Clear Sky Science · sv
BiG-SCAPE 2.0 och BiG-SLiCE 2.0: skalbar, noggrann och interaktiv sekvensklustring av metaboliska genkluster
Gömda kemiska skatter i mikrobiellt DNA
Många av de läkemedel och växtskyddsmedel vi förlitar oss på kommer från små molekyler som produceras av mikrober. Dessa organismer döljer recepten för sådana molekyler i DNA‑sträckor som kallas genkluster. I takt med att DNA‑sekvensering går framåt dränks forskare i data, men känner fortfarande till bara en liten bråkdel av vad mikrober kan producera. Den här artikeln presenterar BiG-SCAPE 2.0 och BiG-SLiCE 2.0, två uppgraderade programverktyg som hjälper forskare att sålla i enorma genomarkiv för att kartlägga, jämföra och organisera dessa dolda “molekylfabriker”, och därigenom föra nästa generation antibiotika och jordbruksföreningar närmare upptäckt.
Varför genkluster spelar roll för hälsa och jordbruk
Mikrober använder specialiserade små molekyler för att konkurrera, kommunicera och anpassa sig till sin omgivning. DNA‑ritningarna för att producera eller bryta ned dessa molekyler är ofta grupperade i metabola genkluster. Dessa inkluderar biosyntetiska genkluster som bygger komplexa naturprodukter och katabola genkluster som gör det möjligt för mikrober att använda specifika föreningar eller rotutsöndringar som näring. Eftersom gener i ett kluster verkar tillsammans är det att hitta en sådan region i ett genom som att upptäcka en självständig “fabriks‑linje” som kan ge ledtrådar om en molekyls struktur och funktion. Genomgruvningsverktyg upptäcker redan sådana fabriker i bakterier och svampar, men den verkliga utmaningen är att jämföra hundratusentals kluster för att se hur de hänger ihop och vilken kemisk mångfald de kan dölja.
Två motorer för att sortera molekylfabriker
BiG-SCAPE och BiG-SLiCE skapades ursprungligen för att gruppera genkluster med liknande kärnegenskaper i ”genklusterfamiljer”. Varje familj förväntas producera samma eller nära besläktade molekyler. BiG-SCAPE bygger detaljerade nätverk av likheter mellan kluster, medan BiG-SLiCE är inställd för hastighet och kan hantera miljontals kluster genom att omvandla dem till enkla numeriska fingeravtryck och därefter klustra dessa. Tillsammans ligger de till grund för ett växande ekosystem av genomgruvnings‑pipelines, databaser och interaktiva visare som hjälper forskare att navigera mikrobiell kemi i planetär skala.
Vad som är nytt i BiG-SCAPE 2.0
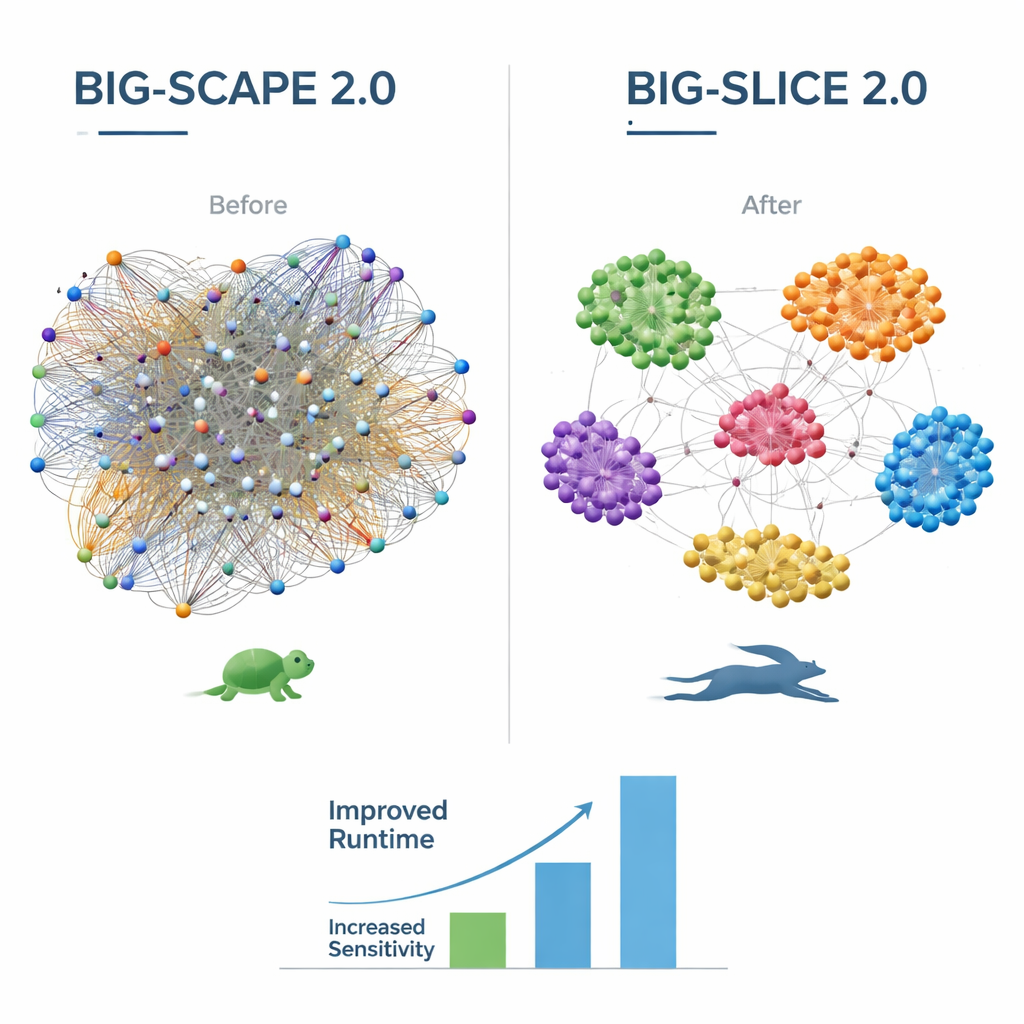
Version 2.0 av BiG-SCAPE inför en rad uppgraderingar med fokus både på biologi och beräkning. Den förstår nu det mer raffinerade ”region”‑begreppet som används av det allmänt använda verktyget antiSMASH, vilket skiljer överlappande eller hybrida genkluster i mindre, mer meningsfulla byggstenar kallade protokluster. Nya aligneringslägen och strategier gör att BiG-SCAPE 2.0 kan fokusera på de verkligt viktiga kärn-generna i varje kluster, vilket ger bättre hantering av omarrangerade gener och diffusa klustergränser. Under huven har kodbasen helt skrivits om för hastighet och hållbarhet, med en delad SQLite‑databas och ett modernt Python‑bibliotek för profilsökningar. Som ett resultat kan BiG-SCAPE 2.0 köra upp till åtta gånger snabbare än sin föregångare, samtidigt som det använder ungefär hälften så mycket minne, och erbjuder nu flera färdiga arbetsflöden för klustring, frågeställningar, deduplicering och benchmarking av genkluster via ett uppgraderat interaktivt webbgränssnitt.
Hur BiG-SLiCE 2.0 hänger med i datamängden
BiG-SLiCE 2.0 fokuserar på att göra mycket stora analyser mer korrekta utan att förlora sitt kännetecken: hastigheten. Tidigare versioner behandlade alla typer av genkluster på samma sätt, vilket oavsiktligt gynnade vissa familjer framför andra. Genom att byta till en kosinusliknande distansmått och uppdatera sitt bibliotek av biosyntetiska proteinsignaturer till senaste standarder grupperar BiG-SLiCE 2.0 nu mycket olika typer av kluster mer balanserat. Kodoptimeringar och övergången till samma snabba profilsökningsbibliotek som BiG-SCAPE ger ytterligare snabbhetsvinster, och nya alternativ att exportera alla resultat som enkla texttabeller gör det lättare att ansluta BiG-SLiCE till andra analysrörledningar. Tester mot nio dataset med manuellt kurerade genfamiljer visar att BiG-SLiCE 2.0:s noggrannhet nu närmar sig BiG-SCAPE, särskilt för kortare och mer svårfångade genkluster.
Att avslöja ett enormt, outnyttjat kemiskt universum
Författarna använde båda verktygen för att undersöka 260 630 biosyntetiska regioner från en offentlig databas över mikrobiella genom. BiG-SCAPE 2.0 och BiG-SLiCE 2.0 gav anmärkningsvärt likartade skattningar av hur många distinkta genklusterfamiljer som finns i detta dataset, vilket stöder tidigare arbeten som visar att endast omkring 3 % av den biosyntetiska potentialen i bakteriegenom hittills har karaktäriserats. Med andra ord återstår majoriteten av mikrobernas kemikalier okända. Genom att göra det möjligt att noggrant klustra och visualisera genkluster över hundratusentals — och så småningom miljontals — genom, ger BiG-SCAPE 2.0 och BiG-SLiCE 2.0 kraftfulla linser för att utforska detta outforskade kemiska universum, och banar väg för nya läkemedel, säkrare växtskyddsmedel och djupare insikter i hur mikrober formar ekosystem och vår egen hälsa.
Citering: Draisma, A., Loureiro, C., Louwen, N.L.L. et al. BiG-SCAPE 2.0 and BiG-SLiCE 2.0: scalable, accurate and interactive sequence clustering of metabolic gene clusters. Nat Commun 17, 2000 (2026). https://doi.org/10.1038/s41467-026-68733-5
Nyckelord: biosyntetiska genkluster, upptäckt av naturprodukter, genomgruvdrift, mikrobiella metaboliter, beräkningsbaserad klustring