Clear Sky Science · sv
Neurala och beräkningsmässiga mekanismer bakom enstaka perceptuella inlärningstillfällen hos människor
Att se den dolda bilden
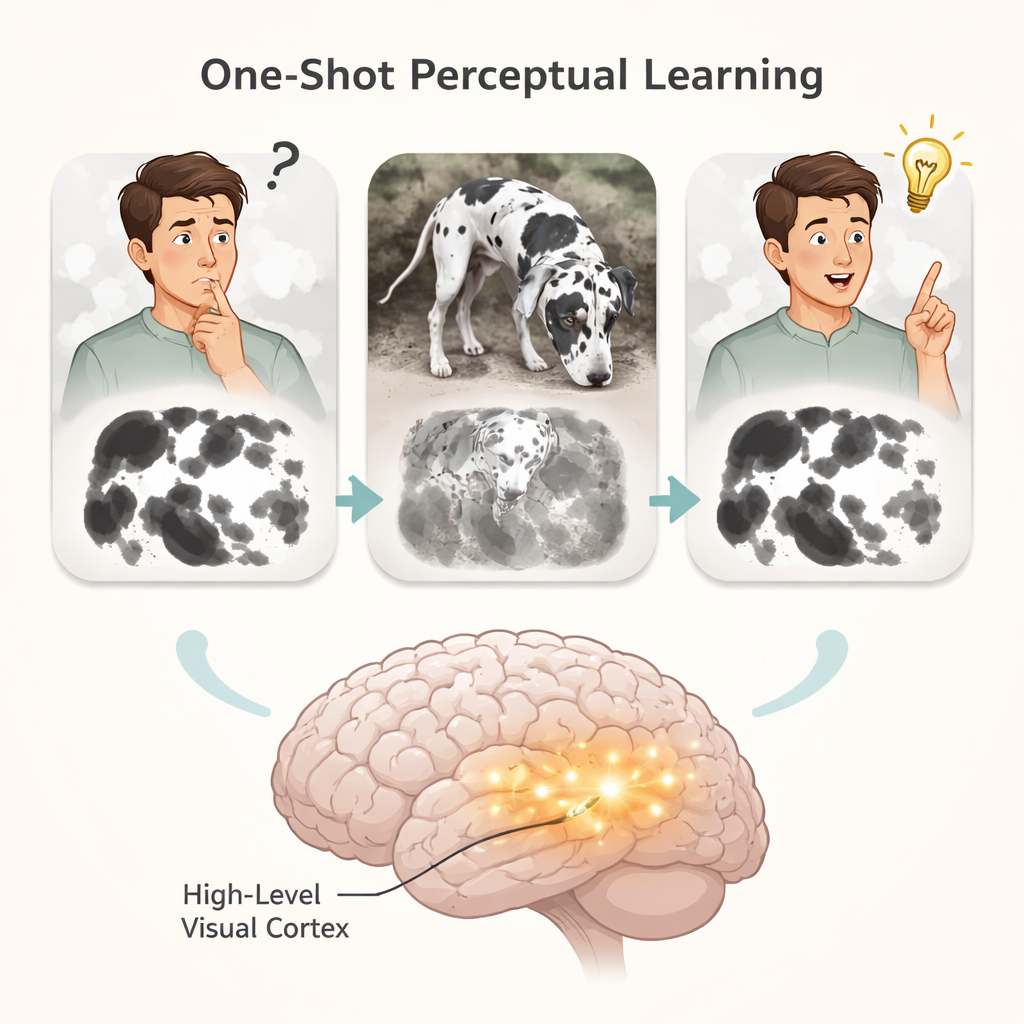
Många har upplevt det plötsliga ”aha!”-ögonblicket när en förvirrande svartvit fläckig bild plötsligt blir en tydlig bild av en hund eller ett ansikte—och när du väl ser den kan du aldrig osse den. Denna studie frågar hur en enda kort glimt av en tydlig bild permanent kan förändra vad vi ser i en grumlig version, och vad det avslöjar om hur våra hjärnor—och framtida artificiella intelligenssystem—lär sig från bara ett exempel.
Från suddiga fläckar till omedelbar igenkänning
Forskarna använde klassiska ”Mooney-bilder”: starkt förenklade svartvita bilder som är svåra att känna igen förrän man ser det ursprungliga gråskalefotot de härstammar från. Försökspersoner försökte först namnge vad de såg i dessa svåra bilder. Senare fick de en kort visning av de matchande tydliga fotona, och försökte sedan igen med de svåra bilderna. Efter den enda exponeringen kunde människor plötsligt känna igen de tidigare mystiska bilderna, och förbättringen bestod. Genom att noggrant förändra de tydliga fotona—spegelvända dem horisontellt, rotera dem, ändra storlek eller flytta dem på skärmen—kartlade teamet vilken typ av visuell information hjärnan faktiskt lagrar under denna enstaka inlärning.
Var i hjärnan den nya insikten lagras
Olika ändringar av bilderna påverkade inlärningen på olika sätt. Att göra den tydliga bilden dubbelt så stor eller hälften så stor skadade inte inlärningen, vilket tyder på att hjärnans lagrade ”mall” är flexibel vad gäller storlek. Men att spegelvända, rotera eller flytta bilden på skärmen försvagade inlärningen, om än inte omöjligt. Att ersätta den tydliga bilden med ett annat exempel från samma kategori—till exempel en annan hund—upphävde inlärningen helt. Det visar att hjärnan inte bara lagrar idén ”det här är en hund”; i stället behåller den ett detaljerat, bildliknande minne av den specifika formen och layouten i just den bilden. Att kombinera dessa beteenderesultat med vad som är känt om det visuella systemet pekade mot högre visuella områden, snarare än tidiga visuella regioner eller minnesstrukturer som hippocampus, som den troliga lagringsplatsen för denna nya kunskap.
Att se inlärningen utspela sig i hjärnan
För att bekräfta detta använde teamet ultrahögfält 7-Tesla MRI-skanningar och direkta inspelningar från elektroder placerade på hjärnorna hos epilepsipatienter. MRI-experimenten visade att neuroner i en region kallad högre visuella cortex reagerade på olika versioner av samma objekt (ändrade i storlek, position eller orientering) precis så som förutsagts utifrån beteendetesterna. I elektrodinspelningarna dök den avgörande förändringen upp först i denna högre visuella cortex: efter inlärning blev aktivitetsmönstren som utlösts av den svåra bilden mer lika dem som utlösts av dess tydliga motpart, och detta skedde tidigare här än i primära visuella områden. Den tidpunkten tyder på att denna region är där den nya ”förhandsinformationen” lagras och återaktiveras, och att den sedan skickar återkoppling ned till tidiga visuella områden för att hjälpa till att tolka tvetydig information.
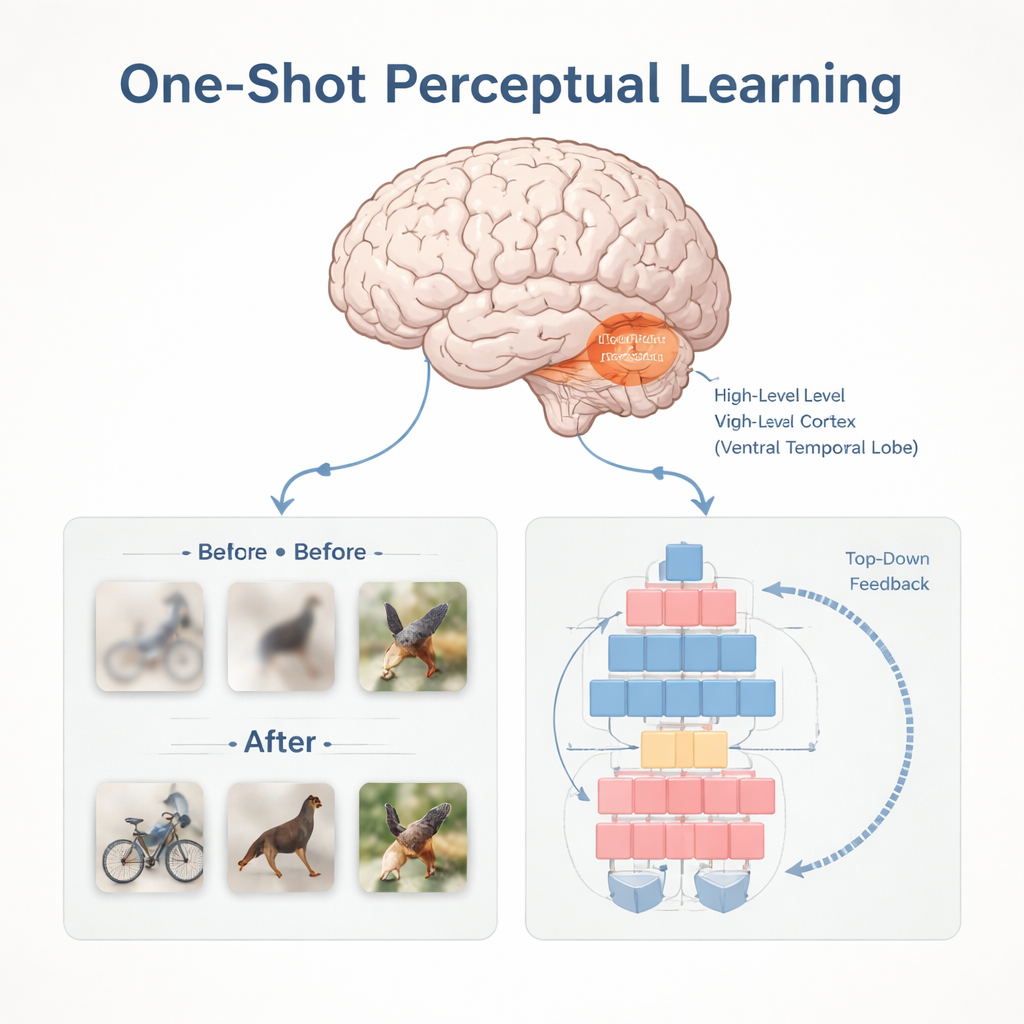
Att bygga en maskin som lär sig på ett försök
Forskarna byggde också en djup neuralt nätverksmodell som var utformad för att efterlikna denna förmåga. Deras system använde en modern vision transformer som en ”bottom-up” visuella motor, ihopkopplad med en särskild modul som lagrar förhandsinformation och skickar ”top-down” återkoppling när den senare ser en relaterad bild. Tränad på Mooney-liknande uppgifter visade modellen verklig enstaka inlärning: dess noggrannhet ökade efter bara en exponering för den tydliga bilden och översteg vida vad som kunde förklaras av enkel repetition. Den delade till och med många av samma framgångar och misslyckanden som mänskliga observatörer på specifika bilder, och de interna funktioner den lärde sig från de tydliga bilderna kunde förutsäga vilka bilder människor skulle lära sig att känna igen eller inte. När teamet jämförde modellens lagrade förhandsinformation med mänskliga hjärnskanningar fann de närmaste överensstämmelserna i samma högre visuella regioner som experimenten pekat ut.
Varför detta är viktigt för hjärnor och maskiner
Tillsammans tyder dessa fynd på att våra plötsliga ”Nu ser jag det!”-ögonblick uppstår när högre visuella områden snabbt justerar sina kopplingar efter en enda upplevelse, och lagrar en detaljerad bildliknande förhandsinformation som senare kan omforma hur vi tolkar brusig information. Denna snabba men stabila form av inlärning, rotad i högre visuella cortex och stödd av top-down-återkoppling, erbjuder en modell för att bygga AI-system som kan lära sig från mycket få exempel. Den ger också en utgångspunkt för att förstå vad som kan gå fel när perception lutar sig för tungt mot förväntningar, som i vissa psykiatriska tillstånd där hallucinationer förekommer.
Citering: Hachisuka, A., Shor, J.D., Liu, X.C. et al. Neural and computational mechanisms underlying one-shot perceptual learning in humans. Nat Commun 17, 1204 (2026). https://doi.org/10.1038/s41467-026-68711-x
Nyckelord: enstaka inlärning, visuell perception, högre visuella cortex, perceptuell inlärning, djupa neurala nätverk