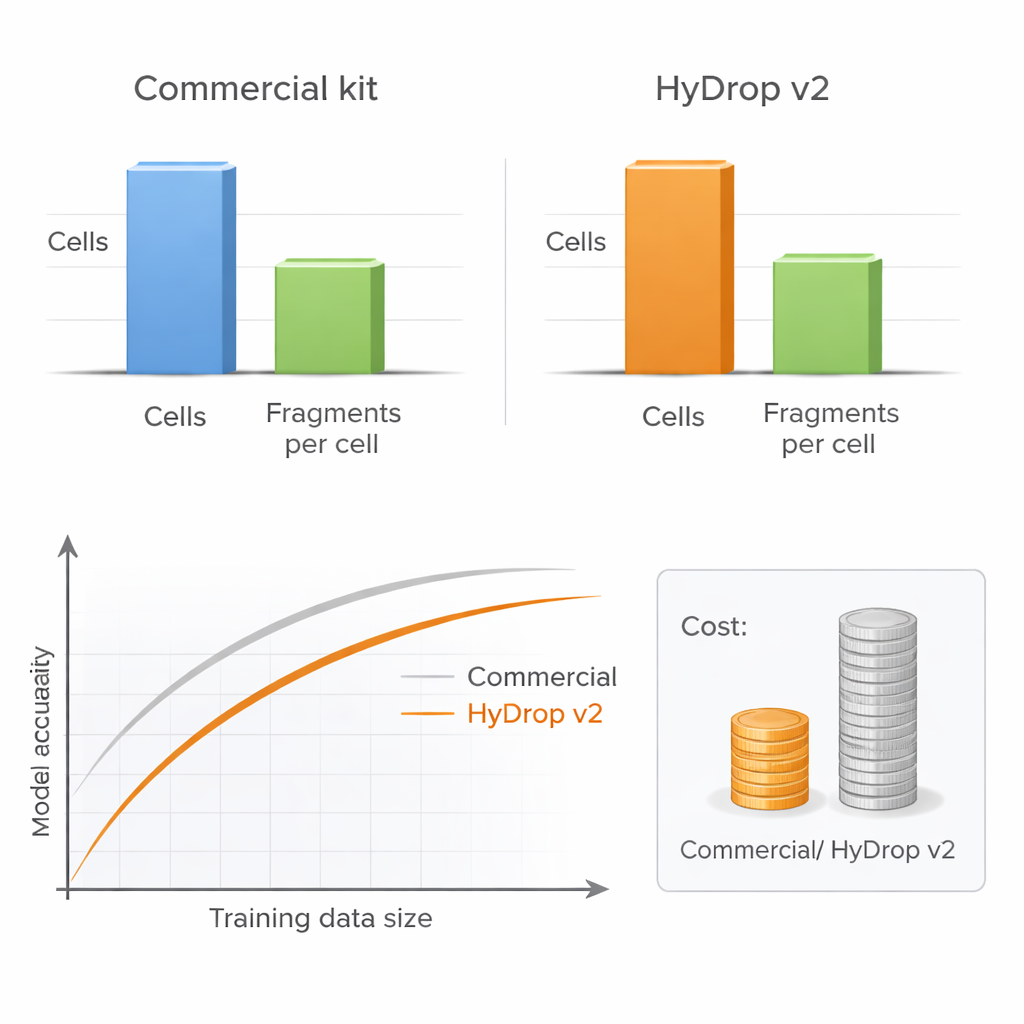
Författarna presenterar HyDrop v2, en förbättrad droppbaserad metod för single‑cell ATAC‑seq som använder specialgjorda hydrogelpärlor för att barkoda individuella celler. De jämför HyDrop v2 med ett allmänt använt kommersiellt kit genom att bygga stora atlaser från två mycket olika system: vuxen mus motorcortex och sent stadium av fruktflugaembryon. HyDrop v2 genererar data av jämförbar kvalitet—återfinner samma huvudsakliga celltyper och mycket liknande uppsättningar av åtkomliga DNA‑regioner—samtidigt som kostnaden per mus hjärnprov är ungefär fjorton gånger lägre. Viktigt är att data från HyDrop v2‑experiment integreras smidigt med kommersiella data, vilket innebär att forskare kan kombinera plattformar när de bygger mycket stora atlaser.
Träna djuplärningsmodeller för att läsa enhancer‑logik
För att testa om billigare data räcker för avancerad modellering tränar teamet sekvens‑till‑funktion djuplärningsmodeller på antingen kommersiella eller HyDrop v2‑atlaser. Dessa modeller lär sig direkt från DNA‑sekvensen att förutsäga hur åtkomlig varje region är i varje celltyp och kan framhäva korta sekvensmönster som sannolikt motsvarar bindningsställen för specifika reglerande proteiner. I muscortex matchar modeller tränade på HyDrop v2‑data modeller baserade på kommersiella data i övergripande noggrannhet och i förmågan att återfinna kända enhancer‑”strömbrytare” som tidigare validerats i levande djur. I fruktflugans embryo stödjer båda plattformarna modeller som kan zooma in på 2 000‑basparsområden och peka ut de centrala ~500‑basparsegmenten som faktiskt driver vävnadsspecifik enhancer‑aktivitet, exempelvis regioner som styr genuttryck i neuroblaster eller muskler.
Fler celler kan slå högre sekvensdjup
En viktig praktisk fråga för alla laboratorier är om man ska sekvensera varje cell mycket djupt eller profilera fler celler med lägre djup. Genom att systematiskt variera antalet celler och antalet DNA‑fragment per cell visar författarna att modellprestandan knappt försämras när sekvensdjupet reduceras till en måttlig nivå, så länge tillräckligt många celler ingår. Däremot skadar en minskning av antalet celler modellens noggrannhet tydligt, särskilt när man mäter prestanda över många celltyper samtidigt. Eftersom HyDrop v2 är mycket billigare per cell kan forskare lätt lägga till tiotusentals extra celler och återfå eller till och med överträffa prestandan hos modellernas som bygger på kommersiella data till en bråkdel av kostnaden.
Att se proteinavtryck på DNA
Studien undersöker också om olika laboratorieplattformar introducerar subtila snedvridningar i hur ATAC‑seq‑enzymet skär DNA, vilket kan vilseleda modeller som försöker sluta sig till var proteiner sitter på genomet. Med ett separat neuralt nätverksverktyg som korrigerar för enzympreferenser visar författarna att HyDrop v2 och kommersiella kit ger nästan identiska mönster av enzymaktivitet i både mus‑ och flugceller. Efter korrigering avslöjar båda dataset fina ”fotavtryck” där reglerande proteiner och nukleosomer verkar skydda DNA från snitt, och dessa fotavtryck överensstämmer med de sekvensmönster som framhävs av sekvens‑till‑funktion‑modellerna. Denna överensstämmelse tyder på att öppna och kommersiella plattformar är lika lämpade för detaljerade studier av hur proteiner interagerar med DNA.
Varför detta spelar roll för att avkoda genomet
För icke‑specialister är huvudbudskapet att vi nu kan bygga mycket stora, prisvärda kartor över hur DNA används i enskilda celler och träna kraftfulla djuplärningsmodeller på dessa kartor utan att vara beroende enbart av kostsam proprietär hårdvara. HyDrop v2 levererar data som stöder förutsägelse av enhancers, tolkning av sekvensmönster och proteinbindande fotavtryck i nivå med ledande kommersiella metoder, förutsatt att tillräckligt många celler profileras. Detta öppnar dörren för att konstruera organismomfattande atlaser över regulatoriska element i hälsa och sjukdom, och påskyndar ansträngningar att läsa genomets regulatoriska instruktioner och att designa nya, precist riktade genetiska strömbrytare för forskning och framtida terapier.
Citering: Dickmänken, H., Wojno, M., Mahieu, L. et al. Evaluating single-cell ATAC-seq atlasing technologies using sequence-to-function modeling. Nat Commun 17, 1951 (2026). https://doi.org/10.1038/s41467-026-68742-4
Nyckelord: single-cell ATAC-seq, enhancers, djuplärningsmodeller, genreglering, öppen källkod genomik